VLM
カテゴリー
タグ
Multimodal AI実践ガイド - 画像・音声・テキストの統合処理
GPT-4oやGemini 2.0の登場により、マルチモーダルAIは新たなステージに進みました。本記事では、クロスモーダル検索や生成、推論といった基本概念から、具体的な実装方法までを実践的に解説します。実践的に解説します。
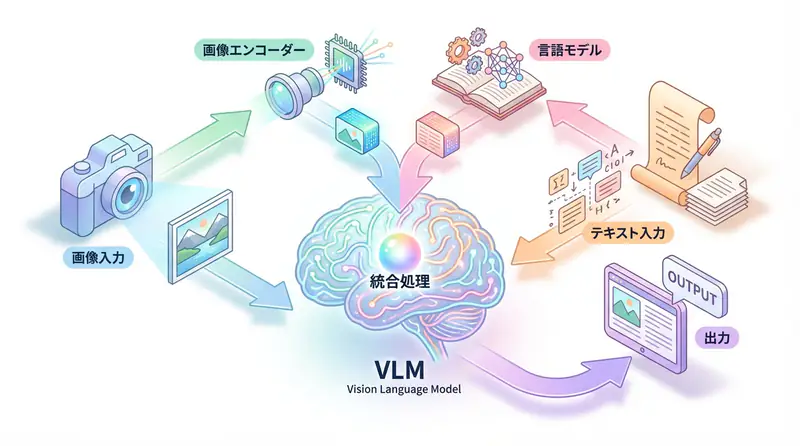
Vision Language Models (VLM) 完全ガイド - 画像を理解するAIの仕組みと実装
GPT-4V、Gemini、Claude等の視覚言語モデル (VLM) の仕組みを徹底解説。アーキテクチャ、主要モデル比較、実装方法、ビジネス活用事例を網羅的に紹介します。実践的に解説します。実践的に解説します。実践的に解説します。実践的に解説します。