推論最適化
カテゴリー
タグ
Mixture of Experts (MoE) 実装ガイド - 効率と性能を両立する次世代LLMアーキテクチャ
LLMの推論コストとメモリ使用量に悩んでいませんか?本記事では、複数の専門家モデルを組み合わせるMixture of Experts (MoE)の仕組みから実装までを、具体的なコード例を交えて実践的に解説します。実践的に解説します。
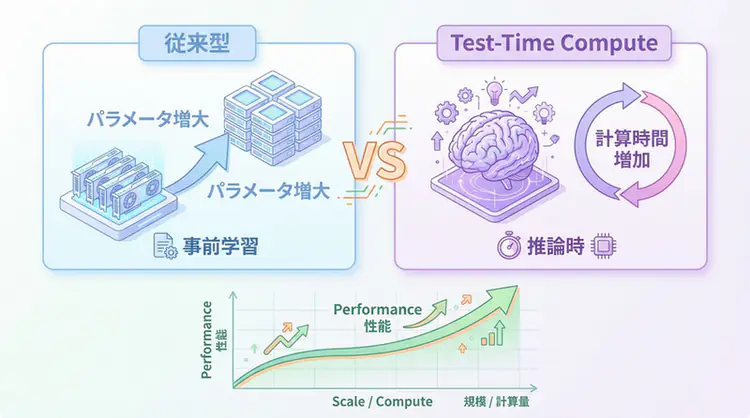
Test-Time Compute (TTC) 徹底解説 - AI推論の「速く、そして深く」考える新時代
OpenAI o1に代表されるTest-Time Compute (TTC) の技術的仕組みを徹底解説。Best-of-N、PRM/ORMによる報酬モデル、適応的計算(Adaptive Computation)の実装パターンまで、AIエンジニアが実務で活用するための完全ガイド。