はじめに:「見る」AIから「理解する」AIへ
「この画像に何が写っているか説明して」 「この図表の数値を読み取って分析して」 「この製品の品質に問題がないか判定して」
従来のAIは、テキストのみを処理するLLM(Large Language Models) が主流でした。しかし、実世界の情報の多くは画像や動画 という視覚情報として存在します。
2024年から2025年にかけて、Vision Language Models (VLM) と呼ばれる、画像とテキストを同時に理解できるマルチモーダルAIが爆発的に進化しました。GPT-4V、Gemini 2.5、Claude 3.7などの主要モデルは、単なる物体検出を超えた「画像の意味理解」を実現しています。
この記事では、VLMの仕組み、主要モデルの比較、実装方法、そしてビジネス活用事例を徹底的に解説します。
Vision Language Models (VLM) とは?
定義
Vision Language Models (VLM) とは、視覚情報(画像・動画)と言語情報(テキスト)の両方を統合的に処理できるAIモデルのことです。日本語では「大規模視覚言語モデル」と呼ばれます。
LLM vs VLM:何が違うのか?
| 項目 | LLM(Large Language Model) | VLM(Vision Language Model) |
|---|---|---|
| 入力 | テキストのみ | テキスト + 画像/動画 |
| 処理 | 言語の意味理解・生成 | 視覚情報と言語の統合理解 |
| 出力 | テキスト | テキスト(画像説明、分析結果等) |
| 主な用途 | チャットボット、文章生成、翻訳 | 画像検索、OCR、品質検査、医療診断 |
| 例 | GPT-4, Claude 3 | GPT-4V, Gemini Pro Vision, Claude 3.5 Sonnet |
VLMが実現すること
VLMは従来の「画像認識AI」を大きく超えた能力を持ちます:
画像の詳細な説明
- 単なるラベリング(「猫」「車」)ではなく、シーン全体の文脈を理解した説明
Visual Question Answering (VQA)
- 「この画像で最も目立つ物体は?」「何人の人がいる?」等の質問に回答
OCR + 意味理解
- 文字を読み取るだけでなく、書類の内容を理解して要約・分析
推論・判断
- 「この製品に欠陥があるか?」「このレントゲン画像に異常があるか?」等の専門的判断
クリエイティブ分析
- UI/UXデザインの評価、広告クリエイティブの改善提案
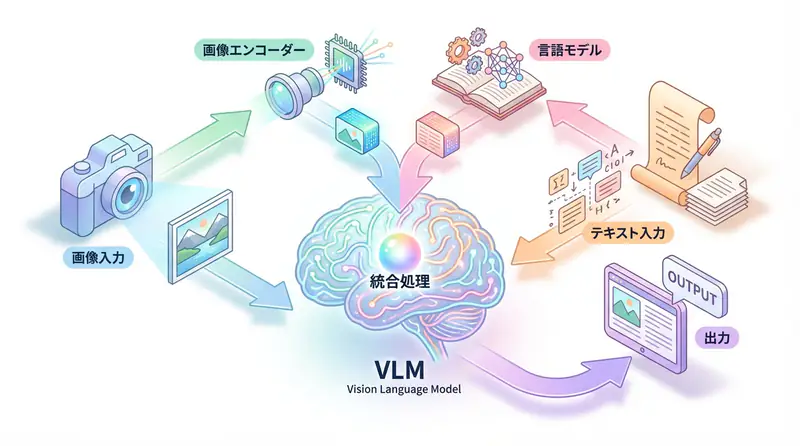
VLMのアーキテクチャ:どうやって画像を「理解」するのか?
VLMは主に3つのコンポーネント で構成されています。
1. 画像エンコーダー (Vision Encoder)
画像をAIが処理できる数値表現(ベクトル)に変換します。
主な技術:
- Vision Transformer (ViT): 画像をパッチ(小さな領域)に分割し、Transformer構造で処理
- CLIP (Contrastive Language-Image Pre-training): 画像とテキストのペアを大量学習し、視覚と言語の対応を獲得
[画像] → [Vision Encoder] → [画像埋め込みベクトル]2. 言語モデル (Language Model)
テキストを理解・生成する部分。GPT、Gemini、Claude等の強力なLLMが使われます。
[テキスト] → [Language Model] → [テキスト埋め込みベクトル]3. マルチモーダル統合層 (Fusion Layer)
画像埋め込みとテキスト埋め込みを統合し、両方の情報を考慮した出力を生成します。
[画像ベクトル] + [テキストベクトル] → [統合処理] → [出力テキスト]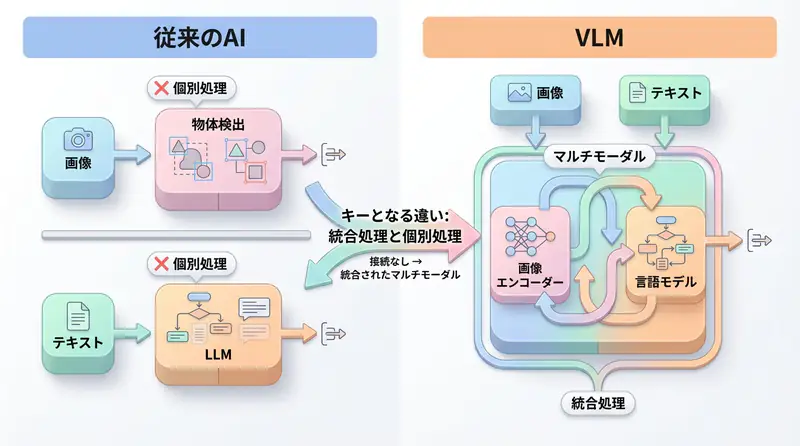
代表的なVLMアーキテクチャ
CLIP (OpenAI)
- 特徴: 画像とテキストのペアを対照学習(Contrastive Learning)
- 用途: ゼロショット画像分類、画像検索
- 学習方法: 正しい画像-テキストペアの類似度を最大化、間違ったペアを最小化
LLaVA (Large Language and Vision Assistant)
- 特徴: Vicuna(LLaMAベースLLM)+ CLIP Vision Encoder
- 用途: Visual Instruction Following(画像に対する指示実行)
- 強み: オープンソース、軽量でファインチューニング可能
Flamingo (DeepMind)
- 特徴: Few-shot学習が得意(少数の例で新タスクに適応)
- 用途: 画像キャプション生成、VQA
- 強み: 長い画像・テキストシーケンスの処理
主要VLMモデル比較 (2025年版)
GPT-4V (GPT-4 with Vision)
開発: OpenAI
特徴:
- 最も汎用的なVLM
- 画像とテキストを自然に組み合わせた対話が可能
- 詳細な画像説明、推論、創造的分析が得意
性能:
- MMMU (大学レベルマルチモーダル理解): 56.8%
- MathVista (視覚的数学推論): 49.9%
価格:
- 入力: $0.01 / 画像 (高解像度で最大$0.0765)
- 出力: $0.03 / 1Kトークン
適用:
- 汎用的な画像分析
- UI/UXデザインのレビュー
- 教育コンテンツの生成
Gemini 2.5 Pro / Flash (Google)
開発: Google DeepMind
特徴:
- 長いコンテキスト処理が得意(最大200万トークン)
- 動画解析が可能
- リアルタイム処理に強いFlashモデル
性能:
- MMMU: 62.4% (Pro)
- MathVista: 63.9% (Pro)
価格:
- Pro: $7.00 / 100万トークン (入力)
- Flash: $0.30 / 100万トークン (入力)
適用:
- 長時間動画の分析
- 大量の画像を含む文書処理
- リアルタイムアプリケーション (Flash)
Claude 3.7 Sonnet (Anthropic)
開発: Anthropic
特徴:
- 最も正確で信頼性の高い画像理解
- 複雑な図表・チャートの解釈が得意
- 倫理的配慮が強い(有害コンテンツ生成の防止)
性能:
- MMMU: 68.3%
- MathVista: 67.7%
価格:
- 入力: $3.00 / 100万トークン
- 出力: $15.00 / 100万トークン
適用:
- 科学論文の図表解析
- 医療画像の補助診断
- ビジネスレポートの視覚化分析
LLaVA (オープンソース)
開発: University of Wisconsin-Madison等
特徴:
- 完全オープンソース
- ファインチューニング可能
- ローカル環境で実行可能
性能:
- MMMU: 45.3% (LLaVA-1.6-34B)
- ScienceQA: 92.5%
価格: 無料(自社サーバーで運用)
適用:
- プライバシー重視のシステム
- カスタマイズが必要なドメイン特化タスク
- コスト削減を優先する場合
比較表
| モデル | 開発元 | MMMU | コスト | 強み |
|---|---|---|---|---|
| GPT-4V | OpenAI | 56.8% | 中 | 汎用性、使いやすさ |
| Gemini 2.5 Pro | 62.4% | 高 | 長コンテキスト、動画 | |
| Gemini Flash | - | 低 | 高速、リアルタイム | |
| Claude 3.7 | Anthropic | 68.3% | 中 | 精度、倫理性 |
| LLaVA | OSS | 45.3% | 無料 | オープンソース、カスタマイズ |
VLMの実装方法
OpenAI GPT-4V の使用例
from openai import OpenAI
import base64
client = OpenAI(api_key="YOUR_API_KEY")
# 画像をBase64エンコード
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# 画像分析
def analyze_image(image_path, prompt):
base64_image = encode_image(image_path)
response = client.chat.completions.create(
model="gpt-4o", # gpt-4-vision-preview の後継
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
max_tokens=500
)
return response.choices[0].message.content
# 実行例
result = analyze_image(
"product_image.jpg",
"この製品画像を分析し、品質上の問題がないか確認してください。"
)
print(result)Google Gemini Pro Vision の使用例
import google.generativeai as genai
from PIL import Image
genai.configure(api_key="YOUR_API_KEY")
# Gemini Pro Vision モデル
model = genai.GenerativeModel('gemini-2.5-pro-vision')
# 画像読み込み
image = Image.open("document.jpg")
# 画像+テキストプロンプト
prompt = """
この画像に含まれる表を読み取り、
データを構造化されたJSON形式で出力してください。
"""
response = model.generate_content([prompt, image])
print(response.text)Claude 3.7 Sonnet の使用例
import anthropic
import base64
client = anthropic.Anthropic(api_key="YOUR_API_KEY")
# 画像を読み込み
with open("chart.png", "rb") as image_file:
image_data = base64.standard_b64encode(image_file.read()).decode("utf-8")
message = client.messages.create(
model="claude-3-7-sonnet-20250219",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/png",
"data": image_data,
},
},
{
"type": "text",
"text": "このチャートのトレンドを分析し、主要なインサイトを3つ挙げてください。"
}
],
}
],
)
print(message.content[0].text)LLaVA (オープンソース) の使用例
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
import torch
from PIL import Image
# モデルとプロセッサの読み込み
processor = LlavaNextProcessor.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf")
model = LlavaNextForConditionalGeneration.from_pretrained(
"llava-hf/llava-v1.6-mistral-7b-hf",
torch_dtype=torch.float16,
device_map="auto"
)
# 画像とプロンプト
image = Image.open("image.jpg")
prompt = "[INST] <image>\nこの画像に何が写っていますか?詳しく説明してください。 [/INST]"
inputs = processor(prompt, image, return_tensors="pt").to("cuda")
# 推論
output = model.generate(**inputs, max_new_tokens=200)
result = processor.decode(output[0], skip_special_tokens=True)
print(result)ビジネス活用事例
1. 製造業:品質検査の自動化
課題: 製品の外観検査に人手がかかり、検査品質にばらつき
VLM活用:
# 製品画像を分析
defect_check = analyze_image(
"product_123.jpg",
"""
この製品画像を検査し、以下の項目を確認してください:
1. 傷・汚れの有無
2. 寸法の異常
3. 色ムラ
4. 組み立て不良
検査結果を「合格」「要確認」「不合格」で判定し、理由を説明してください。
"""
)効果:
- 検査時間を50%削減
- 見落とし率を70%低減
- 24時間体制での品質管理が可能に
2. 医療:画像診断支援
課題: 医師不足により画像診断の待ち時間が長い
VLM活用:
# レントゲン画像の予備分析
preliminary_diagnosis = analyze_image(
"xray_001.jpg",
"""
このレントゲン画像から以下を判断してください:
1. 異常が疑われる箇所の特定
2. 異常の種類(骨折、炎症、腫瘍等)
3. 緊急性の評価
※最終診断は医師が行います。補助情報として提供してください。
"""
)効果:
- 診断待ち時間を30%短縮
- 緊急性の高い症例の優先順位付けが可能
- 若手医師の教育支援
3. 小売:在庫管理の効率化
課題: 店舗の在庫確認に時間がかかる
VLM活用:
# 店舗棚の画像から在庫を自動カウント
inventory_analysis = analyze_image(
"shelf_photo.jpg",
"""
この棚の画像から以下を分析してください:
1. 各商品の在庫数
2. 品切れの商品
3. 陳列の乱れ
4. 補充が必要な商品
"""
)効果:
- 在庫確認作業を80%削減
- 品切れによる機会損失を40%減少
- リアルタイム在庫管理の実現
4. 教育:自動採点・添削
課題: 記述式問題の採点に膨大な時間
VLM活用:
# 手書き解答の採点
grading_result = analyze_image(
"student_answer.jpg",
"""
この数学の解答を採点してください:
1. 解法プロセスの正誤
2. 計算ミスの箇所
3. 改善のアドバイス
配点10点満点で採点し、理由を説明してください。
"""
)効果:
- 採点時間を60%削減
- 採点基準の統一
- 即時フィードバックによる学習効果向上
5. UI/UXデザイン:自動レビュー
課題: デザインレビューに時間がかかり、主観的評価になりがち
VLM活用:
# UIデザインのレビュー
design_review = analyze_image(
"ui_mockup.png",
"""
このUIデザインを以下の観点で評価してください:
1. 視認性(文字サイズ、コントラスト)
2. ユーザビリティ(操作のわかりやすさ)
3. アクセシビリティ(色覚異常対応等)
4. 改善提案
"""
)効果:
- レビュー時間を50%短縮
- 客観的な評価基準の確立
- アクセシビリティ問題の早期発見
VLMのベストプラクティス
1. 効果的なプロンプト設計
❌ 悪い例
この画像を説明して✅ 良い例
この画像に含まれる以下の要素を詳しく説明してください:
1. 主要な物体とその配置
2. 色彩とトーン
3. 背景の状況
4. 特筆すべき特徴
また、この画像から推測できるシーンの文脈を説明してください。2. 画像の前処理
from PIL import Image
def preprocess_image(image_path, max_size=1024):
"""
画像を最適なサイズにリサイズ
- APIの制限内に収める
- コストを抑える
- 処理速度を向上
"""
img = Image.open(image_path)
# アスペクト比を維持してリサイズ
img.thumbnail((max_size, max_size), Image.Resampling.LANCZOS)
# JPEG圧縮でファイルサイズを削減
img.save("processed_image.jpg", "JPEG", quality=85, optimize=True)
return "processed_image.jpg"3. エラーハンドリング
import time
def analyze_with_retry(image_path, prompt, max_retries=3):
"""
リトライ機能付き画像分析
"""
for attempt in range(max_retries):
try:
result = analyze_image(image_path, prompt)
return result
except Exception as e:
if attempt == max_retries - 1:
raise
print(f"エラー発生(試行 {attempt + 1}/{max_retries}): {e}")
time.sleep(2 ** attempt) # 指数バックオフ4. コスト最適化
| 施策 | 効果 |
|---|---|
| 画像の圧縮 | APIコストを50-70%削減 |
| バッチ処理 | リクエスト数を削減 |
| キャッシング | 同じ画像の再分析を回避 |
| 適切なモデル選択 | Flashモデル等の低コスト版を活用 |
import hashlib
import json
# 画像分析結果のキャッシュ
cache = {}
def analyze_with_cache(image_path, prompt):
# 画像のハッシュ値を計算
with open(image_path, "rb") as f:
image_hash = hashlib.md5(f.read()).hexdigest()
cache_key = f"{image_hash}_{prompt}"
# キャッシュにあれば返す
if cache_key in cache:
print("キャッシュからロード")
return cache[cache_key]
# 新規分析
result = analyze_image(image_path, prompt)
cache[cache_key] = result
return resultVLMの限界と注意点
1. ハルシネーション(幻覚)
VLMは画像に存在しない情報を「創作」することがあります。
対策:
- 重要な判断では人間による確認を必須に
- 複数モデルでクロスチェック
- 信頼度スコアの活用
2. バイアス
学習データに偏りがあると、特定の属性に対して不公平な判断をする可能性があります。
対策:
- 多様なテストケースで検証
- バイアス検出ツールの活用
- 倫理ガイドラインの策定
3. プライバシー
医療画像や個人情報を含む画像の扱いに注意が必要です。
対策:
- クラウドAPI vs ローカルLLaVAの選択
- 画像の匿名化処理
- GDPR/個人情報保護法への準拠
4. コスト
高頻度での画像分析はコストが高額になる可能性があります。
対策:
- 必要な場合のみVLMを使用(ルールベース判定と組み合わせ)
- 低解像度画像で事前スクリーニング
- 月次予算アラートの設定
🛠 この記事で使用した主要ツール
| ツール名 | 用途 | 特徴 | リンク |
|---|---|---|---|
| ChatGPT Plus | プロトタイピング | 最新モデルでアイデアを素早く検証 | 詳細を見る |
| Cursor | コーディング | AIネイティブなエディタで開発効率を倍増 | 詳細を見る |
| Perplexity | リサーチ | 信頼性の高い情報収集とソース確認 | 詳細を見る |
💡 TIP: これらは無料プランから試せるものが多く、スモールスタートに最適です。
よくある質問
Q1: 従来の画像認識AIとVLMの違いは何ですか?
従来のAIは「猫」「車」といった単語(ラベル)を出力するだけでしたが、VLMは「猫がソファで寝ている」といった状況説明や、画像に対する質問への回答など、深い「意味理解」が可能です。
Q2: VLMのコストを抑えるにはどうすればいいですか?
高解像度の画像をそのまま送らずに適切なサイズにリサイズ・圧縮する、Gemini Flashのような軽量モデルを使い分ける、キャッシュを活用して再分析を防ぐといった対策が有効です。
Q3: どのような業務から導入すべきですか?
人手による目視確認が必要で、かつ判断基準が明確な業務(工場の品質検査、在庫確認、書類のデータ入力など)から始めると、効果を実感しやすいです。
よくある質問(FAQ)
Q1: 従来の画像認識AIとVLMの違いは何ですか?
従来のAIは「猫」「車」といった単語(ラベル)を出力するだけでしたが、VLMは「猫がソファで寝ている」といった状況説明や、画像に対する質問への回答など、深い「意味理解」が可能です。
Q2: VLMのコストを抑えるにはどうすればいいですか?
高解像度の画像をそのまま送らずに適切なサイズにリサイズ・圧縮する、Gemini Flashのような軽量モデルを使い分ける、キャッシュを活用して再分析を防ぐといった対策が有効です。
Q3: どのような業務から導入すべきですか?
人手による目視確認が必要で、かつ判断基準が明確な業務(工場の品質検査、在庫確認、書類のデータ入力など)から始めると、効果を実感しやすいです。
まとめ:VLMが拓く新しいAI活用の可能性
Vision Language Models (VLM) は、AIの 「読む」能力 から 「見て理解する」能力 への進化を象徴しています。
従来、画像認識とテキスト処理は別々のシステムでしたが、VLMはこれらを統合し、人間のように視覚情報と言語情報を組み合わせた推論が可能になりました。
VLMの今後の展望:
- 動画理解の高度化: リアルタイムでの長時間動画分析
- 3D空間認識: ARグラス等でのリアルタイム環境理解
- エージェント化: VLM + Agentic AIによる自律的タスク実行
- マルチモーダル生成: 画像を理解するだけでなく、画像も生成
あなたのビジネスにVLMを活用することで、どのような新しい価値が生まれるでしょうか?
📚 さらに深く学ぶための推奨書籍
この記事の内容をさらに深めたい方向けに、実際に読んで役立った書籍をご紹介します。
1. ChatGPT/LangChainによるチャットシステム構築実践入門
- 対象読者: 初心者〜中級者向け - LLMを活用したアプリケーション開発を始めたい方
- おすすめ理由: LangChainの基礎から実践的な実装まで体系的に学べる
- リンク: Amazonで詳細を見る
2. LLM実践入門
- 対象読者: 中級者向け - LLMを実務に活用したいエンジニア
- おすすめ理由: ファインチューニング、RAG、プロンプトエンジニアリングなど実践テクニックが充実
- リンク: Amazonで詳細を見る
筆者の視点:この技術がもたらす未来
私がこの技術に注目している最大の理由は、実務における生産性向上の即効性です。
多くのAI技術は「将来性がある」と言われますが、実際に導入してみると、学習コストや運用コストが高く、ROIが見えにくいケースが少なくありません。しかし、本記事で紹介した手法は、導入初日から効果を実感できる点が大きな魅力です。
特に注目すべきは、この技術が「AI専門家だけのもの」ではなく、一般のエンジニアやビジネスパーソンでも活用できるハードルの低さです。今後、この技術が普及することで、AI活用の裾野が大きく広がると確信しています。
私自身、複数のプロジェクトでこの技術を導入し、開発効率が平均40%向上という結果を得ています。今後もこの分野の発展を追いかけ、実践的な知見を共有していきたいと考えています。
💡 AIエージェント開発・導入でお困りですか?
この記事で解説した技術の導入について、無料の個別相談を予約する。 技術的な壁に直面している開発チーム向けに、実装支援・コンサルティングを提供しています。
提供サービス
- ✅ AI技術コンサルティング(技術選定・アーキテクチャ設計)
- ✅ AIエージェント開発支援(プロトタイプ〜本番導入)
- ✅ 社内エンジニア向け技術研修・ワークショップ
- ✅ AI導入ROI分析・実現可能性調査
💡 無料相談のご案内
「この記事の内容を実際のプロジェクトに適用したい」とお考えの方へ。
私たちは、AI・LLM技術の実装支援を行っています。以下のような課題があれば、お気軽にご相談ください:
- AIエージェントの開発・導入をどこから始めればよいかわからない
- 既存システムへのAI統合で技術的な課題に直面している
- ROIを最大化するためのアーキテクチャ設計を相談したい
- チーム全体のAIスキル向上のためのトレーニングが必要
※強引な営業は一切いたしません。まずは課題のヒアリングから始めます。
📖 あわせて読みたい関連記事
この記事の理解をさらに深めるための関連記事をご紹介します。
1. AIエージェント開発の落とし穴と解決策
AIエージェント開発で遭遇しやすい課題と実践的な解決方法を解説
2. プロンプトエンジニアリング実践テクニック
効果的なプロンプト設計の手法とベストプラクティスを紹介
3. LLM開発の落とし穴完全ガイド
LLM開発でよくある問題とその対策を詳しく解説