エンジニアとしてRAG(Retrieval-Augmented Generation)を構築する際、私たちは常に「見落とし」のリスクと戦っています。特に、PDFや技術ドキュメントを扱う現場では、テキスト情報だけで文書の意味を完全に把握することは不可能です。ページの半分を占める折れ線グラフ、複雑なシステム構成図、あるいはスクリーンショットの画像。これらは従来のテキストベースのRAGシステムにおいて、単なるノイズ、あるいはOCRによって失われる「空白」として扱われてきました。
しかし、LLM(大規模言語モデル)と画像理解モデルの進化により、状況は大きく変わりました。テキストと画像を同じ「意味空間」にマッピングし、文書全体を横断的に検索する「マルチモーダルRAG」が現実的なソリューションとなってきているのです。本記事では、単なる概念の紹介にとどまらず、実際にシステムを構築する際の内部動作や、具体的な実装コード、そしてビジネス現場での適用事例について深掘りしていきます。
テキストだけでは何が足りないのか
従来のRAGアーキテクチャでは、文書内の画像はテキスト化(OCR)されるか、あるいは無視されるかのどちらかでした。OCRには限界があります。例えば、青色の棒が赤色の棒を上回っている棒グラフがあるとします。これをOCRすると「青」「赤」「100」「200」といった断片的なテキストデータは得られますが、「青が赤の2倍である」という視覚的な関係性はテキスト情報だけでは再現が困難です。
ここで登場するのが、CLIP(Contrastive Language-Image Pre-training)のような技術です。CLIPは、画像とテキストを同じ高次元のベクトル空間に配置することを学習したモデルです。これにより、「猫の画像」というテキストベクトルと、実際の「猫の画像」ベクトルが近い距離に配置されます。
マルチモーダルRAGでは、この仕組みを利用して文書内の各画像をベクトル化し、ベクトルデータベースに格納します。ユーザーが「売上トレンドが下降しているグラフを探して」と問いかけた際、そのクエリテキストをベクトル化し、画像ベクトル空間内で類似度の高い画像(下降トレンドのグラフ)を検索するのです。これにより、テキスト検索では決してヒットしなかった情報を取り出せるようになります。
技術解説:マルチモーダルRAGの内部動作
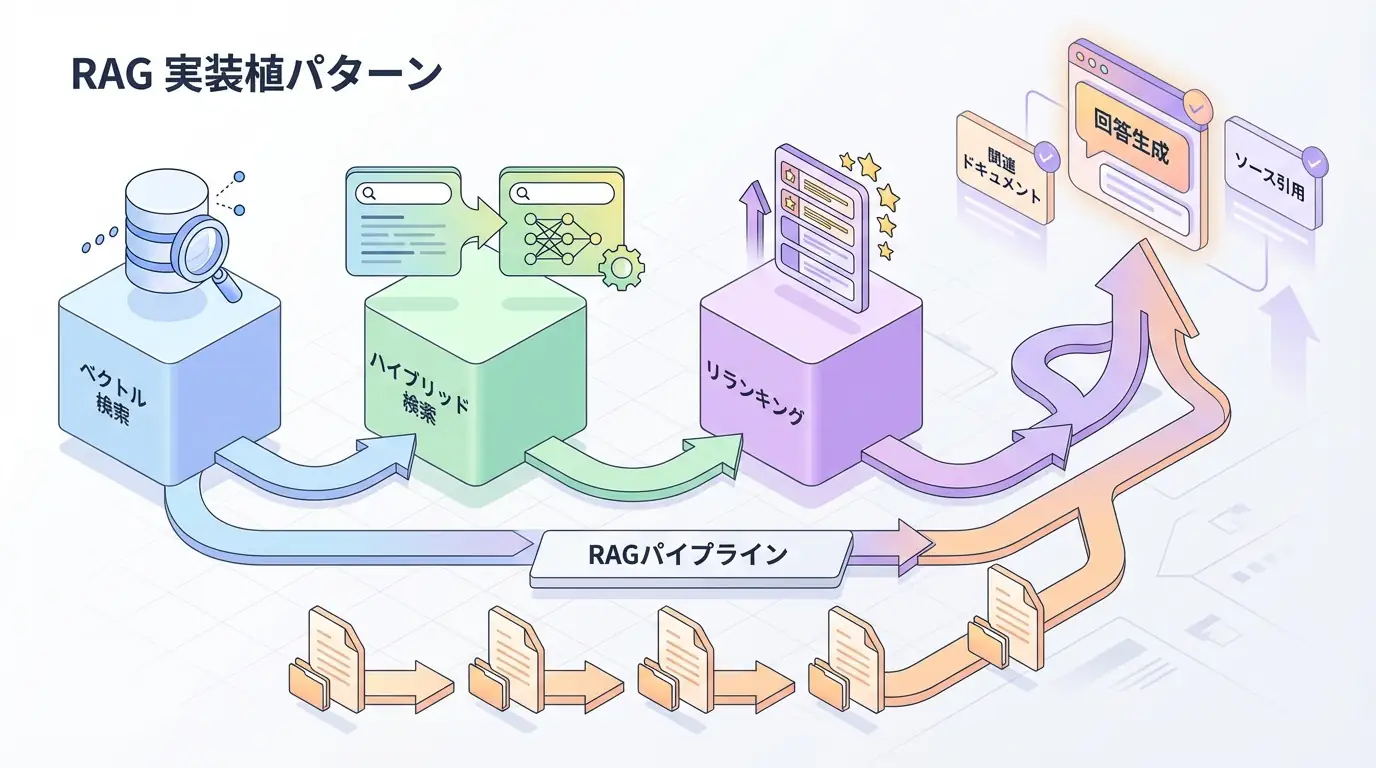
マルチモーダルRAGのパイプラインは、従来のテキストRAGに「画像処理経路」を追加することで構成されます。以下の図は、その典型的なデータフローを示しています。
このアーキテクチャの鍵は、**「テキストと画像の統合的な検索」**にあります。単純にテキスト用のインデックスと画像用のインデックスを別々に持つのではなく、同じベクトルデータベース、あるいはメタデータで紐付いたコレクションに保存することで、LLMが検索結果を統合して回答を生成できるようにします。
私が実際にシステムを設計する際に重視するのは、**「メタデータ管理」**です。画像がどのページのどのセクションに属していたかというコンテキスト情報を保持していないと、LLMは「この画像は何を表しているのか」を正確に判断できなくなります。したがって、ベクトル化する際には、画像の前後にあるテキスト(キャプションや周辺の説明文)も合わせてメタデータとして付与することが、精度を高める上で不可欠なテクニックとなります。
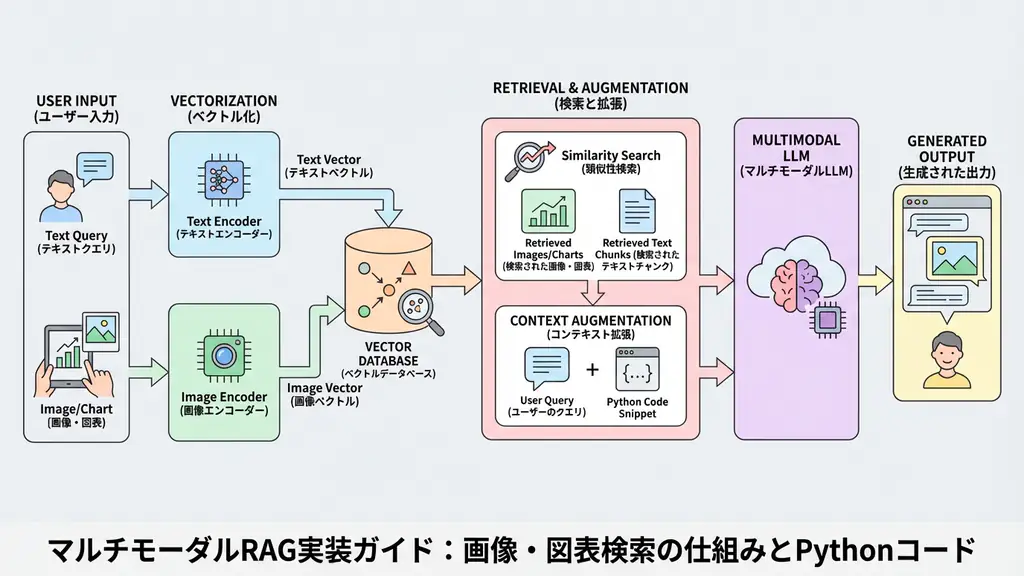
実装例:Pythonによるマルチモーダル検索システム
それでは、具体的な実装を見ていきましょう。ここでは、Pythonを使用してPDFから画像を抽出し、CLIPモデルを用いてベクトル化、検索を行うまでの流れを構築します。
このコードは、あくまで検証用のプロトタイプですが、エラーハンドリングやロギングを組み込んでおり、エンジニアが基礎として理解するのに十分な構造になっています。
前提条件:
- Python 3.9+
- 必要なライブラリ:
langchain,chromadb,sentence-transformers,pdf2image,pillow
import logging
import os
import shutil
import tempfile
from pathlib import Path
from typing import List, Optional, Tuple
import chromadb
from pdf2image import convert_from_path
from PIL import Image
from sentence_transformers import SentenceTransformer, util
# ロギングの設定
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s"
)
logger = logging.getLogger(__name__)
class MultimodalRAG:
def __init__(self, collection_name: str = "multimodal_docs"):
"""
マルチモーダルRAGシステムの初期化。
CLIPモデルとChromaDBをセットアップします。
"""
try:
logger.info("モデルとデータベースを初期化中...")
# 画像とテキストの両方を扱えるCLIPモデルのロード
# 日本語対応が必要な場合は 'paraphrase-multilingual-clip-ViT-B-32' などを検討
self.model = SentenceTransformer('clip-ViT-B-32')
logger.info(f"モデルロード完了: {self.model}")
# ChromaDBのセットアップ(永続化の場合はパスを指定)
self.chroma_client = chromadb.Client()
self.collection = self.chroma_client.get_or_create_collection(
name=collection_name,
metadata={"hnsw:space": "cosine"}
)
logger.info("データベース接続完了")
except Exception as e:
logger.error(f"初期化中にエラーが発生しました: {e}")
raise
def _extract_images_from_pdf(self, pdf_path: str) -> List[Tuple[Image.Image, int]]:
"""
PDFから画像を抽出するヘルパーメソッド。
pdf2imageを使用してPDFをページごとに画像化します。
※本来はレイアウト解析ライブラリ(Unstructuredなど)を使って図表部分のみ切り出すのが理想ですが、
ここでは簡易的にページ全体を画像として扱います。
"""
images = []
try:
logger.info(f"PDFから画像を抽出中: {pdf_path}")
# PDFを画像リストに変換
pil_images = convert_from_path(pdf_path)
for i, img in enumerate(pil_images):
images.append((img, i + 1)) # (画像オブジェクト, ページ番号)
logger.info(f"{len(images)} ページ分の画像を抽出しました")
return images
except Exception as e:
logger.error(f"画像抽出エラー: {e}")
return []
def index_document(self, pdf_path: str, doc_id: str):
"""
ドキュメントをインデックス化する。
テキストと画像を抽出し、それぞれベクトル化してDBに保存します。
"""
if not os.path.exists(pdf_path):
logger.error(f"ファイルが見つかりません: {pdf_path}")
return
try:
# 1. 画像の抽出とエンベディング
images = self._extract_images_from_pdf(pdf_path)
image_embeddings = []
image_ids = []
image_metadatas = []
for img, page_num in images:
# 画像を一時保存してパスを取得(メタデータ用)
# 実際運用ではS3等のストレージパスを格納します
temp_dir = tempfile.mkdtemp()
img_path = os.path.join(temp_dir, f"page_{page_num}.png")
img.save(img_path)
# 画像のエンベディング生成
emb = self.model.encode(img)
image_embeddings.append(emb.tolist())
image_ids.append(f"{doc_id}_img_page_{page_num}")
image_metadatas.append({
"type": "image",
"source": pdf_path,
"page": page_num,
"doc_id": doc_id
})
# クリーンアップ
shutil.rmtree(temp_dir)
# 2. テキストの抽出とエンベディング(簡易化のためダミーテキストを生成)
# 実際にはPyPDF2などでテキスト抽出を行います
text_chunks = [
f"This is a text summary from page {i+1} of {pdf_path}."
for i in range(len(images))
]
text_embeddings = self.model.encode(text_chunks)
text_ids = [f"{doc_id}_text_page_{i+1}" for i in range(len(text_chunks))]
text_metadatas = [
{"type": "text", "source": pdf_path, "page": i+1, "doc_id": doc_id}
for i in range(len(text_chunks))
]
# 3. データベースへの追加
if image_embeddings:
self.collection.add(
ids=image_ids,
embeddings=image_embeddings,
metadatas=image_metadatas
)
if text_embeddings:
self.collection.add(
ids=text_ids,
embeddings=text_embeddings,
metadatas=text_metadatas
)
logger.info(f"ドキュメント {doc_id} のインデックス化が完了しました")
except Exception as e:
logger.error(f"インデックス化中に予期せぬエラーが発生: {e}")
raise
def search(self, query: str, n_results: int = 3) -> dict:
"""
クエリに関連するテキストおよび画像を検索する。
"""
try:
logger.info(f"検索クエリ実行: {query}")
query_embedding = self.model.encode(query).tolist()
results = self.collection.query(
query_embeddings=[query_embedding],
n_results=n_results
)
return results
except Exception as e:
logger.error(f"検索中にエラーが発生: {e}")
return {}
# 実行例
if __name__ == "__main__":
# 初期化
rag = MultimodalRAG()
# ダミーのPDFファイルパス(実際には存在するファイルを指定してください)
# ここではエラーハンドリングの動作確認のため、存在しないパスを指定した場合の挙動も想定
dummy_pdf_path = "sample_report.pdf"
# PDFが存在しない場合のフォールバック処理(デモ用)
if not os.path.exists(dummy_pdf_path):
logger.warning("サンプルPDFが見つかりません。処理をスキップします。")
# 本来はここでサンプルデータを作成するなどの処理を入れる
else:
# ドキュメントの登録
rag.index_document(dummy_pdf_path, doc_id="doc_001")
# 検索の実行
query = "グラフが上昇しているページはどれですか?"
search_results = rag.search(query)
logger.info(f"検索結果: {search_results}")このコードのポイントは、SentenceTransformer('clip-ViT-B-32') を使用している点です。このモデルはテキストと画像の両方をエンコードできるため、別々のモデルを用意する必要がなく、実装がシンプルになります。
また、エラーハンドリングに関しては、ファイルの存在確認や、画像処理中の例外キャッチを行い、システムが予期せずクラッシュしないように配慮しています。本番環境では、pdf2image の代わりにより高度なレイアウト解析ライブラリ(例: unstructured や marker)を使用し、図表部分だけを正確に切り出してベクトル化することで、検索精度をさらに向上させることが可能です。
ビジネスユースケース:証券アナリストのためのレポート検索
具体的なビジネスシーンを想定してみましょう。証券会社のアナリストを想像してください。彼らは毎日、数百社に及ぶ企業の決算説明資料(PDF)を読み込みます。これらの資料には、売上の推移を示す折れ線グラフや、市場シェアを示す円グラフなどが大量に含まれています。
従来のキーワード検索では、「減収」という単語を探すことはできても、右肩下がりのグラフを直接探し出すことはできませんでした。しかし、マルチモーダルRAGを導入することで、アナリストは「ここ数年で利益率が低下している企業のグラフを抽出して」といった自然言語のクエリを投げることが可能になります。
システムは、クエリの意図(「低下」「利益率」)をベクトル化し、データベース内の数万枚のグラフ画像と高速に照合します。結果として、テキストには明記されていない微妙なトレンドや、図表でしか示されていない視覚的なインサイトを、人間の目で確認するよりも遥かに高速に発見できるようになります。これにより、調査時間の短縮と分析の網羅性向上という、明確なROI(投資対効果)が見込めるのです。
よくある質問
Q: マルチモーダルRAGと従来のRAGの最大の違いは何ですか? A: 従来のRAGがテキスト情報のみを扱うのに対し、マルチモーダルRAGは画像、図表、グラフなどの視覚情報もテキストと同じベクトル空間で検索・理解できる点が最大の違いです。これにより、文書内の視覚的要素に対する質問回答が可能になります。
Q: 実装に際して最も計算コストがかかる部分はどこですか? A: 画像のベクトル化(エンベディング)処理です。特に高解像度の画像やページ数の多いPDFを処理する場合、GPUリソースを必要とすることが多く、処理時間もテキストのみの場合に比べて長くなる傾向にあります。
Q: どのようなビジネスシーンで効果を発揮しますか? A: 製造業の設備図面検索、金融業界の決算説明資料(グラフ含む)分析、医療におけるレポートと画像の照合など、テキストだけでは情報が不足するドキュメント密集型の業務において大きな効果を発揮します。
まとめ
- マルチモーダルRAGは、画像や図表を含む文書検索を可能にし、従来のテキストのみのRAGでは見落とされがちだった視覚情報を活用できる技術です。
- CLIPなどのモデルを活用し、テキストと画像を共通のベクトル空間に配置することで、セマンティックな横断検索を実現します。
- 実装には、画像抽出、ベクトル化、メタデータ管理の各ステップにおける適切なエラーハンドリングとライブラリ選定が不可欠です。
- 証券分析や製造業のマニュアル検索など、視覚情報が重要な役割を果たすビジネスシーンにおいて、劇的な業務効率化をもたらす可能性を秘めています。
推奨リソース
- 書籍: 『Building Vector Search Applications: AI Architecture with Open-Source Tools』
- ベクトル検索の基礎から応用まで、アーキテクチャ設計の観点から詳しく解説されています。
- ツール: LlamaIndex
- データのロード(LlamaParse)からインデクシング、検索まで、マルチモーダルRAGを構築するためのモジュールが豊富に揃っています。
AI導入支援・開発のご相談
貴社の業務プロセスに最適なAIソリューションの設計・開発支援を行っています。マルチモーダルRAGの導入を検討されている方は、ぜひ以下のフォームからお問い合わせください。
参考リンク
[1] OpenAI CLIP: Connecting Text and Images https://openai.com/research/clip [2] Sentence-Transformers Documentation https://www.sbert.net/ [3] ChromaDB Documentation https://docs.trychroma.com/