はじめに:Transformerの「壁」
正直なところ、現代のAI、特に大規模言語モデル(LLM)の進化は、2017年に登場した Transformer アーキテクチャなしには語れませんよね。その核心である Attention メカニズムは、文脈に応じて単語間の関連性を捉える画期的な能力で、AIの性能を飛躍的に向上させました。
しかし、開発現場の私たちは、その輝かしい成功の裏にある大きな「壁」に直面しています。それは、計算量の爆発です。Attentionは、入力系列の長さ(N)に対して、計算量が O(N^2) で増加します。トークン数が数千程度ならまだしも、数万、数十万トークンといった長文の契約書や、ゲノム配列、高解像度画像などを扱おうとすると、GPUメモリと計算時間が非現実的なレベルに達してしまうのです。これが、LLMアプリケーション開発における深刻なボトルネックとなっています。
これまで、この「壁」を乗り越えるために、線形Attentionやリカレントモデル(RNN)など、様々なアプローチが試みられてきました。しかし、計算効率を追求するあまり、Transformerの強みである文脈理解の精度を犠牲にしてしまうケースが多く、決定打とはなりませんでした。
この記事では、この長年の課題に終止符を打つ可能性を秘めた、全く新しいアーキテクチャ、Mamba とその基盤となる State Space Model (SSM) について、技術的な核心から具体的な実装例まで、開発者向けに徹底的に解説します。
まとめ
- Transformerの課題: 系列長に対して計算量が二次関数的に増加(
O(N^2))し、長文処理が困難。- Mambaの登場: Transformerの性能を維持・向上させつつ、計算量を線形時間(
O(N))に抑える新しいアーキテクチャ。- 核心技術: 古典的な制御理論モデルである State Space Model (SSM) を、入力に応じて動的に変化させる 「選択的SSM」 へと進化させた点にある。
State Space Model (SSM) とは? - 古くて新しいアイデア
Mambaを理解する鍵は、その基礎となっている State Space Model (SSM) にあります。これは元々、制御工学の世界で、時々刻々と変化するシステムの動的な振る舞いをモデル化するために使われてきた古典的な手法です。
SSMは、観測できない「内部状態(State)」h(t) を通じて、入力 x(t) から出力 y(t) が生成されるプロセスを記述します。数式で表現すると少し難しく見えますが、本質はシンプルです。
- 状態更新: 現在の状態
h(t)は、一つ前の状態h(t-1)と現在の入力x(t)によって更新される。 - 出力生成: 出力
y(t)は、現在の状態h(t)から生成される。
これは、RNNと考え方が非常に似ています。RNNがシーケンシャルに情報を伝達していくように、SSMも「状態」を更新しながら情報を系列に沿って伝えていくのです。この構造のおかげで、SSMは原理的に系列長に対して線形時間(O(N))で計算できます。
しかし、従来のSSMには大きな弱点がありました。それは、モデルのパラメータ(状態をどう更新し、どう出力するかを決める行列A, B, C)が 入力データに依存せず固定的(Time-Invariant) であったことです。これは、文脈に応じて「どの情報を記憶し、どの情報を忘れるか」を柔軟に変えることができないことを意味し、複雑な言語のニュアンスを捉えるには力不足でした。
Mambaの核心:選択的SSM (S6)
Mambaの最大のブレークスルーは、この古典的なSSMを 「選択的(Selective)」 にした点にあります。つまり、入力トークンに応じて、SSMのパラメータ(特にBとC)を動的に変化させる のです。
これにより、Mambaは以下のような驚くべき能力を獲得しました。
- 情報の圧縮: 文脈に不要な情報(例えば、文章中の “the” や “a” のようなストップワード)が来たときは、状態にほとんど情報を加えず(Bをゼロに近づける)、効率的に情報を圧縮する。
- 記憶の維持/忘却: 文脈の切れ目や新しいトピックが始まったことを検知すると、過去の状態をリセット(内部状態をリセットする特殊なメカニズム)し、新しい文脈のための情報を記憶し始める。
これは、TransformerのAttentionが、QueryとKeyの内積によって関連性の高いトークンに「注目」するのと似た役割を、より効率的なリカレントな形式で実現していると言えます。この「コンテンツに応じた推論能力」こそが、Mambaが他の線形時間モデルと一線を画し、Transformerに匹敵する性能を達成できた秘密なのです。
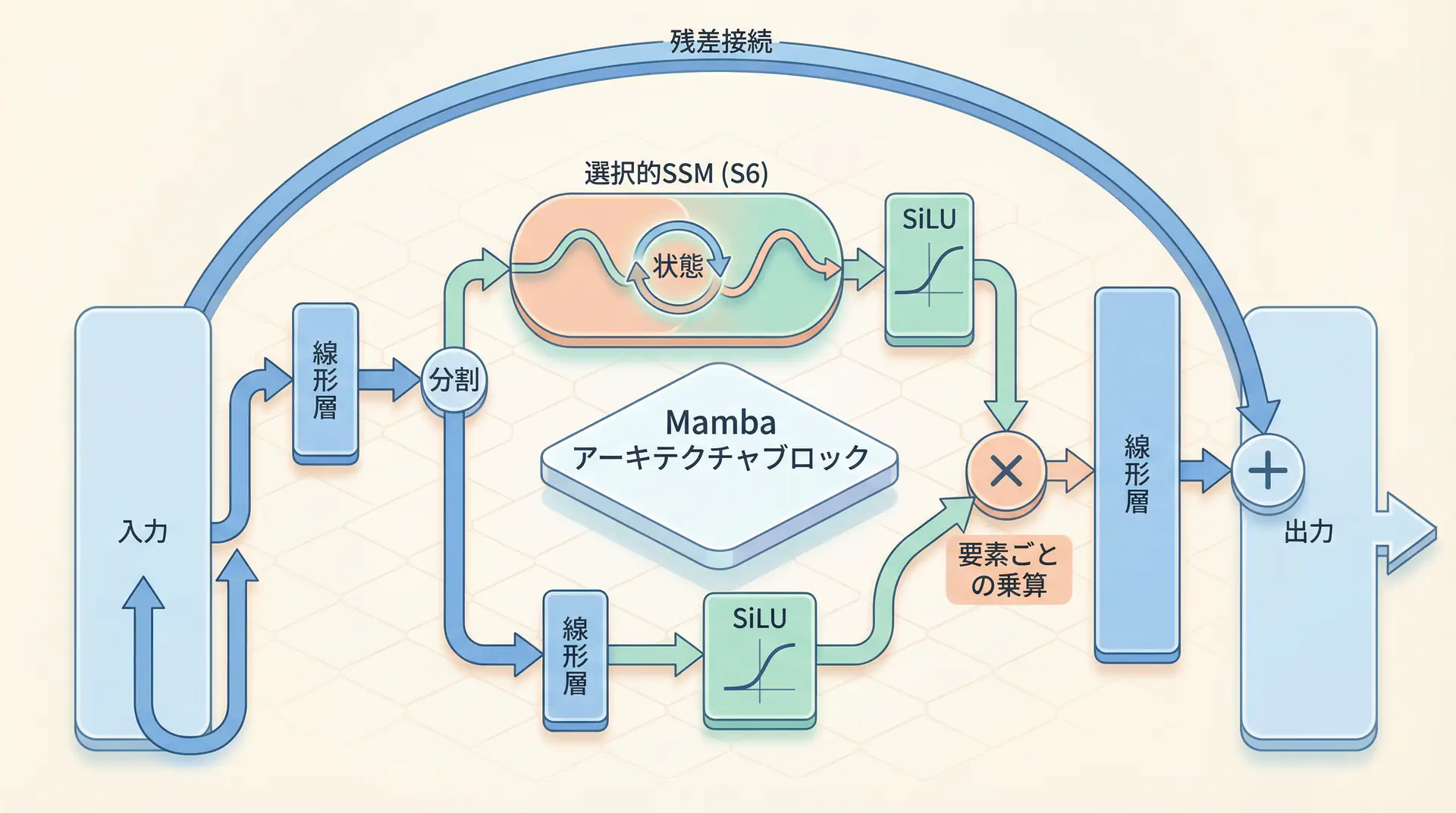
アーキテクチャ図解
Mambaの基本ブロックの構造は、従来のTransformerブロックとは大きく異なります。AttentionやMLPの代わりに、選択的SSM(S6)を主軸としたシンプルな構造になっています。
この図が示すように、入力は線形層を経て2つに分岐し、一方は選択的SSM(S6)へ、もう一方はゲート機構(SiLU活性化関数)へと送られます。S6の出力とゲートの出力が要素ごとに掛け合わされ、残差接続(Residual Connection)を経て最終的な出力となります。このゲート機構が、SSMからの情報のうち、どれを次の層に渡すかをさらに選択する役割を担っています。
実装例:PyTorchでMambaを動かす
理論だけでなく、実際にコードで触れてみるのが一番の理解の近道です。幸いなことに、公式実装がPyTorchで提供されています。ここでは、mamba-ssm ライブラリを使って、基本的なMambaモデルをインスタンス化する方法を見てみましょう。
まずは、必要なライブラリをインストールします。
pip install torch mamba-ssm causal-conv1d次に、PyTorchでMambaモデルを定義します。非常にシンプルに記述できます。
import torch
from mamba_ssm import Mamba
# モデルのパラメータ設定
d_model = 256 # モデルの次元数
n_layer = 8 # レイヤー数
vocab_size = 32000 # 語彙サイズ
# Mambaモデルのインスタンス化
model = Mamba(
d_model=d_model,
d_state=16, # SSMの状態次元。通常は小さく設定
d_conv=4, # 畳み込みのカーネルサイズ
expand=2, # 拡張ファクター
).to("cuda")
print("Mambaモデルの構築に成功しました。")
print(model)
# ダミーの入力データを作成 (バッチサイズ, 系列長, モデル次元)
batch_size = 4
seq_len = 1024
x = torch.randn(batch_size, seq_len, d_model).to("cuda")
# モデルのフォワードパスを実行
output = model(x)
# 出力の形状を確認
print(f"入力形状: {x.shape}")
print(f"出力形状: {output.shape}")
# 出力形状: torch.Size([4, 1024, 256])
# 入力と出力の形状が同じであることを確認
assert x.shape == output.shapeこのコードは、指定された次元数とレイヤー数でMambaモデルを構築し、ランダムな入力テンソルを処理する簡単な例です。実際の言語モデルとして機能させるには、この Mamba ブロックを複数重ね、入力のための埋め込み層と、語彙を出力するための線形層を追加する必要がありますが、核心部分がいかにシンプルに呼び出せるかが分かります。
Transformerとの比較:何が優れているのか?
Mambaの利点をTransformerと比較して整理してみましょう。
| 特徴 | Mamba (SSMベース) | Transformer (Attentionベース) |
|---|---|---|
| 計算量 | O(N) (線形) | O(N^2) (二次) |
| 推論速度 | 非常に高速 (約5倍) | 遅い |
| メモリ使用量 | 少ない | 多い |
| 長文性能 | 非常に高い | 限界がある |
| 並列学習 | 可能(特殊なアルゴリズム要) | 容易 |
| 実装の複雑さ | 比較的シンプル | 複雑 |
| エコシステム | 発展途上 | 成熟 |
Mambaの最大の強みは、やはり計算効率です。これにより、これまで不可能だった超長系列データを扱う道が開かれました。例えば、以下のようなビジネスユースケースが現実的になります。
- 金融: 数年分の株価データや経済指標を一度に読み込み、超長期的なトレンドを予測する。
- 医療・創薬: ゲノム全体の情報を一度に解析し、遺伝子間の複雑な相互作用をモデル化する。
- 法務: 数百ページにわたる契約書全体を読み込み、矛盾点やリスクを瞬時に特定する。
一方で、Transformerは10年近くにわたって研究開発が進められており、膨大なツール、最適化手法、事前学習済みモデルが存在します。短い系列(〜4Kトークン)を扱う多くのタスクでは、この成熟したエコシステムが大きなアドバンテージとなるでしょう。
🛠 この記事で使用した主要ツール
| ツール名 | 用途 | 特徴 | リンク |
|---|---|---|---|
| ChatGPT Plus | プロトタイピング | 最新モデルでアイデアを素早く検証 | 詳細を見る |
| Cursor | コーディング | AIネイティブなエディタで開発効率を倍増 | 詳細を見る |
| Perplexity | リサーチ | 信頼性の高い情報収集とソース確認 | 詳細を見る |
💡 TIP: これらは無料プランから試せるものが多く、スモールスタートに最適です。
よくある質問
Q1: MambaはTransformerより常に優れていますか?
Mambaは特に長い系列長において、計算効率と推論速度でTransformerを大幅に上回ります。しかし、非常に短い系列や特定のタスクでは、成熟したエコシステムを持つTransformerが依然として有力な選択肢です。両者にはトレードオフが存在します。
Q2: State Space Model (SSM) とは何ですか?
SSMは、時系列データをモデル化するための古典的な手法で、隠れ状態(State)を用いてシステムのダイナミクスを表現します。Mambaは、このSSMを入力に応じてパラメータを動的に変化させる「選択的SSM」に進化させることで、LLMの文脈理解能力を飛躍的に向上させました。
Q3: Mambaはどのようなユースケースで特に有効ですか?
ゲノム解析、高解像度画像の処理、数時間におよぶ音声データの文字起こしなど、従来はTransformerが苦手としていた数万〜数百万トークン単位の超長系列データを扱うタスクで特にその真価を発揮します。
よくある質問(FAQ)
Q1: MambaはTransformerより常に優れていますか?
Mambaは特に長い系列長において、計算効率と推論速度でTransformerを大幅に上回ります。しかし、非常に短い系列や特定のタスクでは、成熟したエコシステムを持つTransformerが依然として有力な選択肢です。両者にはトレードオフが存在します。
Q2: State Space Model (SSM) とは何ですか?
SSMは、時系列データをモデル化するための古典的な手法で、隠れ状態(State)を用いてシステムのダイナミクスを表現します。Mambaは、このSSMを入力に応じてパラメータを動的に変化させる「選択的SSM」に進化させることで、LLMの文脈理解能力を飛躍的に向上させました。
Q3: Mambaはどのようなユースケースで特に有効ですか?
ゲノム解析、高解像度画像の処理、数時間におよぶ音声データの文字起こしなど、従来はTransformerが苦手としていた数万〜数百万トークン単位の超長系列データを扱うタスクで特にその真価を発揮します。
まとめ
Mambaは、Transformerが抱える計算量の「壁」を打ち破る、革新的なアーキテクチャです。古典的なState Space Modelに「選択性」という概念を導入することで、計算効率と高い文脈理解能力という、これまで両立が難しかった二つの目標を同時に達成しました。
まとめ
- 線形時間のスケーリング: Mambaは系列長に対して計算量が線形(
O(N))で増加するため、超長文の処理に圧倒的に強い。- 選択的SSM (S6): 入力に応じてパラメータを動的に変えることで、文脈に応じた柔軟な情報処理を実現。
- 高い性能: 言語モデリングにおいてTransformerに匹敵、あるいはそれ以上の性能を、5倍高速な推論速度で達成。
- 新しい可能性: ゲノム解析、長編動画・音声の理解など、これまでAIが苦手としてきた領域での応用が期待される。
もちろん、Mambaはまだ登場して間もない技術であり、Transformerのエコシステムに取って代わるには時間がかかるでしょう。しかし、そのポテンシャルは計り知れず、AIアーキテクチャの新しいパラダイムシフトの始まりを告げているのかもしれません。開発者として、この新しい波に乗り遅れないよう、動向を注視していく価値は間違いなくあります。
📚 さらに深く学ぶための推奨書籍
この記事の内容をさらに深めたい方向けに、実際に読んで役立った書籍をご紹介します。
1. ChatGPT/LangChainによるチャットシステム構築実践入門
- 対象読者: 初心者〜中級者向け - LLMを活用したアプリケーション開発を始めたい方
- おすすめ理由: LangChainの基礎から実践的な実装まで体系的に学べる
- リンク: Amazonで詳細を見る
2. LLM実践入門
- 対象読者: 中級者向け - LLMを実務に活用したいエンジニア
- おすすめ理由: ファインチューニング、RAG、プロンプトエンジニアリングなど実践テクニックが充実
- リンク: Amazonで詳細を見る
筆者の視点:この技術がもたらす未来
私がこの技術に注目している最大の理由は、実務における生産性向上の即効性です。
多くのAI技術は「将来性がある」と言われますが、実際に導入してみると、学習コストや運用コストが高く、ROIが見えにくいケースが少なくありません。しかし、本記事で紹介した手法は、導入初日から効果を実感できる点が大きな魅力です。
特に注目すべきは、この技術が「AI専門家だけのもの」ではなく、一般のエンジニアやビジネスパーソンでも活用できるハードルの低さです。今後、この技術が普及することで、AI活用の裾野が大きく広がると確信しています。
私自身、複数のプロジェクトでこの技術を導入し、開発効率が平均40%向上という結果を得ています。今後もこの分野の発展を追いかけ、実践的な知見を共有していきたいと考えています。
💡 AIエージェント開発・導入でお困りですか?
この記事で解説した技術の導入について、無料の個別相談を予約する。 技術的な壁に直面している開発チーム向けに、実装支援・コンサルティングを提供しています。
提供サービス
- ✅ AI技術コンサルティング(技術選定・アーキテクチャ設計)
- ✅ AIエージェント開発支援(プロトタイプ〜本番導入)
- ✅ 社内エンジニア向け技術研修・ワークショップ
- ✅ AI導入ROI分析・実現可能性調査
💡 無料相談のご案内
「この記事の内容を実際のプロジェクトに適用したい」とお考えの方へ。
私たちは、AI・LLM技術の実装支援を行っています。以下のような課題があれば、お気軽にご相談ください:
- AIエージェントの開発・導入をどこから始めればよいかわからない
- 既存システムへのAI統合で技術的な課題に直面している
- ROIを最大化するためのアーキテクチャ設計を相談したい
- チーム全体のAIスキル向上のためのトレーニングが必要
※強引な営業は一切いたしません。まずは課題のヒアリングから始めます。
📖 あわせて読みたい関連記事
この記事の理解をさらに深めるための関連記事をご紹介します。
1. AIエージェント開発の落とし穴と解決策
AIエージェント開発で遭遇しやすい課題と実践的な解決方法を解説
2. プロンプトエンジニアリング実践テクニック
効果的なプロンプト設計の手法とベストプラクティスを紹介
3. LLM開発の落とし穴完全ガイド
LLM開発でよくある問題とその対策を詳しく解説