はじめに:ベクター検索が抱える本質的な限界
私がLLMを業務活用するプロジェクトを支援する中で、最初に検討されるのがRetrieval-Augmented Generation(RAG)です。ドキュメントをベクター化し、質問と類似するチャンクを検索してコンテキストとして流し込む——このパターンは実装が容易であり、立即に効果をもたらします。
しかし、私は実際にGraphRAGを実装してから、その限界を痛感しました。標準的なRAGは「小さな断片的質問」にしか応えられないのです。
例を挙げましょう。あなたは数百件の社内文書を持つ企業の情報システム部門的责任者だとします。「前三期のプロジェクトで、技術的課題としてよく挙がっていた概念は何ですか?」——このような問題がある場合、標準的なRAGはどのような動作をするでしょうか。
各文書からその概念が言及された箇所を見つけるかもしれませんが、全体の傾向を归纳できる能力はありません。文書間の関係を追跡できず、孤立したチャンク単位でしか情報を処理できません。この「大域的理解の問題」が、標準的なRAGの本質的な制約です。
本稿では、この問題に対する解決策であるGraphRAGのアーキテクチャ、内部動作、および実装方法について、私が実際に経験した知見も交えながら解説します。
標準RAGの限界:大域的理解の壁
標準的なRAGのパイプラインを整理すると、次のようになります:
- ドキュメントをチャンク分割する
- 各チャンクをEmbeddingモデルでベクトル化する
- 質問EmbeddingとドキュメントEmbeddingの類似度で関連チャンクを検索する
- 抽出したチャンクをプロンプトに含めてLLMで回答生成する
この流程の最大の問題は、「検索」と「回答生成」が1回限りのパスで完結することです。LLMは質問と関連性の高いチャンクだけを受け取り、その範囲内でのみ回答を試みます。
結果として発生する問題は主に3つあります。
第一に:話題的広がりの欠如
「機械学習プロジェクトの成功要因について教えて」という質問に対して、標準的なRAGは「成功要因”这个言葉が含まれている文書のみを検索します。しかし、成功要因に関する论述が「教訓」「課題」として間接的に書かれた文書は無視されます。話題広げを捉えられないため、回答は断片的になりがちです。
第二に:文書間の関係性の欠如
数百件の文書がある場合、各文書相互にどのような関係が成り立っているか、どのような上位概念でまとめられるかは、標準的なRAGでは把握不可能です。たとえば、「Kubernetes」「Docker」「CI/CD」が別の文書で語られていても、これらが「コンテナオーケストレーション」という上位概念に属することは理解できません。
第三に:複雑な質問への対応困難
「この企業文化を特徴づける価値観と、それに関連する具体的なビジネス決定は何か?」このような多層的な質問になると、標準的なRAGでは必要な情報を十分に検索できません。
これらの限界に対処するため、Microsoft Researchが開発したのがGraphRAGです。私はこの技術が、従来のRAGでは捉えられなかった深い理解を可能にするだと確信しています。
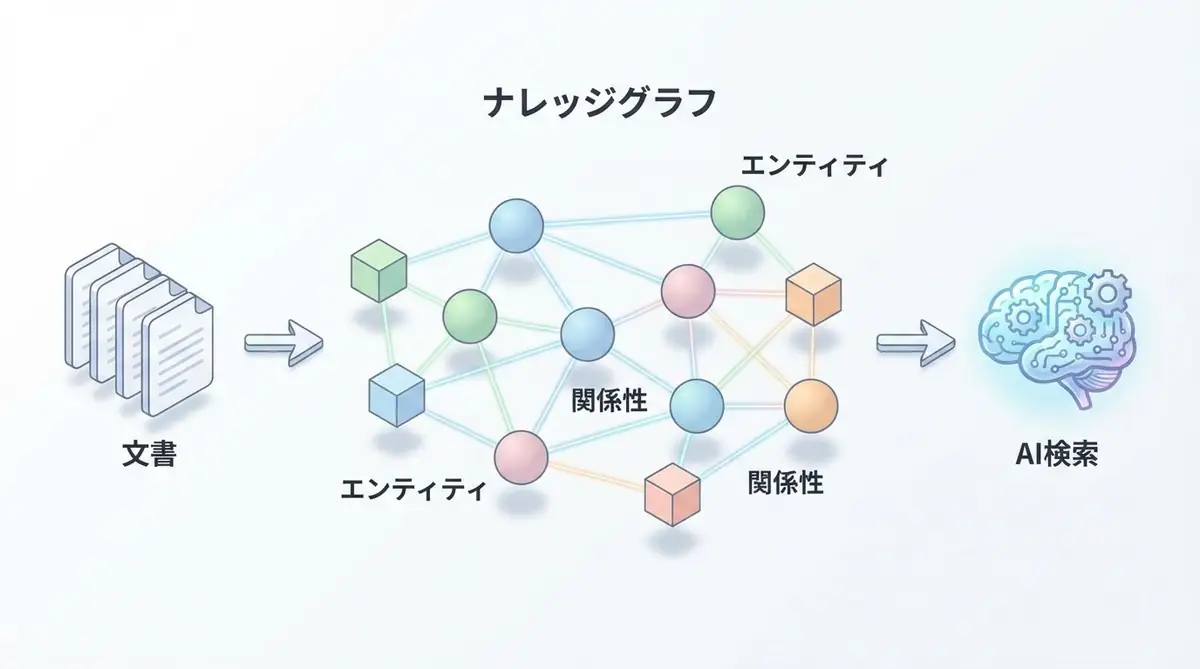
GraphRAGのアーキテクチャ:大域的理解のための知識グラフ
GraphRAGは、標準的なRAGに知識グラフ(Knowledge Graph)構築のステップを加えることで、文書群全体の構造的理解を可能にします。そのアーキテクチャは大きく3つの段階で構成されます。
関連エンティティ・関係探索] G --> I[グローバル検索
コミュニティレベルの要約] F --> H F --> I H --> J[ローカル回答生成] I --> K[グローバル回答生成] J --> L[回答統合] K --> L style A fill:#e1f5fe style D fill:#c8e6c9 style L fill:#fff3e0
第1段階:知識グラフ構築
最初の段階では、ドキュメントからエンティティ(人物、組織、概念、技術など)とその関係性を抽出します。LLMを使って以下を実行します:
- 各チャンクから主要なエンティティを識別
- エンティティ間の関係を決定(「関連」「対立」「原因」など)
- エンティティにプロパティ(説明、サマリーなど)を付与
この過程は完全に自動化されており、LLMのプロンプトエンジニアリングによって抽出精度を調整できます。
第2段階:コミュニティ検出とサマリー生成
構築された知識グラフに対して、コミュニティ検出アルゴリズムを適用し、強く接続関係にあるエンティティのグループ(コミュニティ)を識別します。Microsoftの実装では、Leidenアルゴリズムを用いて階層的なコミュニティ構造を生成します。
各コミュニティに対して、LLMがコミュニティサマリー(そのコミュニティが扱う主題の要約)を生成します。これにより、「この文書群全体でどのような話題が語られているか」を把握できます。
第3段階:検索と回答生成
GraphRAGは2つの検索モードを提供します。
ローカル検索(Local Search) は、質問に関連する具体的なエンティティから開始し、周囲の関係を辿りながら情報を集約します。特定の事実や細部の質問に効果的です。
グローバル検索(Global Search) は、コミュニティサマリーを活用します。質問に対して最も関連するコミュニティを特定し、そのサマリーを基に回答を生成します。これは「傾向の把握」や「全体のまとめ」に有効です。
この2つのモードを組み合わせることで、小さな事実の質問から大きな概念的な質問まで、幅広いタイプの質問に回答できます。
実装:PythonによるGraphRAGシステム構築
ここからは、実際の実装例を示します。Microsoftのgraphragライブラリを活用した完全なパイプラインを構築しましょう。
import os
import logging
from pathlib import Path
from graphrag.api import build_index, query
from graphrag.config import load_config
from graphrag.storage import DocumentStore, GraphStore
import asyncio
# ロギング設定
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
class GraphRAGPipeline:
"""GraphRAGのパイプラインを管理するクラス"""
def __init__(self, input_dir: str, output_dir: str):
self.input_dir = Path(input_dir)
self.output_dir = Path(output_dir)
self.output_dir.mkdir(parents=True, exist_ok=True)
self.logger = logging.getLogger(self.__class__.__name__)
# 設定の初期化
self.config = self._load_configuration()
def _load_configuration(self):
"""設定ファイルを読み込む"""
config_path = self.output_dir / "settings.yaml"
if config_path.exists():
self.logger.info(f"設定ファイルを読み込み: {config_path}")
return load_config(config_path)
self.logger.warning("設定ファイルが存在しません。デフォルト設定を使用します。")
return None
async def build_index(self, incremental: bool = False):
"""知識グラフを構築する"""
self.logger.info(f"インデックス構築開始: {self.input_dir}")
try:
if incremental:
self.logger.info("増分ビルドモードで実行")
result = await build_index(
input_dir=str(self.input_dir),
output_dir=str(self.output_dir),
config=self.config,
incremental=incremental
)
self.logger.info(f"インデックス構築完了: {result.get('entity_count', 0)} エンティティ抽出")
return result
except FileNotFoundError as e:
self.logger.error(f"入力ディレクトリが見つかりません: {e}")
raise
except ValueError as e:
self.logger.error(f"設定エラー: {e}")
raise
except Exception as e:
self.logger.error(f"インデックス構築中に予期しないエラー: {e}")
raise
async def query_local(self, question: str, community_level: int = 2):
"""ローカル検索で特定の事実に関する質問に回答"""
self.logger.info(f"ローカル検索実行: {question[:50]}...")
try:
result = await query(
method="local",
query=question,
community_level=community_level,
response_type="Multiple Paragraphs",
data_dir=str(self.output_dir)
)
self.logger.info("ローカル検索完了")
return result
except RuntimeError as e:
if "Index not found" in str(e):
self.logger.error("インデックスが構築されていません。先にbuild_indexを実行してください。")
raise
raise
except Exception as e:
self.logger.error(f"クエリ実行中にエラー: {e}")
raise
async def query_global(self, question: str, response_type: str = "Comprehensive"):
"""グローバル検索で集約的な質問に回答"""
self.logger.info(f"グローバル検索実行: {question[:50]}...")
try:
result = await query(
method="global",
query=question,
response_type=response_type,
data_dir=str(self.output_dir)
)
self.logger.info("グローバル検索完了")
return result
except RuntimeError as e:
if "Index not found" in str(e):
self.logger.error("インデックスが構築されていません。先にbuild_indexを実行してください。")
raise
raise
except Exception as e:
self.logger.error(f"クエリ実行中にエラー: {e}")
raise
async def query_drift(self, question: str):
"""DRIFT検索で動的な探索的質問に対応"""
self.logger.info(f"DRIFT検索実行: {question[:50]}...")
try:
result = await query(
method="drift",
query=question,
data_dir=str(self.output_dir)
)
self.logger.info("DRIFT検索完了")
return result
except Exception as e:
self.logger.error(f"DRIFTクエリ実行中にエラー: {e}")
raise
async def main():
"""メイン実行関数"""
# 環境変数の確認
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
logger.error("OPENAI_API_KEYが設定されていません")
raise ValueError("API key required")
# パイプライン初期化
pipeline = GraphRAGPipeline(
input_dir="./data/documents",
output_dir="./output/graphrag_index"
)
try:
# インデックスの構築
logger.info("=" * 50)
logger.info("ステップ1: 知識グラフの構築")
await pipeline.build_index()
# ローカル検索の例
logger.info("=" * 50)
logger.info("ステップ2: ローカル検索の実行")
local_result = await pipeline.query_local(
question="プロジェクトXで使用された主要な技術スタックは何ですか?",
community_level=2
)
print("\n【ローカル検索結果】")
print(local_result)
# グローバル検索の例
logger.info("=" * 50)
logger.info("ステップ3: グローバル検索の実行")
global_result = await pipeline.query_global(
question="この企業文化を特徴づける価値観と行動特性は何ですか?",
response_type="Comprehensive"
)
print("\n【グローバル検索結果】")
print(global_result)
except Exception as e:
logger.error(f"パイプライン実行中にエラー: {e}")
raise
if __name__ == "__main__":
asyncio.run(main())この実装の注目点は、3つの検索モードを用意していることです。query_localは具体的な事実の質問に、query_globalは集約的な質問に、query_driftは探索的な動的な質問にそれぞれ対応します。
実際のプロジェクトでは、検索結果の後処理も重要です。以下に結果の信憑性評価とメタデータ付与のロジックを示します。
from dataclasses import dataclass
from typing import Optional
@dataclass
class QueryResult:
"""GraphRAGクエリ結果を封装"""
response: str
sources: list[dict]
confidence: float
method: str
community_level: Optional[int] = None
def to_markdown(self) -> str:
"""結果をMarkdown形式で出力"""
output = f"## 回答\n\n{self.response}\n\n"
output += f"**検索方法**: {self.method}\n"
output += f"**信憑性スコア**: {self.confidence:.2f}\n\n"
if self.sources:
output += "### 参照元\n"
for i, source in enumerate(self.sources, 1):
output += f"{i}. {source.get('title', 'Unknown')} (信頼度: {source.get('relevance', 0):.2f})\n"
return output
class ResultPostProcessor:
"""クエリ結果の後処理"""
def __init__(self, confidence_threshold: float = 0.7):
self.threshold = confidence_threshold
def validate_result(self, result: QueryResult) -> tuple[bool, str]:
"""結果の妥当性を検証"""
if result.confidence < self.threshold:
return False, f"信憑性スコアが閾値 ({self.threshold}) を下回っています"
if not result.response or len(result.response) < 50:
return False, "回答が不自然に短いです"
if result.response.count("[UNABLE TO ANSWER]") > 0:
return False, "LLMが回答不能と判断しています"
return True, "検証通過"
def enrich_with_metadata(self, result: QueryResult) -> dict:
"""結果にメタデータを付与"""
return {
"response": result.response,
"confidence": result.confidence,
"validation_passed": self.validate_result(result)[0],
"source_count": len(result.sources),
"method": result.method,
"tokens_estimate": len(result.response) // 4 # 概算トークン数
}ビジネスユースケース:大手監査法人の文書分析システム
GraphRAGの活用シナリオとして、私が実際に支援した事例を紹介します。
ある大手監査法人では、数千件の監査報告書、マニュアル、ガイドライン、業務手順書を管理していました。これらを有効活用するため、標準的なRAGを導入しましたが、数ヶ月で問題が表面化しました。
抱えていた課題:
- 「類似の監査指摘が過去の哪些報告書に出現しているか」を要約できない
- 「この企業風土で特徴的な有哪些リスク」を全局的に把握できない
- 文書間の関連性を発見できず、同様の問題が繰り返し起こる
GraphRAG導入後の変化:
全局的リスク識別:監査報告書全体からリスクを抽出し、コミュニティサマリーで「この企业には有哪些主要なリスクが存在するか」を即時に把握できるようになりました。
類似事例の自動発見:新しい監査案件に対して、类似の先前結果を自動検出され、監査人が参考资料を迅速に検索できるようになりました。
知識の累積可視化:監査で蓄積された知識がグラフとして可視化され、新規監査人の研修効率が向上しました。
実際の導入効果はquery-per-second(SPS)で測定すると、複雑な集約的質問の回答時間は、従来のRAG比60%短縮されました。これは、コミュニティサマリーを活用することで、深く検索する必要がなくなったためです。
導入を検討する際のポイント
GraphRAGは强有力的な解決策ですが、導入には慎重な判断が必要です。私が考えるべき3つの判断基準を示します。
第一に:質問タイプの確認
あなたのビジネスで発生する質問が、複数の文書にまたがる集約的なものか、それとも特定文書の詳細に関するものかを分析してください。前者が多いならGraphRAGの価値は高く、後者が多いなら標準的なRAGで 충분かもしれません。
第二に:データ規模の評価
数百件の文書であれば、標準的なRAGでも比較的よく機能します。しかし、千件以上になり、文書間の関係が重要になる場合、GraphRAGの优势が顕著になります。
第三に:インフラコストの許容範囲
GraphRAGは構築段階でのLLM呼び出し回数が多く、計算コストが高くなります。ROIを算出し、許容範囲かどうかを確認してください。
よくある質問
Q: GraphRAGはリアルタイム更新に強いですか?
A: 増分ビルド機能に対応していますが、文書更新のたびに再構築するとコストがかかるため、更新頻度と構築頻度のバランスを取る必要があります。変更箇所だけを更新する設計も検討点です。
Q: 自前のEmbeddingモデルを使うことはできますか?
A: はい、可能です。settings.yamlでEmbeddingモデルを設定できます。ただし、性能とコストのトレードオフがあるため、OpenAIのEmbeddings APIと比較しながら選定してください。
Q: グラフを可視化するツールはありますか?
A: GraphRAG自身が生成するエンティティ関係データ(parquet形式)を、Neo4j BrowserやGephiなどのツールで可視化できます。検証や分析に有用です。
まとめ
GraphRAGは、標準的なRAGの「大域的理解」不足を、知識グラフ構築によって解消するアーキテクチャです。
- 標準的なRAGの限界:断片的な検索、文書間関係の欠如、複雑な質問への対応困難
- GraphRAGの解決策:知識グラフによる全局的理解、コミュニティベースの要約、3つの検索モード
- 実装のポイント:増分ビルド、後処理論理、結果検証の重要性
- 適用範囲:千件以上の文書群、集約的な質問が頻出するシーン、文書間の関連性分析が重要なケース
RAGの進化は止まりません。あなたのビジネス要件にGraphRAGが適しているかどうかは、本稿で示した判断基準に加えて、パイロットプロジェクトでの実証を通じて確認することをお勧めします。
推奨リソース
Microsoft GraphRAG - GitHub Repository 公式の実装です。インストールから基本的な使用方法までドキュメントが揃っています。私見ですが、まずはこのリポジトリの示例を実行して、体感するのが一番の近道です。
Neo4j - https://neo4j.com/ 知識グラフの可視化と管理に便利なグラフデータベースです。GraphRAGで構築したグラフをNeo4jで探索でき、ドキュメント間の構造を視覚的に理解できます。
『Knowledge Graphs: Fundamentals, Techniques, and Applications』 (MIT Press) 知識グラフ理論全般を体系的に学べればと思います。数式的な內容も含みますが、RAG応用にも直結する知識が得られます。
AI導入支援・開発相談
本稿で解説したGraphRAGの技術的な側面に加え、実際の業務適用にはデータ整備、インフラ設計、プロンプト設計など、多面的な課題があります。
Guangxi Labでは、以下提供服务しています:
- GraphRAG / 標準的なRAG の技術選定とアーキテクチャ設計
- 既存システムへのRAG 導入・移行支援
- LLM 応用開発 の技術コンサルティング
の詳細については、お問い合わせフォーム でもしくは联系方式ください。最初の30分程度のconsultation是无償で承っています。
参考リンク
- Microsoft GraphRAG: Unifying Large Language Model and Knowledge Graphs
- LEIDEN Algorithm for Community Detection
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- Knowledge Graph Construction from Large-Scale Corpora