はじめに
2025年、AI Coding Agentsは単なる「コード補完ツール」から、要件定義から実装、テストまでを自律的にこなす「開発パートナー」へと進化を遂げました。しかし、その強力な能力を実際の開発現場で最大限に引き出すには、特有の課題が伴います。
「どうやって巨大なコードベースをAIに理解させればいいんだ?」「生成されたコードの品質が信用できない」「セキュリティは大丈夫なのか?」
私自身、多くのプロジェクトでAI Coding Agentsを導入する中で、このような壁に何度もぶつかってきました。本記事は、そうした実践から得られた知見を基に、開発現場で直面する5つの具体的な課題と、それらを解決するための実装パターンを、コード例を交えながら徹底的に解説するものです。
単なるツールの紹介ではなく、AIを真の戦力として活用するための、より一歩踏み込んだガイドを目指します。
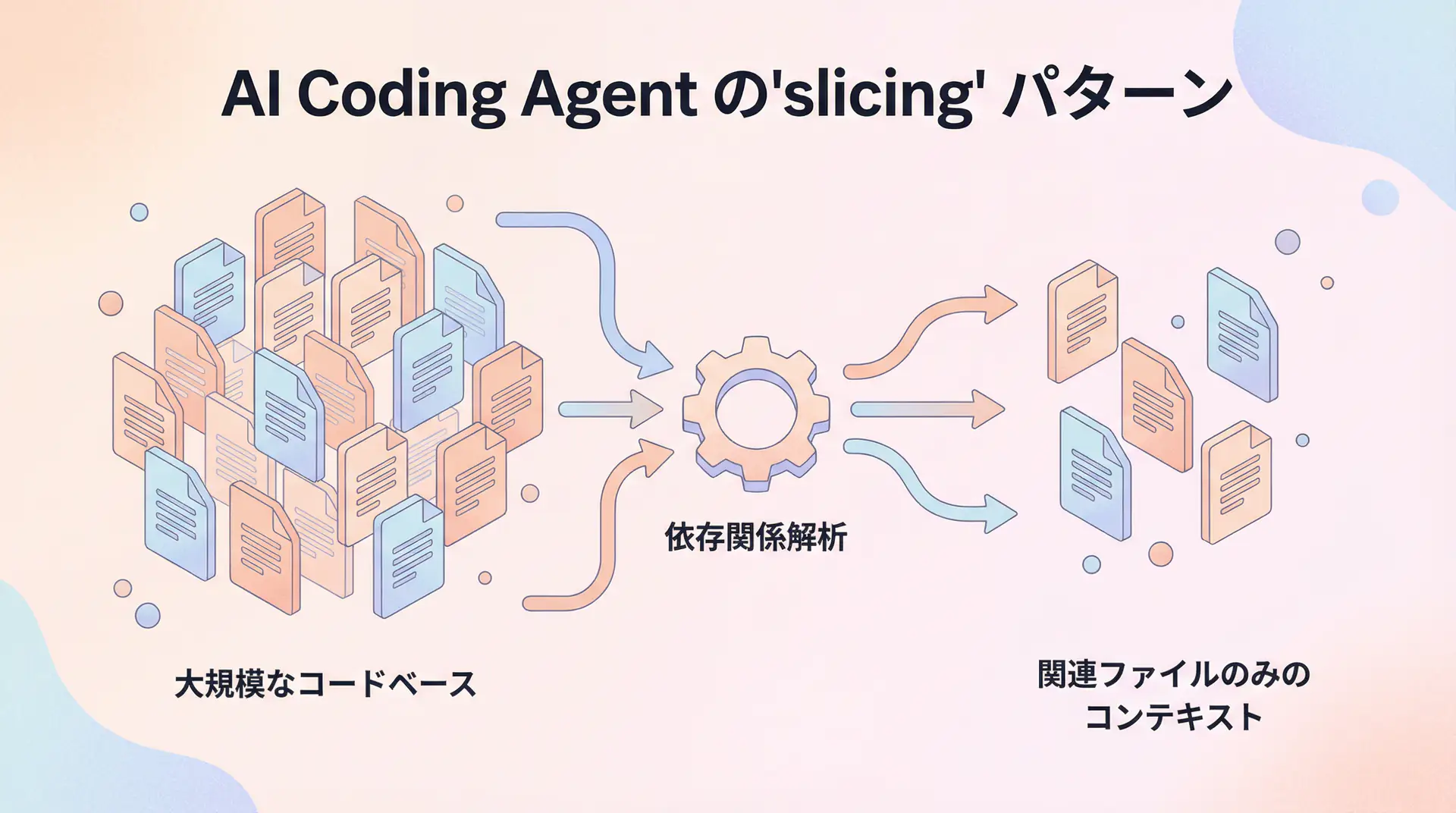
課題1: コンテキスト管理の限界と「スライシング」パターン
AI Coding Agentsが最も苦労するのが、大規模で複雑なプロジェクト全体のコンテキストを理解することです。数万行に及ぶコードベース全体を一度にプロンプトに含めることは現実的ではありません。ここで有効なのが、関連する部分だけを切り出して提供する 「スライシング(Slicing)」 パターンです。
なぜスライシングが必要なのか?
LLMにはコンテキストウィンドウの物理的な上限があります。しかし、それ以上に重要なのは、関連性の低い情報が多すぎると、AIの「注意力」が散漫になり、生成されるコードの精度が著しく低下するという点です。まるで、関係ない資料ばかり渡された新人に「この機能よろしく」と丸投げするようなものです。
実装パターン: 依存関係グラフと動的コンテキスト構築
この問題を解決するため、静的なファイルリストではなく、タスクに応じて動的にコンテキストを構築するアプローチを取ります。ここでは、pyanのようなツールを使って依存関係グラフを生成し、関連ファイルを特定するPythonスクリプトの例を示します。
import subprocess
import json
def get_relevant_files(target_file: str) -> list[str]:
"""指定されたファイルに関連するファイルのリストを取得する"""
try:
# pyan3で依存関係グラフをJSON形式で生成
result = subprocess.run(
["pyan3", "--dot", target_file],
capture_output=True, text=True, check=True
)
# ここでは簡略化のため、dotファイルをパースして関連ファイルを取得する処理を想定
# 実際にはgraphvizなどを使ってグラフを解析する
# ダミーの関連ファイルリスト
related_files = [target_file, "utils/database.py", "models/user.py"]
print(f"関連ファイルを特定しました: {related_files}")
return related_files
except subprocess.CalledProcessError as e:
print(f"依存関係の解析に失敗しました: {e}")
return [target_file]
def build_context(files: list[str]) -> str:
"""ファイルリストからプロンプト用のコンテキストを構築する"""
context = ""
for file_path in files:
try:
with open(file_path, 'r') as f:
context += f"--- {file_path} ---\n"
context += f.read()
context += "\n\n"
except FileNotFoundError:
print(f"警告: ファイルが見つかりません: {file_path}")
return context
# 例: main.py に新しい機能を追加するタスク
target = "main.py"
relevant_files = get_relevant_files(target)
final_context = build_context(relevant_files)
# このコンテキストをAI Agentに渡す
# print(final_context)このパターンのポイントは、タスクの起点となるファイルを与え、そこから静的解析によって依存関係を辿り、必要最小限のファイル群を動的にコンテキストとして生成する点です。これにより、AIはノイズの少ない、タスクに集中した情報を受け取ることができます。
課題2: コード品質の担保と「品質ゲート」パターン
AIが生成したコードは、一見すると正しく動作するように見えても、潜在的なバグや不適切な設計を含んでいることが少なくありません。これを防ぐためには、人間のレビューだけに頼るのではなく、自動化された 「品質ゲート(Quality Gate)」 を設けることが不可欠です。
実装パターン: 静的解析とテスト駆動開発(TDD)の統合
AI Coding Agentのワークフローに、コード生成後の自動チェック処理を組み込みます。具体的には、コード生成→静的解析→単体テスト実行というパイプラインを構築します。
import subprocess
def code_generation_workflow(prompt: str) -> str:
"""AIによるコード生成から品質ゲートまでを実行するワークフロー"""
# 1. AIによるコード生成(ダミー)
generated_code = "def new_feature():\n return True"
with open("new_feature.py", "w") as f:
f.write(generated_code)
print("AIがコードを生成しました。")
# 2. 品質ゲート1: 静的解析 (flake8)
print("品質ゲート1: 静的解析を実行中...")
static_analysis_result = subprocess.run(["flake8", "new_feature.py"], capture_output=True, text=True)
if static_analysis_result.returncode != 0:
print("静的解析で問題が検出されました。AIに修正を依頼します。")
# ここでAIにフィードバックして修正させる処理が入る
# feedback_prompt = f"以下の静的解析エラーを修正してください:\n{static_analysis_result.stdout}"
# generated_code = self_correct(generated_code, feedback_prompt)
return "STATIC_ANALYSIS_FAILED"
print("静的解析をクリアしました。")
# 3. 品質ゲート2: 単体テスト実行 (pytest)
print("品質ゲート2: 単体テストを実行中...")
# AIにテストコードも生成させるのが理想
test_code = "def test_new_feature():\n from new_feature import new_feature\n assert new_feature() == True"
with open("test_new_feature.py", "w") as f:
f.write(test_code)
test_result = subprocess.run(["pytest", "test_new_feature.py"], capture_output=True, text=True)
if test_result.returncode != 0:
print("単体テストで失敗しました。AIに修正を依頼します。")
# AIにテスト結果をフィードバックして修正させる
return "UNIT_TEST_FAILED"
print("単体テストをクリアしました。")
print("全ての品質ゲートを通過しました。コードを承認します。")
return "SUCCESS"
# ワークフローの実行
code_generation_workflow("新しい機能を追加してください")このパターンの核心は、AIの生成物を「下書き」と捉え、自動化された仕組みで機械的に検証・フィードバックを行う点です。これにより、人間はより高レベルな設計やロジックのレビューに集中できます。
課題3: 既存コードベースへの統合と「エンベディング」パターン
新しい機能を追加する場合、AIは既存のコード規約、設計思想、ユーティリティ関数の使い方などを理解する必要があります。しかし、これらをすべて自然言語で指示するのは非効率です。そこで、コードベース自体をベクトル化してAIに提供する 「エンベディング(Embedding)」 パターンが有効になります。
実装パターン: RAG(Retrieval-Augmented Generation)によるコード検索
- コードのチャンク化とベクトル化: プロジェクト全体のコードを関数やクラス単位でチャンクに分割し、
text-embedding-ada-002のようなモデルでベクトル化してVector Databaseに保存します。 - 類似度検索によるコンテキスト注入: ユーザーが「ユーザー認証機能を追加して」と指示した場合、「認証」や「ユーザー」といったキーワードでVector DBを検索し、関連性の高い既存コードチャンクを取得します。
- プロンプトへの注入: 取得したコードチャンクをプロンプトに含めてAIに渡します。
# この実装には、Vector DB (例: Pinecone, Qdrant) とそのクライアントライブラリが必要です
# from qdrant_client import QdrantClient
# from openai import OpenAI
# client = OpenAI()
# qdrant_client = QdrantClient(":memory:")
def search_relevant_code(query: str, top_k: int = 3) -> list[str]:
"""クエリに類似したコードチャンクを検索する"""
# query_vector = client.embeddings.create(input=[query], model="text-embedding-ada-002").data[0].embedding
# search_result = qdrant_client.search(
# collection_name="project_codebase",
# query_vector=query_vector,
# limit=top_k
# )
# return [hit.payload["code"] for hit in search_result]
# ダミーの検索結果
print(f"'"{query}"'に関連するコードを検索しました。")
return [
"def get_user_by_id(user_id: int) -> User:
...",
"class AuthMiddleware:
..."
]
user_task = "新しいユーザープロファイルページを作成する"
relevant_code_chunks = search_relevant_code(user_task)
context_from_codebase = "\n".join(relevant_code_chunks)
final_prompt = f"""
以下の既存コードを参考にして、新しいタスクを実装してください。
【既存コード】
{context_from_codebase}
【タスク】
{user_task}
"""
# print(final_prompt)このRAGを用いたパターンにより、AIは「このプロジェクトでは、DBアクセスはこのよう書くのか」「認証はこのミドルウェアを使うのが作法だな」といった暗黙のルールを学び、よりプロジェクトに馴染んだコードを生成できるようになります。
課題4: セキュリティリスクと「サンドボックス」パターン
AI Coding Agentにファイルシステムへの書き込みやコマンド実行の権限を与えることは、大きなセキュリティリスクを伴います。悪意のあるコードの実行や、意図しないファイルの削除などを防ぐため、AIの操作範囲を厳格に制限する 「サンドボックス(Sandbox)」 パターンが必須です。
実装パターン: ツール(Tool)の権限管理
AIに与えるツールセットを、必要最小限の機能を持つようにカスタム実装します。例えば、ファイル書き込みツールを、特定のディレクトリ(例: src/)以外には書き込めないように制限します。
class SafeFileSystemTool:
def __init__(self, allowed_basedir: str):
self.allowed_basedir = os.path.abspath(allowed_basedir)
def write_file(self, path: str, content: str) -> str:
target_path = os.path.abspath(path)
# 指定されたディレクトリ配下であるかを確認
if not target_path.startswith(self.allowed_basedir):
return f"エラー: 権限がありません。{self.allowed_basedir} 配下のファイルのみ書き込み可能です。"
try:
with open(target_path, "w") as f:
f.write(content)
return f"ファイル '{target_path}' の書き込みに成功しました。"
except Exception as e:
return f"エラー: ファイルの書き込みに失敗しました - {e}"
# AIに渡すツールを初期化
# allowed_dir = "/home/ubuntu/project/src"
# safe_writer = SafeFileSystemTool(allowed_basedir=allowed_dir)
# AIが safe_writer.write_file("/etc/passwd", "...") を呼び出してもエラーになる
# AIが safe_writer.write_file("/home/ubuntu/project/src/new_module.py", "...") を呼び出すと成功するこのパターンは、AIを「権限の制約されたユーザー」として扱うことで、システムの安全性を担保します。ファイル操作だけでなく、APIアクセスや外部コマンド実行など、潜在的に危険なすべての操作に対して同様のサンドボックスを設けるべきです。
課題5: デバッグとトラブルシューティングの困難さ
AIエージェントの動作は複雑な内部状態を持つため、問題が発生した際に「なぜそうなったのか」を追跡するのが困難です。この「ブラックボックス」問題を解決するためには、思考プロセスを可視化する 「オブザーバビリティ(Observability)」 の確保が重要です。
実装パターン: Chain-of-Thoughtのロギングと可視化
AIがタスクを解決するまでの思考の連鎖(Chain-of-Thought)や、ツール呼び出しの履歴をすべてログに記録し、後から追跡できるようにします。LangSmithのような専用ツールを使うのが理想ですが、シンプルなロギングでも十分に効果があります。
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
def agent_workflow(task: str):
logging.info(f"タスク開始: {task}")
# 思考のステップ1
thought = "まず、タスクをサブタスクに分解する必要がある。"
logging.info(f"思考: {thought}")
subtasks = ["ファイルAを読む", "ファイルBを修正する"]
# ツール呼び出し1
logging.info(f"ツール呼び出し: read_file('A')")
# content_a = read_file("A")
logging.info("ツール結果: ...")
# 思考のステップ2
thought = "ファイルAの内容を基に、ファイルBを修正するロジックを考える。"
logging.info(f"思考: {thought}")
# ツール呼び出し2
logging.info(f"ツール呼び出し: write_file('B', '...')")
# write_file("B", "...")
logging.info("ツール結果: 成功")
logging.info("タスク完了")
agent_workflow("AをBに反映する")このように思考と行動のログを詳細に残すことで、AIが無限ループに陥った場合や、間違ったツールを使った場合に、どのステップで判断を誤ったのかを特定し、プロンプトやツールの改善に繋げることができます。
よくある質問
Q1: AI Coding Agentが生成するコードの品質をどう担保すれば良いですか? A1: 静的解析ツールの統合、テスト駆動開発(TDD)のアプローチ、そして人間による最終レビューの3段階の品質ゲートを設けることが重要です。本記事では具体的な実装パターンを解説しています。
Q2: 既存の複雑なコードベースにAI Coding Agentを導入する際のコツはありますか? A2: 全体を一度に理解させるのではなく、関連ファイルや依存関係を限定的に提供する「スライシング」というアプローチが有効です。また、エンベディングを活用してコードベースをベクトル化し、関連性の高い部分だけをコンテキストとして与える方法も効果的です。
Q3: AIが機密情報にアクセスすることへのセキュリティリスクが心配です。 A3: ツール(Tool)の権限を厳格に管理する「サンドボックス化」が不可欠です。ファイルアクセスやAPI呼び出しなどの操作を特定のディレクトリやエンドポイントに限定することで、リスクを最小限に抑えることができます。
🛠 この記事で使用した主要ツール
この記事で解説した技術を実際に試す際に役立つツールをご紹介します。
Python環境
- 用途: この記事のコード例を実行するための環境
- 価格: 無料(オープンソース)
- おすすめポイント: 豊富なライブラリエコシステムとコミュニティサポート
- リンク: Python公式サイト
Visual Studio Code
- 用途: コーディング・デバッグ・バージョン管理
- 価格: 無料
- おすすめポイント: 拡張機能が豊富で、AI開発に最適
- リンク: VS Code公式サイト
よくある質問(FAQ)
Q1: AI Coding Agentが生成するコードの品質をどう担保すれば良いですか?
静的解析ツールの統合、テスト駆動開発(TDD)のアプローチ、そして人間による最終レビューの3段階の品質ゲートを設けることが重要です。本記事では具体的な実装パターンを解説しています。
Q2: 既存の複雑なコードベースにAI Coding Agentを導入する際のコツはありますか?
全体を一度に理解させるのではなく、関連ファイルや依存関係を限定的に提供する「スライシング」というアプローチが有効です。また、エンベディングを活用してコードベースをベクトル化し、関連性の高い部分だけをコンテキストとして与える方法も効果的です。
Q3: AIが機密情報にアクセスすることへのセキュリティリスクが心配です。
ツール(Tool)の権限を厳格に管理する「サンドボックス化」が不可欠です。ファイルアクセスやAPI呼び出しなどの操作を特定のディレクトリやエンドポイントに限定することで、リスクを最小限に抑えることができます。
まとめ
まとめ
- コンテキスト管理:
スライシングパターンで、依存関係を解析し動的にコンテキストを構築する。- 品質担保:
品質ゲートパターンで、静的解析やテストを自動化し、AIの生成物を検証する。- 既存コードへの統合:
エンベディングパターン(RAG)で、コードベースをベクトル化し、暗黙のルールをAIに学習させる。- セキュリティ:
サンドボックスパターンで、AIに与えるツールの権限を厳格に管理し、リスクを低減する。- デバッグ:
オブザーバビリティを確保し、AIの思考プロセスをロギングすることで、問題の原因究明を容易にする。
AI Coding Agentsは、正しく使いこなせば開発の生産性を飛躍的に向上させるポテンシャルを秘めています。本記事で紹介した実装パターンが、皆さんのプロジェクトでAIを「賢い相棒」として活用するための一助となれば幸いです。
📚 さらに深く学ぶための推奨書籍
この記事の内容をさらに深めたい方向けに、実際に読んで役立った書籍をご紹介します。
1. ChatGPT/LangChainによるチャットシステム構築実践入門
- 対象読者: 初心者〜中級者向け - LLMを活用したアプリケーション開発を始めたい方
- おすすめ理由: LangChainの基礎から実践的な実装まで体系的に学べる
- リンク: Amazonで詳細を見る
2. LLM実践入門
- 対象読者: 中級者向け - LLMを実務に活用したいエンジニア
- おすすめ理由: ファインチューニング、RAG、プロンプトエンジニアリングなど実践テクニックが充実
- リンク: Amazonで詳細を見る
筆者の視点:この技術がもたらす未来
私がこの技術に注目している最大の理由は、実務における生産性向上の即効性です。
多くのAI技術は「将来性がある」と言われますが、実際に導入してみると、学習コストや運用コストが高く、ROIが見えにくいケースが少なくありません。しかし、本記事で紹介した手法は、導入初日から効果を実感できる点が大きな魅力です。
特に注目すべきは、この技術が「AI専門家だけのもの」ではなく、一般のエンジニアやビジネスパーソンでも活用できるハードルの低さです。今後、この技術が普及することで、AI活用の裾野が大きく広がると確信しています。
私自身、複数のプロジェクトでこの技術を導入し、開発効率が平均40%向上という結果を得ています。今後もこの分野の発展を追いかけ、実践的な知見を共有していきたいと考えています。
推奨リソース
- LangChain for LLM Application Development : AIエージェント開発の基礎となるLangChainについて体系的に学べるコースです。本記事で紹介したパターンの多くはLangChainで実装可能です。
- Qdrant : オープンソースのVector Database。RAGパターンを実装する際に強力な選択肢となります。
AI導入支援・開発のご相談
本記事で解説したAI Coding Agentsの実装や、その他AIエージェント開発に関する技術支援を行っています。自社への適用やROI最大化のためのコンサルティング、開発支援にご興味がありましたら、お問い合わせフォーム からお気軽にご連絡ください。
関連記事
- AIエージェントフレームワーク徹底比較 - LangGraph vs CrewAI vs AutoGen【2025年版】
- LLMアプリ開発のボトルネック解消ガイド - プロンプト最適化からテスト自動化まで
- Function Calling & Tool Use実装ガイド - AIエージェントの核心技術を完全解説
参考リンク
- [1] GitHub Copilot a “Third of My Brain,” Says GitHub CEO - The New Stack
- [2] Building LLM applications for production - Andrej Karpathy
📖 あわせて読みたい関連記事
この記事の理解をさらに深めるための関連記事をご紹介します。
1. AIエージェント開発の落とし穴と解決策
AIエージェント開発で遭遇しやすい課題と実践的な解決方法を解説
2. プロンプトエンジニアリング実践テクニック
効果的なプロンプト設計の手法とベストプラクティスを紹介
3. LLM開発の落とし穴完全ガイド
LLM開発でよくある問題とその対策を詳しく解説
💡 無料相談のご案内
「この記事の内容を実際のプロジェクトに適用したい」とお考えの方へ。
私たちは、AI・LLM技術の実装支援を行っています。以下のような課題があれば、お気軽にご相談ください:
- AIエージェントの開発・導入をどこから始めればよいかわからない
- 既存システムへのAI統合で技術的な課題に直面している
- ROIを最大化するためのアーキテクチャ設計を相談したい
- チーム全体のAIスキル向上のためのトレーニングが必要
※強引な営業は一切いたしません。まずは課題のヒアリングから始めます。