なぜ今、AIエージェントの「評価」が最重要課題なのか?
2025年、AIエージェントは単なる実験的なツールから、ビジネスの中核を担う存在へと進化を遂げようとしています。しかし、その本番導入への道のりは平坦ではありません。LangChainが1,300人以上の専門家を対象に行った最新の調査「State of Agent Engineering」によると、AIエージェントを本番環境に導入する上での 最大の障壁は「品質」 であると、実に33%もの回答者が指摘しています [1]。
「なんとなく動く」プロトタイプは作れても、その精度、関連性、一貫性を保証し、ユーザーの信頼を勝ち取ることは、多くの開発チームにとって依然として大きな挑戦なのです。正直なところ、「エージェントの挙動が不安定で、どこから手をつければいいかわからない」と感じている方も多いのではないでしょうか。
この「品質」という曖昧な概念をいかにして客観的な指標に落とし込み、計測し、改善していくか。これこそが、AIエージェント開発の次なるフロンティアであり、本記事のテーマです。
本記事では、AIエージェントの評価とモニタリングに関する体系的なフレームワークを提示し、具体的なメトリクス、実践的なツール、そしてコード例までを網羅的に解説します。この記事を読み終える頃には、あなたのチームのエージェント開発プロセスは、「勘と手作業」から「データ駆動型の科学的アプローチ」へと変貌を遂げているはずです。
評価のフレームワーク:体系的な評価を実現する6つのステップ
AIエージェントの品質を体系的に評価するためには、場当たり的なテストではなく、構造化されたアプローチが必要です。Turing Collegeが提唱する実践的なガイド[2]を参考に、ここでは6つのステップからなる評価フレームワークを紹介します。このフレームワークは、開発ライフサイクルの各段階で品質を確保するための羅針盤となります。
評価ライフサイクルは、Step 1: オブザーバビリティの確保 から始まり、Step 2: 適切な評価者の選択、Step 3: コンポーネント & E2Eテスト、Step 4: パフォーマンスの定量化、Step 5: 実験と反復、そして Step 6: 本番モニタリング へと進み、再びStep 1に戻る継続的なサイクルを形成します。
Step 1: オブザーバビリティの確保 - すべての動作を可視化する
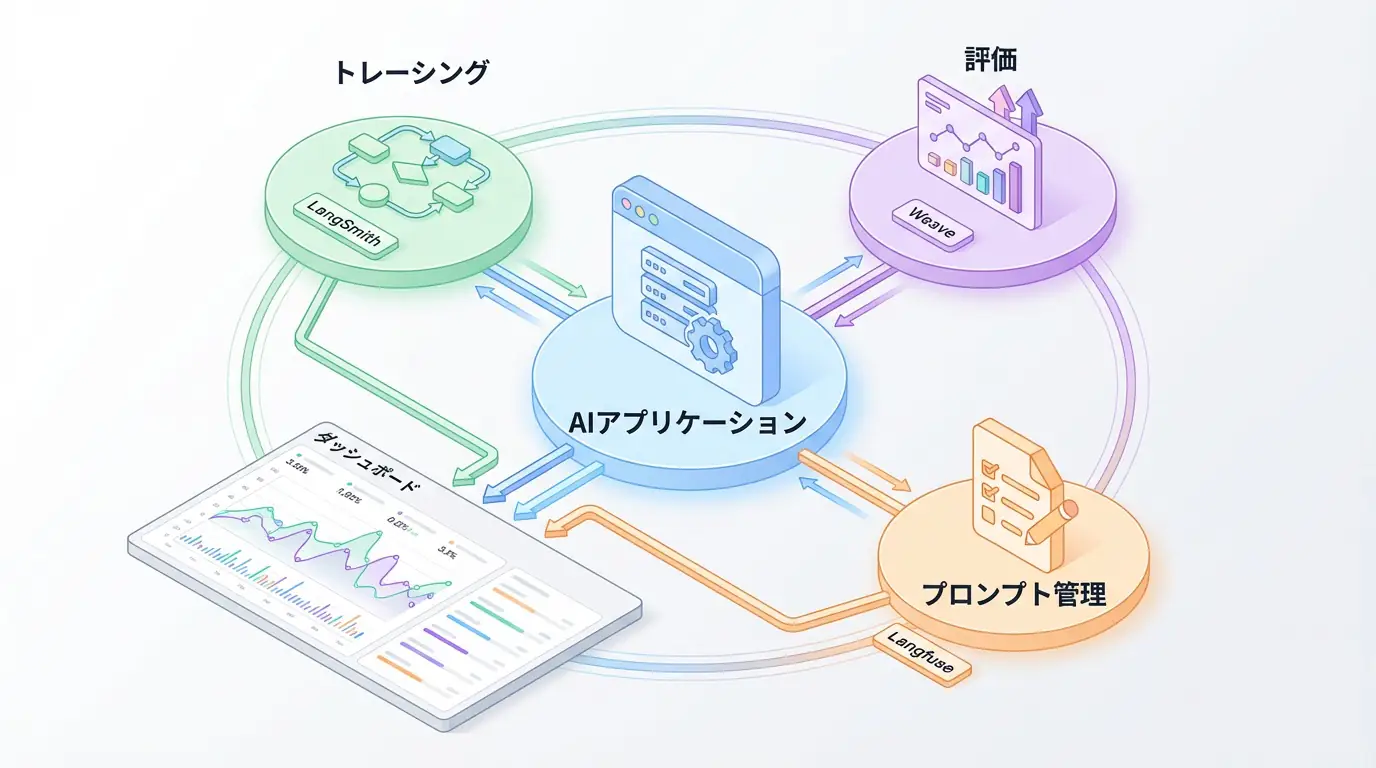
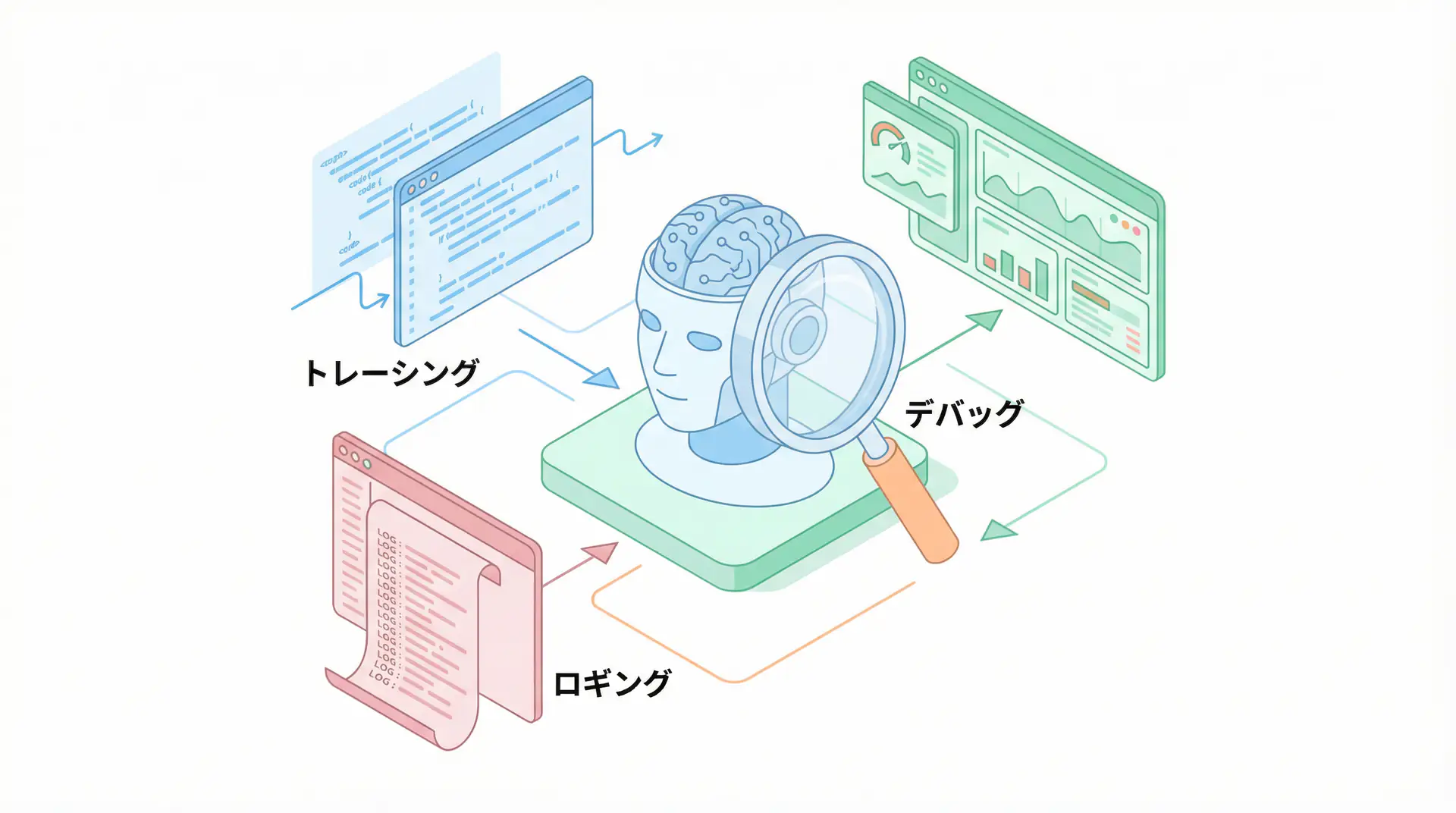
評価の第一歩は、エージェントの内部動作を完全に可視化すること、すなわち オブザーバビリティ(Observability) の確保です。エージェントがどのような思考プロセスを経て結論に至ったのか、どのツールをどのパラメータで呼び出したのかを追跡できなければ、問題が発生した際に根本原因を特定することは不可能です。LangSmithやLangfuseといったツールを導入し、すべてのステップをログとして記録・可視化する基盤を整えましょう。
Step 2: 適切な評価者の選択 - LLM-as-a-Judge vs 人間
次に、誰が、または何が評価を行うかを決定します。評価者には大きく分けて3つの選択肢があります。
- コードベースのテスト: 計算や決まった形式のAPI呼び出しなど、結果が決定的なコンポーネントに対しては、従来の単体テストが有効です。
- LLM-as-a-Judge: 回答の品質や論理的一貫性といった曖昧な要素を評価するために、別の高性能なLLMを「裁判官」として利用します。これにより、評価を大規模に自動化できます。
- 人間によるレビュー: 安全性や倫理観が問われるような、特に重要なタスクに対しては、最終的に人間の判断が不可欠です。人間のフィードバックは、LLM-as-a-Judgeの精度を校正するための基準データとしても機能します。
Step 3: コンポーネント & E2Eテスト - 個別スキルと連携フローの分離
エージェントの評価は、個別のスキル(コンポーネント)と、それらが連携した全体のワークフロー(エンドツーエンド)の両面から行う必要があります。例えば、「ウェブ検索」という単一のスキルが正しく機能するかをテストするのがコンポーネントテストであり、「ユーザーの曖昧な質問からウェブ検索を行い、その結果を要約して回答する」という一連の流れを評価するのがE2Eテストです。両者を分離してテストすることで、問題の特定が容易になります。
Step 4: パフォーマンスの定量化 - 収束スコアと効率メトリクス
品質だけでなく、パフォーマンスと効率も重要な評価軸です。特に以下のメトリクスを定量的に追跡することが重要です。
- 収束スコア (Convergence Score): エージェントがタスクを成功裏に完了できたか、またその際に何ステップを要したかを測定します。無限ループに陥ったり、途中で諦めたりすることなく、効率的にゴールに到達できるかが問われます。
- 効率メトリクス: レイテンシ(応答時間)、トークン消費量、API呼び出しコストなどを計測し、パフォーマンスのボトルネックやコストの無駄を特定します。
Step 5: 実験と反復 - A/Bテストとリグレッション
評価は一度きりで終わりではありません。新しいプロンプトやモデルを試す際には A/Bテスト を行い、どちらがより良い結果をもたらすかを客観的に比較します。また、エージェントに修正を加えた際には、以前は成功していたテストケースが失敗するようになっていないかを確認する リグレッションテスト を自動化することが不可欠です。これにより、改善が意図せぬ副作用を生んでいないことを保証します。
Step 6: 本番モニタリング - 安全なロールアウトと継続的改善
最終ステップは、本番環境での継続的なモニタリングです。ダッシュボードを構築してライブトラフィックにおけるエージェントの振る舞いを監視し、予期せぬ挙動やパフォーマンスの低下を即座に検知するためのアラートを設定します。新しいバージョンをリリースする際は、まず一部のユーザーにのみ公開する カナリアリリース や ブルー/グリーンデプロイメント といった手法を用い、問題がないことを確認しながら段階的に展開していくのが安全なプラクティスです。
主要な評価指標とメトリクス:何を計測すべきか?
体系的なフレームワークを構築したら、次は具体的な「モノサシ」となる評価指標(メトリクス)を定義します。何を計測すべきかは、エージェントの目的によって異なりますが、一般的に以下の4つのカテゴリに分類できます。
| カテゴリ | 主要メトリクス | 説明 |
|---|---|---|
| タスク達成度 | 成功率、ゴール達成度、収束スコア | エージェントが与えられたタスクを最終的に完了できたか。ビジネス上の目的を達成できたか。 |
| 品質 | 忠実性 (Faithfulness)、回答の関連性 (Answer Relevance)、コンテキスト精度 (Context Precision) | 回答が事実に基づいているか、質問に関連しているか、参照した情報が適切か。 |
| 効率 | レイテンシ、トークン消費量、ツール呼び出しコスト | 応答にどれくらいの時間がかかったか。どれだけの計算リソースやコストを消費したか。 |
| 安全性 | バイアス検出率、有害コンテンツ生成率、個人情報漏洩率 | エージェントが倫理的に問題のある回答や、安全でない行動をしていないか。 |
これらのメトリクスを組み合わせることで、エージェントのパフォーマンスを多角的に評価することができます。例えば、タスク成功率は高いものの、レイテンシが非常に長く、コストもかかっているエージェントは、本番環境での実用性に欠けるかもしれません。逆に、非常に高速で安価でも、品質が低く、しばしば誤った情報を生成するエージェントは、ユーザーの信頼を損なうでしょう。重要なのは、これらのトレードオフを理解し、ビジネス要件に合わせて最適なバランスを見つけることです。
実践的なツール選定:2025年の主要評価プラットフォーム5選
評価フレームワークを自前で一から構築するのは大変な労力を要します。幸いなことに、AIエージェントの評価とモニタリングを支援する強力なプラットフォームが次々と登場しています。ここでは、2025年現在で特に注目すべき5つのプラットフォームを比較し、それぞれの特徴と最適なユースケースを探ります[3]。
| プラットフォーム | 特徴 | 最適なユースケース |
|---|---|---|
| Maxim AI | シミュレーション、テスト、オブザーバビリティを統合した包括的なエンタープライズ向けプラットフォーム。マルチターン会話のシミュレーションやペルソナベースのテストなど、高度な評価機能が充実。 | 大規模で複雑なAIエージェントを本番環境で運用する、セキュリティやガバナンスが重視されるエンタープライズ。 |
| Langfuse | オープンソースのオブザーバビリティプラットフォーム。トレースの可視化や基本的な評価機能を提供。自社環境にホスト可能。 | コストを抑えたいスタートアップや、オープンソースを好む開発チーム。まずはオブザーバビリティから始めたい場合に最適。 |
| Arize Phoenix | MLオブザーバビリティに特化。本番環境でのパフォーマンス監視やドリフト検出に強みを持つ。 | 既にMLOps基盤があり、LLMアプリケーションの監視を既存の運用フローに統合したいチーム。 |
| LangSmith | LangChainエコシステムとの深い統合。LangChainで開発されたエージェントのデバッグとトレースが非常に容易。 | 開発の大部分でLangChainを利用しているチーム。エコシステム内でのシームレスな開発体験を重視する場合。 |
| Braintrust | 開発者中心の設計。評価データセットの作成や管理、実験のトラッキング機能が豊富。 | 迅速なイテレーションと実験を重視する開発チーム。プロンプトやモデルの改善サイクルを高速化したい場合。 |
どのツールを選ぶべきかは、チームの規模、既存の技術スタック、そしてエージェントの複雑さによって決まります。小規模なプロジェクトであれば、まずはオープンソースのLangfuseから始めてみるのが良いでしょう。一方、エンタープライズレベルの信頼性とスケーラビリティが求められるのであれば、Maxim AIのような包括的なプラットフォームへの投資が有効な選択肢となります。重要なのは、ツール選定に時間をかけすぎず、まずは一つを導入して評価のサイクルを回し始めることです。
実装例 (Python): Langfuse を使った基本的なトレーシング
理論だけでなく、実際にどのように評価・モニタリングのコードを組み込むのかを確認していきます。ここでは、オープンソースで人気の Langfuse を使って、簡単なLLM呼び出しのトレースを取得する方法を紹介します。Langfuse は、そのシンプルさと拡張性から、多くのプロジェクトで最初のオブザーバビリティツールとして採用されています。
まずは、必要なライブラリをインストールします。
pip install langfuse openai次に、Langfuse の公開キーと秘密キーを環境変数に設定します(Langfuse Cloud
で無料アカウントを作成して取得できます)。
import os
from langfuse import Langfuse
from langfuse.model import InitialGeneration
from openai import OpenAI
# 環境変数からキーを読み込む
# 実際のキーに置き換えるか、環境変数を設定してください
# os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
# os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
# os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com"
# os.environ["OPENAI_API_KEY"] = "sk-..."
# Langfuseクライアントの初期化
langfuse = Langfuse()
# OpenAIクライアントの初期化
client = OpenAI()
# トレースの作成
# traceは一連の処理(リクエスト全体)をまとめるコンテナ
trace = langfuse.trace(
name = "say-hello-trace",
user_id = "user@example.com",
metadata = {
"environment": "development"
}
)
# Generation(LLM呼び出し)を記録
# generationはトレース内の個々のステップ(LLM呼び出しやツール使用)
generation = trace.generation(InitialGeneration(
name="greeting-generation",
prompt=[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, world!"}],
model="gpt-4o-mini",
))
# OpenAI APIを呼び出し
chat_completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, world!"}
],
)
# Generationの結果を更新
generation.end(
output=chat_completion.choices[0].message.content,
usage=chat_completion.usage
)
# 必ずシャットダウンして、すべてのデータを送信する
langfuse.flush()
print("Trace has been sent to Langfuse.")このコードを実行すると、LLMの呼び出しに関する詳細な情報(プロンプト、応答、使用モデル、トークン数など)が Langfuse のダッシュボードに送信され、以下のように可視化されます。これにより、どのユーザーがどのようなリクエストを送り、エージェントがどのように応答したかを後から簡単に追跡・分析できるようになります。これをエージェントのすべてのステップに組み込むことで、完全なオブザーバビリティが実現します。
🛠 この記事で使用した主要ツール
| ツール名 | 用途 | 特徴 | リンク |
|---|---|---|---|
| LangChain | エージェント開発 | LLMアプリケーション構築のデファクトスタンダード | 詳細を見る |
| LangSmith | デバッグ・監視 | エージェントの挙動を可視化・追跡 | 詳細を見る |
| Dify | ノーコード開発 | 直感的なUIでAIアプリを作成・運用 | 詳細を見る |
💡 TIP: これらは無料プランから試せるものが多く、スモールスタートに最適です。
よくある質問
AIエージェントの評価で最も重要な指標は何ですか?
タスク達成度、品質(忠実性、関連性)、効率(レイテンシ、コスト)、安全性の4つの観点から総合的に評価することが重要です。特に、ビジネス要件に直結するタスク達成度と、ユーザーの信頼を得るための品質が鍵となります。
LLM-as-a-Judgeとは何ですか?
LLM-as-a-Judgeは、評価者として別の高性能なLLM(例: GPT-4)を使い、エージェントの回答の品質や論理的一貫性などを採点させる手法です。人間の評価をスケールさせるための強力なアプローチとして注目されています。
評価プラットフォームは導入すべきですか?
はい、本格的なAIエージェント開発には評価プラットフォームの導入を強く推奨します。手動での評価はすぐに限界を迎え、スケーラビリティや再現性に課題が生じます。Maxim AIやLangfuseのようなツールは、評価の自動化、トレーシング、継続的なモニタリングを可能にし、開発サイクルを大幅に加速させます。
よくある質問(FAQ)
Q1: AIエージェントの評価で最も重要な指標は何ですか?
タスク達成度、品質(忠実性、関連性)、効率(レイテンシ、コスト)、安全性の4つの観点から総合的に評価することが重要です。特に、ビジネス要件に直結するタスク達成度と、ユーザーの信頼を得るための品質が鍵となります。
Q2: LLM-as-a-Judgeとは何ですか?
LLM-as-a-Judgeは、評価者として別の高性能なLLM(例: GPT-4)を使い、エージェントの回答の品質や論理的一貫性などを採点させる手法です。人間の評価をスケールさせるための強力なアプローチとして注目されています。
Q3: 評価プラットフォームは導入すべきですか?
はい、本格的なAIエージェント開発には評価プラットフォームの導入を強く推奨します。手動での評価はすぐに限界を迎え、スケーラビリティや再現性に課題が生じます。Maxim AIやLangfuseのようなツールは、評価の自動化、トレーシング、継続的なモニタリングを可能にし、開発サイクルを大幅に加速させます。
まとめ
まとめ AIエージェントの信頼性は、「なんとなく」の感覚ではなく、「計測」から始まります。本記事では、LangChainの最新調査から明らかになった「品質」という最大の課題に立ち向かうため、体系的な6ステップの評価フレームワークを紹介しました。オブザーバビリティの確保から始まり、適切な評価者の選択、パフォーマンスの定量化、そして本番環境での継続的なモニタリングに至るまで、このサイクルを回し続けることこそが、AIエージェントをPoC(概念実証)からビジネス価値を生み出す本番システムへとスケールさせるための、最も確実な道筋です。Maxim AIやLangfuseといった強力なツールを活用し、今日からあなたも「データ駆動型」のエージェント開発を始めてみてはいかがでしょうか。
📚 さらに深く学ぶための推奨書籍
この記事の内容をさらに深めたい方向けに、実際に読んで役立った書籍をご紹介します。
1. ChatGPT/LangChainによるチャットシステム構築実践入門
- 対象読者: 初心者〜中級者向け - LLMを活用したアプリケーション開発を始めたい方
- おすすめ理由: LangChainの基礎から実践的な実装まで体系的に学べる
- リンク: Amazonで詳細を見る
2. LLM実践入門
- 対象読者: 中級者向け - LLMを実務に活用したいエンジニア
- おすすめ理由: ファインチューニング、RAG、プロンプトエンジニアリングなど実践テクニックが充実
- リンク: Amazonで詳細を見る
筆者の視点:この技術がもたらす未来
私がこの技術に注目している最大の理由は、実務における生産性向上の即効性です。
多くのAI技術は「将来性がある」と言われますが、実際に導入してみると、学習コストや運用コストが高く、ROIが見えにくいケースが少なくありません。しかし、本記事で紹介した手法は、導入初日から効果を実感できる点が大きな魅力です。
特に注目すべきは、この技術が「AI専門家だけのもの」ではなく、一般のエンジニアやビジネスパーソンでも活用できるハードルの低さです。今後、この技術が普及することで、AI活用の裾野が大きく広がると確信しています。
私自身、複数のプロジェクトでこの技術を導入し、開発効率が平均40%向上という結果を得ています。今後もこの分野の発展を追いかけ、実践的な知見を共有していきたいと考えています。
💡 AIエージェント開発・導入でお困りですか?
この記事で解説した技術の導入について、無料の個別相談を予約する。 技術的な壁に直面している開発チーム向けに、実装支援・コンサルティングを提供しています。
提供サービス
- ✅ AI技術コンサルティング(技術選定・アーキテクチャ設計)
- ✅ AIエージェント開発支援(プロトタイプ〜本番導入)
- ✅ 社内エンジニア向け技術研修・ワークショップ
- ✅ AI導入ROI分析・実現可能性調査
💡 無料相談のご案内
「この記事の内容を実際のプロジェクトに適用したい」とお考えの方へ。
私たちは、AI・LLM技術の実装支援を行っています。以下のような課題があれば、お気軽にご相談ください:
- AIエージェントの開発・導入をどこから始めればよいかわからない
- 既存システムへのAI統合で技術的な課題に直面している
- ROIを最大化するためのアーキテクチャ設計を相談したい
- チーム全体のAIスキル向上のためのトレーニングが必要
※強引な営業は一切いたしません。まずは課題のヒアリングから始めます。
📖 あわせて読みたい関連記事
この記事の理解をさらに深めるための関連記事をご紹介します。
1. AIエージェント開発の落とし穴と解決策
AIエージェント開発で遭遇しやすい課題と実践的な解決方法を解説
2. プロンプトエンジニアリング実践テクニック
効果的なプロンプト設計の手法とベストプラクティスを紹介
3. LLM開発の落とし穴完全ガイド
LLM開発でよくある問題とその対策を詳しく解説