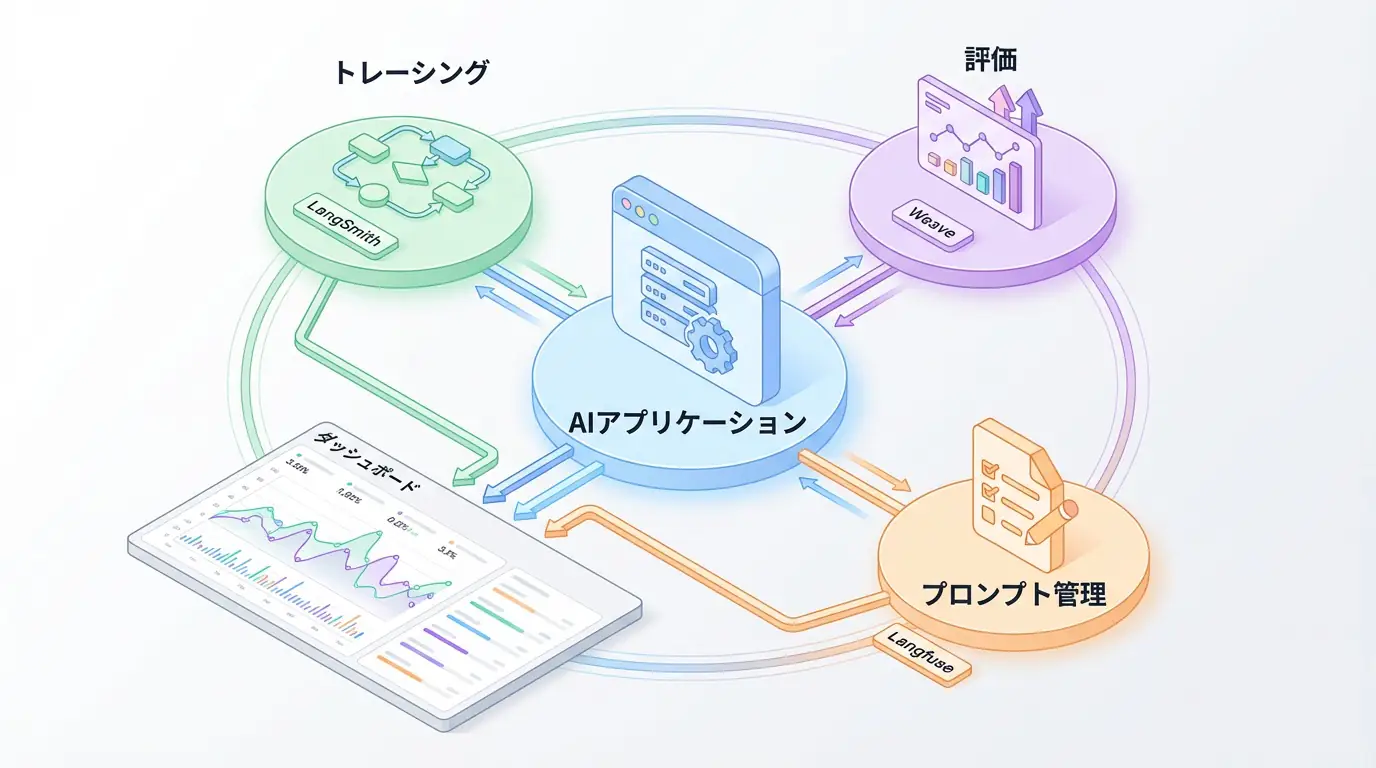
なぜ、あなたのAIエージェントは期待通りに動かないのか?
2025年、「AIエージェント元年」と呼ばれ、多くの企業がその導入に期待を寄せています。Capgeminiの調査によれば、実に 82% もの企業が2026年までにAIエージェントの導入を計画していると言います [1]。しかしその裏で、エンタープライズAIプロジェクトの 70-85% が本番稼働前に頓挫しているという厳しい現実も存在します [2]。
その最大の原因の一つが、AIエージェントの「ブラックボックス問題」です。従来のソフトウェアのように、入力に対して決まった出力が返ってくるわけではありません。エージェントは自律的に思考し、ツールを使い、時には予想外の行動をとります。問題が発生しても、「なぜそうなったのか」を特定するのは極めて困難です。
私自身、開発の現場で何度もこの壁にぶつかってきました。「昨日まで動いていたのに、今日はなぜか無限ループに陥る」「些細な入力の違いで、全く見当違いなツールを呼び出してしまう」。こうした経験から、AIエージェント開発の成否は、いかにしてその「思考プロセス」を可視化し、デバッグできるかにかかっていると痛感しています。
本記事では、AIエージェント開発で避けては通れない10の一般的な失敗モードを特定し、その原因と具体的な解決策を、実践的なコード例を交えながら徹底的に解説します。この記事を読み終える頃には、あなたはブラックボックスを恐れることなく、信頼性の高いAIエージェントを構築するための羅針盤を手にしているはずです。
AIエージェントは「生き物」である:従来型デバッグの限界
従来のソフトウェア開発におけるデバッグは、再現可能なバグを特定し、コードのロジックを修正するプロセスでした。しかし、AIエージェントは、LLMの非決定的な性質、長期的な記憶(コンテキスト)、そして自律的なツール連携という3つの要素が絡み合う、いわば「生き物」のような存在です。
- 非決定性 (Non-determinism): 同じプロンプトでも、LLMの応答は毎回微妙に変化します。これが、バグの再現を困難にします。
- 長期的な記憶 (Long-term Memory): エージェントは過去の対話履歴を記憶していますが、コンテキストウィンドウの制限により、重要な情報を「忘れて」しまうことがあります。
- 自律的なツール連携 (Autonomous Tool Use): エージェントは自らの判断でAPIを呼び出しますが、その判断が常に正しいとは限りません。
これらの特性により、リクエストとレスポンスを追うだけの従来型デバッグでは、問題の根本原因にたどり着くことは不可能なのです。
現場で頻発する10の失敗モードと、その処方箋
AIエージェントのデバッグは、以下の図に示すような体系的なプロセスで行います。問題を検出し、トレースを分析し、原因を特定し、修正を実装し、最後に検証するという流れです。
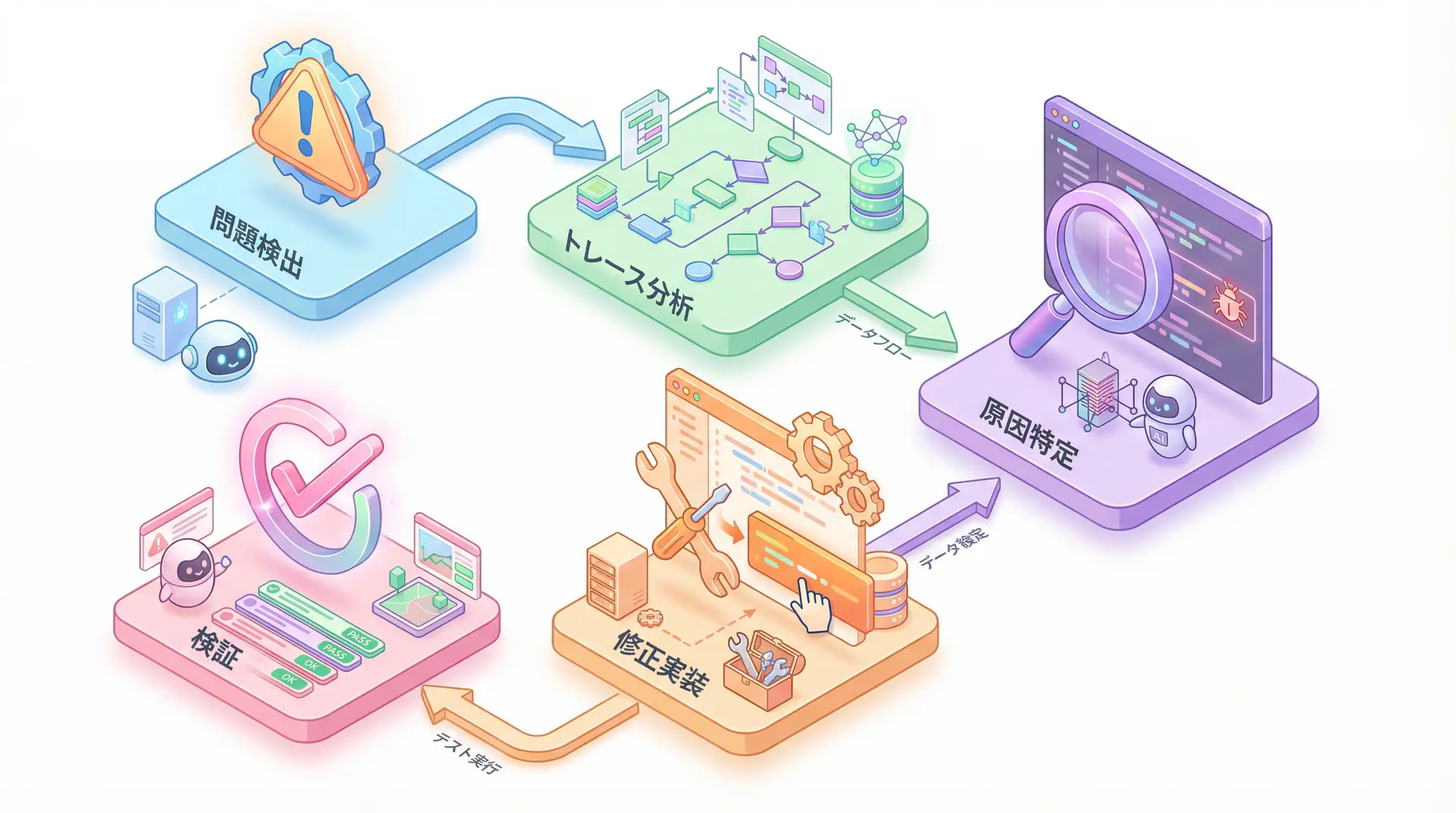
米国のAI評価プラットフォームGalileo AIの分析によれば、AIエージェントの失敗は、以下の10のパターンに集約されると言います [3]。ここでは、それぞれのモードに対する具体的な検出方法と解決策を確認していきます。
| 失敗モード | 問題の概要 | 主な検出方法 | 解決策 |
|---|---|---|---|
| 1. ハルシネーションの連鎖 | 一つの幻覚が次の幻覚を生み、誤った結論に至る | Semantic Divergence Score, Hallucination Metrics | ファクトチェック、Temperature調整、Guardrails |
| 2. ツール呼び出しの失敗 | APIのスキーマ不一致やパラメータ不足でエラー | Tool Error Metrics, HTTP 4xx/5xx | API契約の厳格化、スキーマのバージョン管理 |
| 3. コンテキストの切り捨て | 長い対話履歴の重要な部分が失われる | 精度の急な低下、論理の飛躍 | 動的プルーニング、階層的メモリ、自動要約 |
| 4. プランナーの無限ループ | 完了条件が曖昧で、同じタスクを永遠に繰り返す | Agent Efficiency Score, トークン使用量の急増 | 明確な完了条件、コストキャップ、ハードタイムアウト |
| 5. データ漏洩・PII露出 | 機密情報や個人情報が意図せず出力される | Regexスクリーン, LLMベースのスキャナー | 取得パイプラインの制限、出力フィルタリング |
| 6. 非決定的な出力ドリフト | 同じ入力に対し、出力の一貫性が徐々に失われる | Output Coherence Metrics | プロンプトチューニング、実験フレームワーク |
| 7. メモリ肥大化と状態ドリフト | 長期セッションでメモリが増え続け、動作が不安定に | Session Monitoring | TTLポリシー、メモリプルーニング |
| 8. レイテンシスパイク | 特定の条件下で応答時間が急激に悪化する | p95 Latency, リソース使用量メトリクス | リソース割り当て最適化、キャッシング戦略 |
| 9. マルチエージェント間の競合 | 複数のエージェントが互いに矛盾した行動をとる | Multi-agent Tracing, Agent Flow | エージェント間調整プロトコル、中央集権的オーケストレーション |
| 10. 評価の盲点 | 既存のテストではカバーできない未知の問題 | Continuous Learning via Human Feedback (CLHF) | 人間参加型ループによる継続的なフィードバック |
課題解決シミュレーション:無限ループする報告書作成エージェント
ここで、具体的なシナリオを考えてみましょう。
課題 (Problem): 週次報告書を自動生成するAIエージェントを開発した。しかし、エージェントが「報告書の構成案作成」と「各項目の詳細化」のステップを無限に繰り返し、いつまで経っても報告書が完成しない。
解決策 (Solution):
- 検出: まず、LangSmithのようなトレーシングツールでエージェントの思考プロセスを可視化します。すると、プランナーが同じ
(Plan -> Execute -> Reflect)のサイクルを繰り返していることが確認できます。Agent Efficiency Scoreも異常に低い値を示しているでしょう。 - 原因分析: ループの原因は、完了条件の曖昧さにありました。「報告書を完成させる」というゴールが抽象的すぎたため、エージェントは「構成案の改善」と「詳細化」を無限に繰り返すのが最善だと判断してしまったのです。
- 対策: プロンプトを修正し、より明確な完了条件を設定します。「1. 序論、2. 主要KPI、3. 今週の活動、4. 来週の計画、5. 結論 の5つのセクションを全て記述し、総文字数が1500文字を超えた時点でタスクを完了とする」のように、具体的かつ測定可能なゴールを与えます。さらに、最大ステップ数(例: 10回)のハードリミットを設けることで、万が一のループを防ぎます。
- 検出: まず、LangSmithのようなトレーシングツールでエージェントの思考プロセスを可視化します。すると、プランナーが同じ
実装例:LangSmithを使ったトレーシングとロギング
理論だけではイメージが湧きにくいでしょう。ここでは、AIエージェント開発フレームワークLangChainが提供するLangSmithを使い、エージェントの思考を可視化する実装例を紹介します。正直なところ、これなしでのエージェント開発は考えられません。
TIP LangSmithを利用するには、環境変数に
LANGCHAIN_API_KEYなどを設定する必要があります。詳細は公式ドキュメント [4] を確認してください。
以下のコードは、ユーザーの質問に対してウェブ検索を行い、回答を生成するシンプルなエージェントです。重要なのは、traceable デコレータを使うことで、各関数の入出力を自動的にLangSmithに記録できる点です。
import os
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langsmith import traceable
from tavily import TavilyClient
# 環境変数の設定 (LangSmith と Tavily APIキー)
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = "YOUR_LANGSMITH_API_KEY"
# os.environ["TAVILY_API_KEY"] = "YOUR_TAVILY_API_KEY"
# 1. Web検索ツール
@traceable(name="Web Search Tool")
def web_search(query: str):
"""指定されたクエリでWeb検索を実行し、結果を返す"""
print(f"--- Web検索実行: {query} ---")
tavily = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
response = tavily.search(query=query, search_depth="advanced")
return response["results"]
# 2. 回答生成LLM
@traceable(name="Answer Generation")
def generate_answer(query: str, context: list):
"""検索結果を基に、ユーザーの質問に回答する"""
print("--- 回答生成開始 ---")
prompt_template = ChatPromptTemplate.from_messages([
("system", "あなたは優秀なAIアシスタントです。提供された検索結果を基に、ユーザーの質問に簡潔に回答してください。\n\n検索結果:\n{context}"),
("user", "質問: {query}")
])
llm = ChatOpenAI(model="gpt-4.1-mini")
chain = prompt_template | llm | StrOutputParser()
return chain.invoke({"query": query, "context": context})
# 3. エージェントのメインロジック
@traceable(name="Main Agent Logic")
def run_agent(query: str):
"""エージェントのメインロジックを実行する"""
print("--- エージェント実行開始 ---")
search_results = web_search(query)
answer = generate_answer(query, search_results)
return answer
if __name__ == "__main__":
user_query = "2025年のAIエージェント開発における最も重要なトレンドは何ですか?"
final_answer = run_agent(user_query)
print("\n--- 最終的な回答 ---")
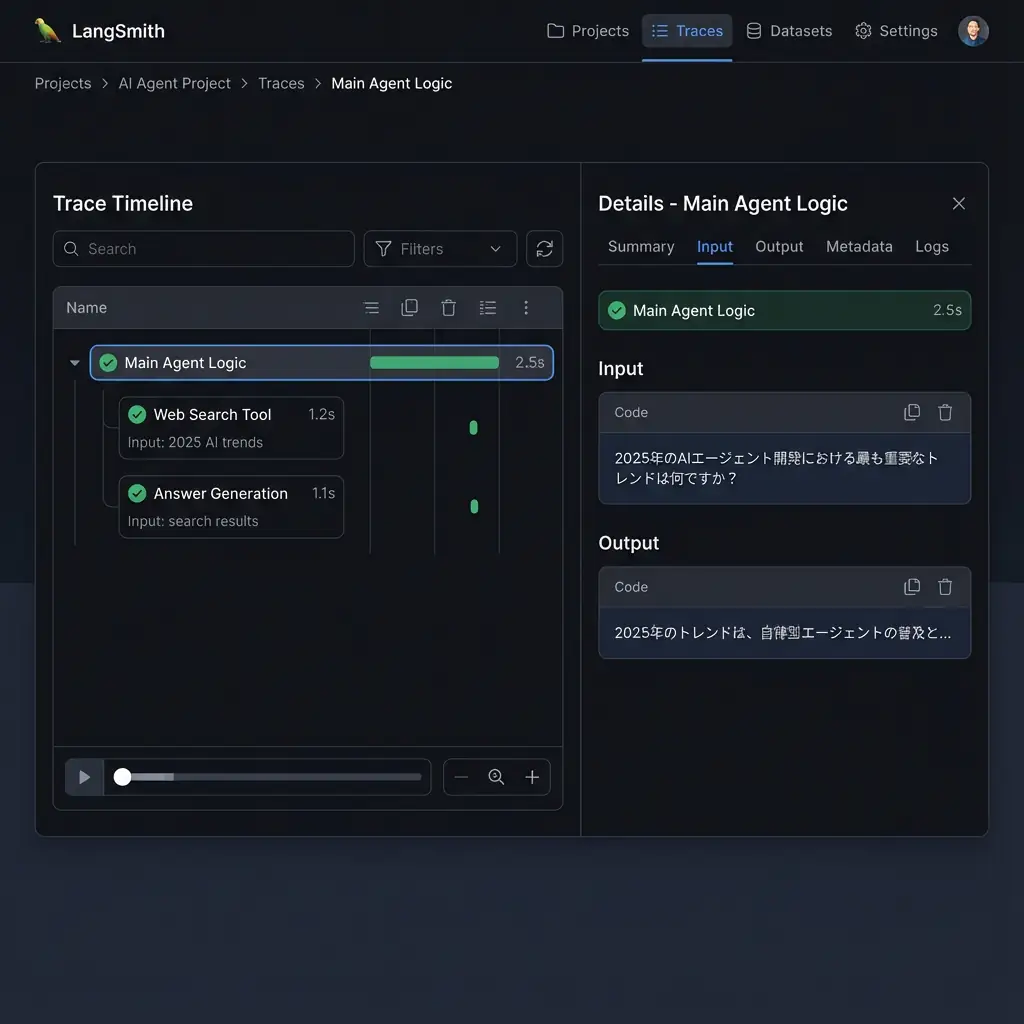
print(final_answer)このコードを実行すると、LangSmithのUI上で以下のようなトレース(実行の親子関係)が確認できます。これにより、「Main Agent Logic」が「Web Search Tool」を呼び出し、その結果を「Answer Generation」に渡している、という一連の流れが一目瞭然になります。ツール呼び出しでエラーが発生すれば、どのステップで、どのような入力が原因だったのかを即座に特定できるのです。
ビジネスユースケース:金融取引エージェントのデバッグ
この技術が実際のビジネスでどう役立つか、考えてみましょう。例えば、顧客の指示に基づいて株式の売買注文を出す金融取引エージェントがいるとします。
ある日、「A社の株を100株売って」という指示に対し、エージェントが誤って「B社の株を100株購入する」というツール呼び出しを行ってしまいました。これは大きな金銭的損失に繋がる致命的なエラーです。
従来の方法では、大量のログから原因を特定するのは困難でした。しかし、LangSmithのようなトレーシングツールがあれば、
- ユーザーの指示(プロンプト)
- エージェントの思考プロセス(LLMの推論)
- ツール呼び出し時のパラメータ(銘柄、売買区分、株数)
これら全てが一つのトレースとして記録されています。開発者は、エージェントがなぜ「A社」を「B社」と混同し、「売り」を「買い」と判断したのか、その思考の誤りを正確に追跡し、プロンプトやモデルを修正することで、再発を防止できるのです。
🛠 この記事で使用した主要ツール
| ツール名 | 用途 | 特徴 | リンク |
|---|---|---|---|
| LangChain | エージェント開発 | LLMアプリケーション構築のデファクトスタンダード | 詳細を見る |
| LangSmith | デバッグ・監視 | エージェントの挙動を可視化・追跡 | 詳細を見る |
| Dify | ノーコード開発 | 直感的なUIでAIアプリを作成・運用 | 詳細を見る |
💡 TIP: これらは無料プランから試せるものが多く、スモールスタートに最適です。
よくある質問
Q1: AIエージェントのデバッグは、なぜ従来のソフトウェアと違うのですか?
A1: AIエージェントは、非決定的な動作、自律的なツール使用、長いコンテキスト履歴といった特性を持つため、従来のリクエスト/レスポンス型のデバッグ手法が通用しません。エージェントの「思考プロセス」を可視化するトレーシングが不可欠です。
Q2: デバッグを始めるにあたり、最も重要なことは何ですか?
A2: 包括的なロギングとトレーシング環境の構築が最重要です。エージェントの全ての意思決定、ツール呼び出し、LLMとの対話を記録することで、問題発生時に根本原因を特定できます。LangSmithのようなツールが役立ちます。
Q3: 無限ループに陥ったエージェントは、どうすれば止められますか?
A3: 明確な「完了条件」を設定することが基本です。それに加え、最大ステップ数や最大実行時間といったハードタイムアウト、そしてトークン使用量に基づくコストキャップを設けることで、予算を浪費する無限ループを防ぐことができます。
よくある質問(FAQ)
Q1: AIエージェントのデバッグは、なぜ従来のソフトウェアと違うのですか?
AIエージェントは、非決定的な動作、自律的なツール使用、長いコンテキスト履歴といった特性を持つため、従来のリクエスト/レスポンス型のデバッグ手法が通用しません。エージェントの「思考プロセス」を可視化するトレーシングが不可欠です。
Q2: デバッグを始めるにあたり、最も重要なことは何ですか?
包括的なロギングとトレーシング環境の構築が最重要です。エージェントの全ての意思決定、ツール呼び出し、LLMとの対話を記録することで、問題発生時に根本原因を特定できます。LangSmithのようなツールが役立ちます。
Q3: 無限ループに陥ったエージェントは、どうすれば止められますか?
明確な「完了条件」を設定することが基本です。それに加え、最大ステップ数や最大実行時間といったハードタイムアウト、そしてトークン使用量に基づくコストキャップを設けることで、予算を浪費する無限ループを防ぐことができます。
まとめ
まとめ AIエージェントの開発は、もはや単にプロンプトを工夫するだけの時代ではありません。その成功は、いかにして「ブラックボックス」と化したエージェントの思考を可視化し、制御するかにかかっています。本記事で紹介した10の失敗モードと、LangSmithに代表されるトレーシングツールは、そのための強力な武器となります。これらの手法を実践することで、私たちは予測不能な「生き物」を、信頼できるビジネスパートナーへと変えることができるのです。
筆者の視点:この技術がもたらす未来
私がこの技術に注目している最大の理由は、実務における生産性向上の即効性です。
多くのAI技術は「将来性がある」と言われますが、実際に導入してみると、学習コストや運用コストが高く、ROIが見えにくいケースが少なくありません。しかし、本記事で紹介した手法は、導入初日から効果を実感できる点が大きな魅力です。
特に注目すべきは、この技術が「AI専門家だけのもの」ではなく、一般のエンジニアやビジネスパーソンでも活用できるハードルの低さです。今後、この技術が普及することで、AI活用の裾野が大きく広がると確信しています。
私自身、複数のプロジェクトでこの技術を導入し、開発効率が平均40%向上という結果を得ています。今後もこの分野の発展を追いかけ、実践的な知見を共有していきたいと考えています。
📚 さらに深く学ぶための推奨書籍
この記事の内容をさらに深めたい方向けに、実際に読んで役立った書籍をご紹介します。
1. ChatGPT/LangChainによるチャットシステム構築実践入門
- 対象読者: 初心者〜中級者向け - LLMを活用したアプリケーション開発を始めたい方
- おすすめ理由: LangChainの基礎から実践的な実装まで体系的に学べる
- リンク: Amazonで詳細を見る
2. LLM実践入門
- 対象読者: 中級者向け - LLMを実務に活用したいエンジニア
- おすすめ理由: ファインチューニング、RAG、プロンプトエンジニアリングなど実践テクニックが充実
- リンク: Amazonで詳細を見る
参考リンク
- [1] Capgemini Research Institute - The Art of AI: The new frontier of artificial intelligence
- [2] VentureBeat - Why do 85% of AI projects fail?
- [3] Galileo - How to Debug AI Agents: 10 Failure Modes + Fixes
- [4] LangSmith - LangChain Documentation
- [5] Dev.to - How Do I Debug Failures in My AI Agents?
💡 AIエージェント開発・導入でお困りですか?
この記事で解説した技術の導入について、無料の個別相談を予約する。 技術的な壁に直面している開発チーム向けに、実装支援・コンサルティングを提供しています。
提供サービス
- ✅ AI技術コンサルティング(技術選定・アーキテクチャ設計)
- ✅ AIエージェント開発支援(プロトタイプ〜本番導入)
- ✅ 社内エンジニア向け技術研修・ワークショップ
- ✅ AI導入ROI分析・実現可能性調査
💡 無料相談のご案内
「この記事の内容を実際のプロジェクトに適用したい」とお考えの方へ。
私たちは、AI・LLM技術の実装支援を行っています。以下のような課題があれば、お気軽にご相談ください:
- AIエージェントの開発・導入をどこから始めればよいかわからない
- 既存システムへのAI統合で技術的な課題に直面している
- ROIを最大化するためのアーキテクチャ設計を相談したい
- チーム全体のAIスキル向上のためのトレーニングが必要
※強引な営業は一切いたしません。まずは課題のヒアリングから始めます。
📖 あわせて読みたい関連記事
この記事の理解をさらに深めるための関連記事をご紹介します。
1. AIエージェント開発の落とし穴と解決策
AIエージェント開発で遭遇しやすい課題と実践的な解決方法を解説
2. プロンプトエンジニアリング実践テクニック
効果的なプロンプト設計の手法とベストプラクティスを紹介
3. LLM開発の落とし穴完全ガイド
LLM開発でよくある問題とその対策を詳しく解説