LLMを活用したシステム開発に携わって久しいですが、最近「ただ検索するだけのRAG」に対する限界を強く感じるようになりました。ユーザーからの質問が単純な事実確認(「〇〇の定義は?」)であれば、従来の検索拡張生成(RAG)で十分です。ベクトル検索で関連ドキュメントを引っ張ってきて、文脈と一緒にLLMに投げる。このシンプルな仕組みは多くの現場で功を奏しています。
しかし、現実のビジネスシーンで寄せられる質問はもっと複雑です。「A社とB社の昨年度の売上を比較し、市場動向を踏まえて来年の戦略を提案してほしい」といった具合に、複数の情報源を跨ぎ、計算や推論を必要とするタスクが増えています。従来のRAGでこれに対応しようとすると、検索クエリが曖昧になりすぎて精度が出なかったり、一度の検索では情報が不足して「知りません」と答えられてしまったりすることが少なくありません。
ここで登場するのが、LLMに「自律的なエージェント」としての役割を与えたAgentic RAGです。これは単なる検索ツールではなく、タスクを分解し、必要なアクションを繰り返し実行しながら答えを導き出す、画期的な転換点となる技術です。今回は、このAgentic RAGの仕組みと、実際に動作するPythonコードを交えながら、その可能性を探っていきたいと思います。
従来のRAGとAgentic RAGの構造的違い
まず、なぜ今この技術が必要なのか、既存手法との違いを整理しておきましょう。
従来のRAG(Retrieval-Augmented Generation)は、言わば「図書館での資料探し」に似ています。ユーザーが質問をすると、システムはキーワードや意味的類似性に基づいて関連書籍(ドキュメント)を探し出し、その内容を読み上げます。非常に効率的ですが、司書が「その質問に答えるには、この本とあの本の内容を組み合わせる必要がありますね」と判断して、複数の本を行き来しながら要約するようなことはしません。
一方、Agentic RAGは「優秀なアシスタント」です。質問を受け取ると、まず「この質問に答えるためには何が必要か?」を計画します。場合によってはWeb検索を行い、社内データベースを確認し、必要であれば計算ツールを使います。これら一連のアクションを**ReAct(Reasoning + Acting)**パターンと呼びます。
具体的な違いは以下の通りです。
- 従来のRAG: 静的で一度きりの検索。検索クエリの最適化が難しい。
- Agentic RAG: 動的で反復的なプロセス。検索、生成、評価のループを回すことで、必要な情報を段階的に収集・補完できる。
この自律的なループ処理こそが、複雑な推論タスクを可能にする鍵なのです。
Agentic RAGの内部動作と仕組み
Agentic RAGの中身をもう少し深掘りしてみましょう。その核心は、LLMを「オーケストラ指揮者」として機能させることにあります。
システムは大きく分けて、Planner(計画者)、Tools(道具箱)、**Executor(実行者)**の要素で構成されます。
- 思考と計画: ユーザーの問いに対し、LLMはまずゴールを設定します。例えば「Q4の売上報告書を作成する」というタスクであれば、「まず売上データを取得し、次に前年比を計算し、最後に要約する」というステップに分解します。
- ツールの選択と実行: 次に、各ステップを実行するために最適なツールを選びます。ツールには「ベクトル検索」「Web検索」「SQLクエリ」「Pythonコード実行」などが含まれます。LLMは自然言語でツールへの指示を出し、ツールは実行結果を返します。
- 観察と再考: ツールの実行結果(観察)を受け取り、LLMはそれが十分な情報かを判断します。不十分であれば、再度検索クエリを修正してツールを呼び出すか、別のツールを使用します。
- 最終回答: 十分な情報が揃ったと判断すると、LLMは収集した情報を統合し、ユーザーに対する最終的な回答を生成します。
このプロセスを図にすると、以下のようなフローになります。
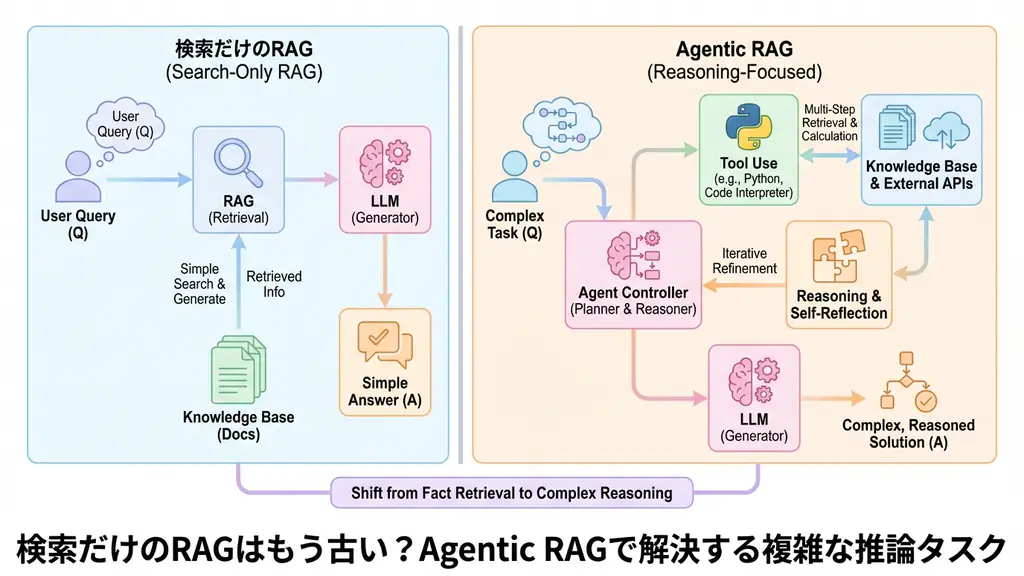
このループを回すことで、単なる検索では見つからなかった「隠れた答え」や「統合された洞察」を引き出すことが可能になります。
Pythonによる実装例:複数のデータソースを跨ぐ調査エージェント
それでは、実際に動作するコードを見ていきましょう。ここでは、OpenAIのAPIを使用し、社内ドキュメント(模擬)とWeb検索(模擬)を使い分けるシンプルなAgentic RAGを実装します。
擬似コードではなく、エラーハンドリングやロギングを含めた実用的な構成にします。
import logging
import json
from typing import List, Dict, Any, Optional
from openai import OpenAI
import time
# ロギングの設定
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class AgenticRAG:
def __init__(self, api_key: str):
self.client = OpenAI(api_key=api_key)
self.tools = self._define_tools()
def _define_tools(self) -> List[Dict[str, Any]]:
"""エージェントが使用可能なツールの定義"""
return [
{
"type": "function",
"function": {
"name": "search_internal_knowledge_base",
"description": "社内の技術ドキュメントやマニュアルを検索します。製品仕様や内部手順に関する質問に使用してください。",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "検索キーワード"
}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "search_web",
"description": "インターネット上の最新情報を検索します。市場動向や最新のニュース、外部の技術情報に使用してください。",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "検索キーワード"
}
},
"required": ["query"]
}
}
}
]
def _execute_tool(self, tool_name: str, arguments: Dict[str, Any]) -> str:
"""ツールの実行ロジック(モック実装)"""
logger.info(f"ツール実行中: {tool_name} 引数: {arguments}")
try:
if tool_name == "search_internal_knowledge_base":
# 実際にはベクトルDB等へのクエリが入ります
query = arguments.get("query", "")
if "API" in query:
return "社内APIドキュメントによると、エンドポイントは /api/v1/resource で、認証にはBearerトークンが必要です。"
else:
return "該当する社内ドキュメントは見つかりませんでした。"
elif tool_name == "search_web":
# 実際にはGoogle Search APIやBing API等が入ります
query = arguments.get("query", "")
if "Python" in query:
return "Python 3.12の最新情報では、パフォーマンスの向上とエラーメッセージの改善が図られています。"
else:
return "ウェブ上に関連する最新情報は見つかりませんでした。"
else:
return f"未知のツールが呼び出されました: {tool_name}"
except Exception as e:
logger.error(f"ツール実行エラー: {e}")
return f"エラーが発生しました: {str(e)}"
def run(self, user_query: str, max_turns: int = 5) -> str:
"""Agentic RAGのメインループ"""
messages = [
{"role": "system", "content": "あなたは有用なAIアシスタントです。利用可能なツールを使ってユーザーの質問に答えてください。"},
{"role": "user", "content": user_query}
]
for turn in range(max_turns):
logger.info(f"--- ターン {turn + 1} ---")
try:
# LLMによる応答生成(ツール呼び出し判断含む)
response = self.client.chat.completions.create(
model="gpt-4o", # または利用可能なモデル
messages=messages,
tools=self.tools,
tool_choice="auto" # モデルにツールを使うか自動判断させる
)
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
# ツール呼び出しがなければ最終回答とみなす
if not tool_calls:
logger.info("最終回答が生成されました。")
return response_message.content
# ツール呼び出しの結果を処理
messages.append(response_message) # モデルのツール呼び出し要求を履歴に追加
for tool_call in tool_calls:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments)
# ツール実行
function_response = self._execute_tool(function_name, function_args)
# 実行結果を履歴に追加
messages.append(
{
"tool_call_id": tool_call.id,
"role": "tool",
"name": function_name,
"content": function_response,
}
)
except Exception as e:
logger.error(f"LLM推論中に例外発生: {e}")
messages.append({
"role": "system",
"content": f"前回の処理でエラーが発生しました。エラー内容: {str(e)}。別のアプローチを試してください。"
})
return "最大ターン数に達しましたが、回答を導き出せませんでした。"
# 実行例
if __name__ == "__main__":
# 環境変数等からAPIキーを取得してください
import os
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
print("OPENAI_API_KEYが設定されていません。")
else:
agent = AgenticRAG(api_key=api_key)
# 複雑な質問:社内情報と外部情報の両方が必要なケース
query = "自社のAPI仕様を確認した上で、Pythonの最新バージョンでそれを実装する際の注意点を教えてください。"
answer = agent.run(query)
print(f"\n最終回答:\n{answer}")このコードでは、run メソッド内で max_turns までループを回しています。LLMが「社内API仕様」が必要だと判断すれば search_internal_knowledge_base を呼び出し、「Pythonの最新情報」が必要なら search_web を呼び出します。このように、一つの質問に対して複数のツールを組み合わせて答えに迫る様子が確認できるはずです。
ビジネスユースケース:カスタマーサポートの自動応用強化
Agentic RAGの技術は、特にカスタマーサポート領域で大きな効果を発揮します。具体的なユースケースを紹介します。
ケース:通信キャリアの複雑な課金トラブル対応
従来のチャットボットは、FAQからの検索結果を表示するだけでした。例えば「請求額が高い」という問い合わせに対し、「請求内訳の確認方法」のページを案内する程度です。しかし、ユーザーは「なぜ高いのか」という理由を知りたいのです。
Agentic RAGを導入すると、以下のような対応が可能になります。
- ユーザー認証とデータ取得: まずユーザーを特定し、課金システム(API)へアクセスして今月の通話明細データを取得します。
- データ分析: 取得した明細データをPythonツールで解析し、前月比での増加分や、特定の有料サービスへの加入状況を確認します。
- 外部要因の確認: もし国際電話などの料金が高い場合、最新の為替レートや国際ローミング料金の改定情報をWeb検索で補足します。
- 回答の生成: 「先月の海外旅行時に国際ローミングを使用したため、基本料金に加えて〇〇円の通信費が発生しています。詳細は以下の通りです…」という、根拠に基づいた具体的な説明を生成します。
このように、単なる検索では不可能だった「個別の状況に応じた原因究明と提案」が自動化できるため、カスタマーサポート担当者の負担を大幅に軽減し、顧客満足度の向上につながります。
よくある質問
- Q: 従来のRAGとAgentic RAGの最大の違いは何ですか? A: 従来のRAGが「検索→生成」の一度きりのプロセスであるのに対し、Agentic RAGはLLMがタスクを計画し、必要なツールを何度も呼び出しながら情報を収集・統合して答えを導き出す反復的なプロセスである点です。
- Q: Agentic RAGを導入する際のコストやレイテンシはどうなりますか? A: LLMの推論回数が増えるため、トークンコストと応答時間は従来のRAGより高くなる傾向にあります。しかし、複雑な問い合わせに対する回答精度が劇的に向上するため、トータルでの業務効率や顧客満足度向上という観点で正当化できるケースが多いです。
- Q: 実装にはどのようなフレームワークを使えばよいですか? A: LangChainやLlamaIndexなどの主要なライブラリがAgentic RAGの機能をサポートしていますが、より細かい制御が必要な場合は、今回の実装例のようにOpenAIのFunction Calling機能を直接活用して独自のループを構築するのがおすすめです。
- Q: ハルシネーション(嘘)のリスクは高まりませんか? A: ツールの実行結果に基づいて回答するため、LLMが独自に事実を捏造するリスクは軽減されます。しかし、ツールの選択ミスや結果の読み違えは起こり得るため、最終的な出力に対するガードレール(事実確認ロジックなど)を設けることが重要です。
まとめ
- 従来のRAGの限界: 単一の検索では、複数の情報源を統合したり、多段階の推論を行ったりすることが難しい。
- Agentic RAGの定義: LMが計画・実行・観察のループを回し、自律的にツールを使いこなすことで複雑なタスクを解決する仕組み。
- 実装のポイント: OpenAIのFunction Callingなどを活用し、エラーハンドリングやループ制御を適切に行うことが安定した動作に不可欠。
- ビジネスインパクト: カスタマーサポートや市場分析など、高度な判断が必要な業務において、人間に近い柔軟な対応を自動化できる。
推奨リソース
- LangChain LLMアプリケーション開発のための包括的なフレームワーク。Agents機能によりAgentic RAGの構築を大幅に簡略化できます。
- LlamaIndex データ接続に特化したライブラリ。特にRAGとエージェントの融合部分において、高度なインデックス管理機能を提供しています。
AI導入支援・開発のご相談
Agentic RAGの導入や、LLMを活用した独自のエージェント開発でお困りではありませんか?当社では、技術選定から設計、実装、運用保守まで、一貫したサポートを提供しています。貴社のビジネス課題に合わせた最適なAIソリューションをご提案しますので、お気軽にご相談ください。
参考リンク
[1]OpenAI Function Calling Documentation [2]ReAct: Synergizing Reasoning and Acting in Language Models [3]LangGraph: Building Cyclic Agents