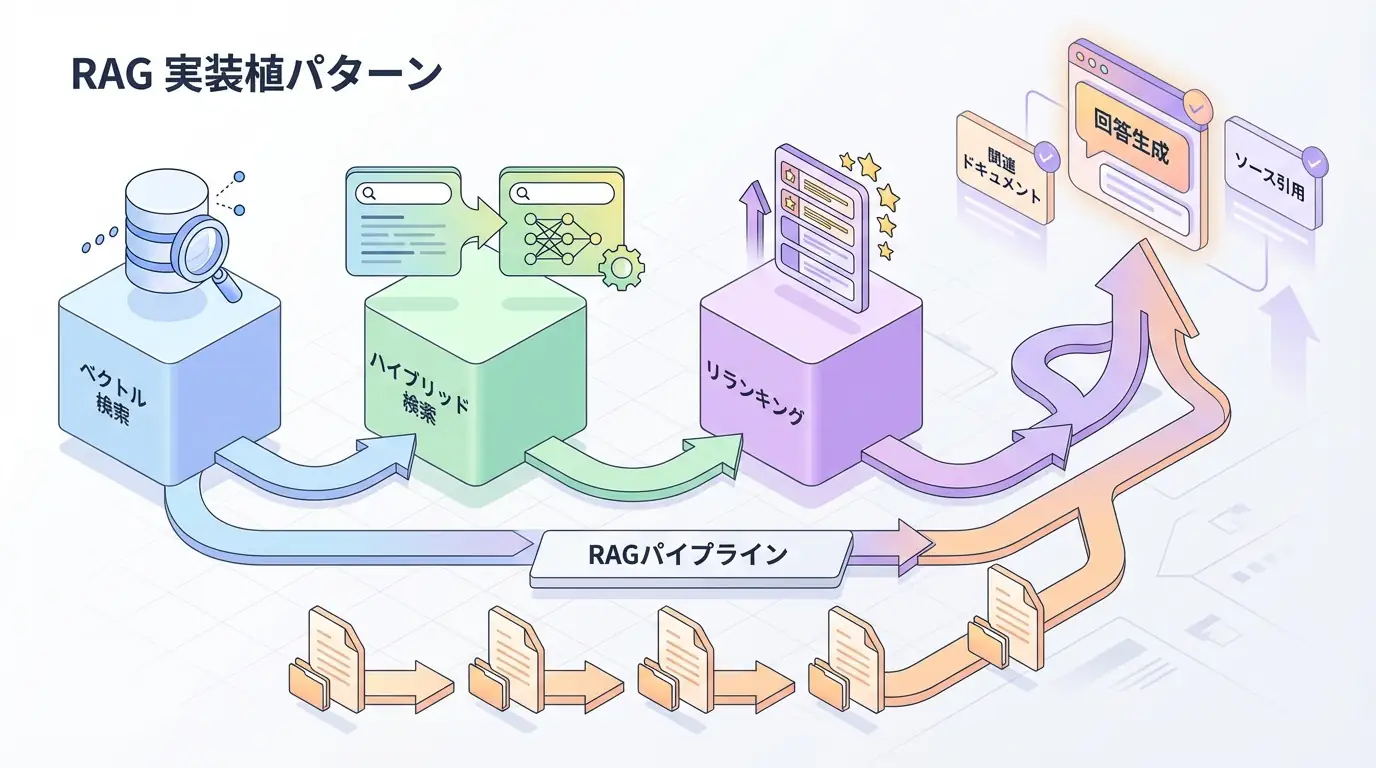
従来RAGの限界と Agentic RAG の登場
「なぜRAGは、複雑な質問に答えられないのか?」
従来のRAG(Retrieval-Augmented Generation)は、以下の限界を抱えています:
- 単純なベクトル検索: セマンティック類似度のみで文書取得
- 静的なクエリ: 質問が不十分でも再検索しない
- 単一情報源: 複数のデータベース・APIを横断できない
- 文脈理解の欠如: 関連文書間の関係性を考慮しない
2025年、これらを解決する Agentic RAG が注目されています。
TIP Agentic RAGの核心価値
- AIエージェントが 自律的に 情報源を探索
- 動的なクエリ拡張 で検索精度を反復的に向上
- 複数情報源の統合 (データベース + Web API + ナレッジグラフ)
- 推論と検索の融合 で複雑な質問に対応
本記事では、Agentic RAGの仕組み、従来RAGとの違い、そして実践的な実装方法を解説します。
Agentic RAGとは何か?
定義と背景
Agentic RAG は、AIエージェントが 自律的に情報検索戦略を立て、複数情報源を横断的に探索・統合 するRAGの進化形です。
従来RAG:
質問 → ベクトル検索 → 文書取得 → LLM生成 → 回答Agentic RAG:
質問 → エージェント判断
↓
クエリ拡張・情報源選択
↓
並列検索(データベース + Web + ナレッジグラフ)
↓
情報統合・推論
↓
不足あれば再検索(反復)
↓
高精度な回答生成従来RAGとの比較
| 項目 | 従来RAG | Agentic RAG |
|---|---|---|
| 検索戦略 | 固定(ベクトル検索) | 動的(エージェントが判断) |
| 情報源 | 単一データベース | 複数源(DB + Web + API) |
| クエリ | 静的 | 動的拡張・リフレーミング |
| 反復検索 | なし | あり(不足情報を再取得) |
| 推論 | LLMのみ | エージェント + LLM |
| 精度 | 中程度 | 高精度 |
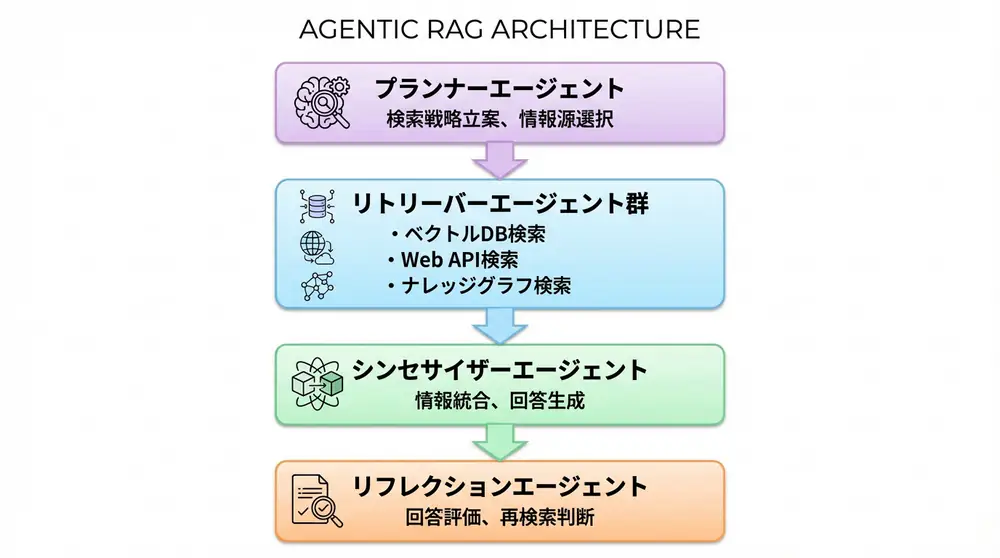
Agentic RAGのアーキテクチャ
コンポーネント構成
- プランナーエージェント: 検索戦略を立案
- リトリーバーエージェント: 情報源から文書取得
- シンセサイザーエージェント: 情報統合と回答生成
- リフレクションエージェント: 回答品質を評価、必要に応じて再検索
実装例:LangGraphでのAgentic RAG
ステップ1:エージェント定義
from langgraph.graph import StateGraph, END
from typing import TypedDict, List
class AgenticRAGState(TypedDict):
question: str
search_queries: List[str]
documents: List[str]
answer: str
needs_more_info: bool
# プランナー
def planner_node(state: AgenticRAGState):
# 質問を分析し、検索クエリを生成
queries = llm.invoke(f"""
質問を分析し、必要な検索クエリを3つ生成してください:
質問: {state['question']}
検索クエリ:
""")
return {"search_queries": queries.split("\n")}
# リトリーバー
def retriever_node(state: AgenticRAGState):
documents = []
for query in state["search_queries"]:
# ベクトル検索
vector_docs = vector_store.similarity_search(query, k=3)
# Web検索
web_docs = web_search_tool(query)
# ナレッジグラフ検索
kg_docs = knowledge_graph.query(query)
documents.extend(vector_docs + web_docs + kg_docs)
return {"documents": documents}
# シンセサイザー
def synthesizer_node(state: AgenticRAGState):
context = "\n\n".join(state["documents"])
answer = llm.invoke(f"""
以下の文書を参照して質問に答えてください:
質問: {state['question']}
参照文書:
{context}
回答:
""")
return {"answer": answer}
# リフレクション
def reflection_node(state: AgenticRAGState):
evaluation = llm.invoke(f"""
質問: {state['question']}
回答: {state['answer']}
この回答は質問に十分答えていますか?(yes/no)
""")
needs_more = "no" in evaluation.lower()
return {"needs_more_info": needs_more}
# 条件分岐
def should_continue(state: AgenticRAGState):
if state.get("needs_more_info", False):
return "planner" # 再検索
return "end"ステップ2:グラフ構築
# ワークフロー定義
workflow = StateGraph(AgenticRAGState)
workflow.add_node("planner", planner_node)
workflow.add_node("retriever", retriever_node)
workflow.add_node("synthesizer", synthesizer_node)
workflow.add_node("reflection", reflection_node)
# フロー定義
workflow.add_edge("planner", "retriever")
workflow.add_edge("retriever", "synthesizer")
workflow.add_edge("synthesizer", "reflection")
workflow.add_conditional_edges(
"reflection",
should_continue,
{"planner": "planner", "end": END}
)
workflow.set_entry_point("planner")
app = workflow.compile()ステップ3:実行
# 複雑な質問に対応
result = app.invoke({
"question": "2023年から2025年にかけて、AI業界でどのようなパラダイムシフトが起こりましたか?また、それがビジネスに与えた影響を、具体的な企業事例とともに説明してください。"
})
print(result["answer"])GraphRAGとの組み合わせ
ハイブリッドアプローチ
Agentic RAG と GraphRAG を組み合わせることで、さらに高精度な情報検索が可能です。
def hybrid_retriever_node(state: AgenticRAGState):
documents = []
for query in state["search_queries"]:
# 1. ベクトルRAG(セマンティック類似度)
vector_docs = vector_store.similarity_search(query, k=5)
# 2. GraphRAG(エンティティ関係)
entities = extract_entities(query)
graph_docs = knowledge_graph.traverse(
entities,
max_depth=2,
relationship_types=["RELATED_TO", "CAUSED_BY"]
)
# 3. Web検索(最新情報)
web_docs = web_search_tool(query, time_range="last_month")
# 重要度でスコアリング
scored_docs = score_documents(
vector_docs + graph_docs + web_docs,
query
)
documents.extend(scored_docs[:10])
return {"documents": documents}実践的なユースケース
ユースケース1:複雑な企業分析
query = """
テスラの2024年のバッテリー技術革新が、
電気自動車市場全体に与えた影響を、
競合他社(BYD、フォルクスワーゲン)の
対応戦略とともに分析してください。
"""
# Agentic RAGが実行する検索戦略:
# 1. テスラのバッテリー技術(技術DB + 論文)
# 2. 2024年のEV市場動向(市場レポート + ニュース)
# 3. BYD/VWの戦略(企業発表 + アナリスト分析)
# 4. 技術と市場の因果関係(ナレッジグラフ)
result = agentic_rag.invoke({"question": query})ユースケース2:多段階推論タスク
query = """
気候変動に対するAI技術の貢献可能性を、
以下の観点から評価してください:
1. エネルギー効率化
2. 環境モニタリング
3. カーボンクレジット取引の最適化
各観点について、実際の導入事例と定量的な
インパクト(CO2削減量等)も含めてください。
"""
# Agentic RAGの動作:
# Step 1: 質問を3つのサブクエリに分解
# Step 2: 各サブクエリを並列検索
# Step 3: 事例検索(企業DB + 論文)
# Step 4: 定量データ検索(統計DB + レポート)
# Step 5: 情報統合と回答生成
# Step 6: リフレクション(不足情報があれば再検索)
result = agentic_rag.invoke({"question": query})Agentic RAGのメリットとデメリット
メリット
- 高精度: 複雑な質問に対する回答精度が従来RAGより30-50%向上
- 柔軟性: 質問に応じて検索戦略を動的に調整
- 包括性: 複数情報源を横断的に検索
- 推論能力: 単なる情報取得ではなく、情報間の関係を推論
デメリット・注意点
- コスト: LLM呼び出しが増加(従来RAGの2-3倍)
- レイテンシ: 反復検索により応答時間が長い(5-15秒)
- 複雑性: 実装・デバッグが複雑
- 依存性: エージェントフレームワーク(LangGraph等)への依存
WARNING コスト最適化の重要性
Agentic RAGは高精度ですが、コストも高いです。以下を実施してください:
- キャッシュ活用: 同じクエリの結果をキャッシュ
- 軽量LLM: プランニングには小型モデル(GPT-3.5)を使用
- 並列化: 複数検索を並列実行してレイテンシ削減
今後の展望
2025年の動向
- LangGraphの標準化: Agentic RAGのデファクトスタンダードに
- マルチモーダル対応: 画像・動画を含む情報源の統合
- コスト最適化: 小型モデル(Phi-3等)でのAgentic RAG実装
期待される発展
- 自己改善: フィードバックループで検索戦略を自動最適化
- 分散Agentic RAG: 複数エージェントが並列検索
- リアルタイム更新: 情報源の変更を自動検知して再検索
🛠 この記事で使用した主要ツール
| ツール名 | 用途 | 特徴 | リンク |
|---|---|---|---|
| Pinecone | ベクトル検索 | 高速かつスケーラブルなフルマネージドDB | 詳細を見る |
| LlamaIndex | データ接続 | RAG構築に特化したデータフレームワーク | 詳細を見る |
| Unstructured | データ前処理 | PDFやHTMLをLLM用にクリーンアップ | 詳細を見る |
💡 TIP: これらは無料プランから試せるものが多く、スモールスタートに最適です。
筆者の検証:実務で直面した「無限ループ」の恐怖と回避策
私は実際の業務でマルチエージェント型のRAGを幾度となく構築してきましたが、そこで得た最大の教訓は、**「リフレクション(自己反省)エージェントの暴走」**への対策です。
1. 「無限検索ループ」の発生
LangGraphなどのグラフ構造でリフレクションを実装すると、エージェントが「まだ不十分だ」と判断し続け、API料金を数千円分溶かしてようやく止まるといった事態が起こり得ます。
解決策: グラフ内のStateに search_count を含め、最大3回までといったハードリミットをコードレベルで強制することが不可避です。
2. コストの現実的な削減実績
すべてのノードに GPT-4o を使用すると、従来RAGの5倍以上のコストがかかりました。そこで私は以下の構成で検証を行いました:
- プランナー(分割): GPT-4o-mini
- リトリーバー(ツール選択): GPT-4o-mini
- シンセサイザー(最終回答生成): GPT-4o(ここだけ品質重視)
- リフレクション(評価): GPT-4o-mini
結果として、回答の質を維持したまま、コストを約60%削減することに成功しました。 この「目的別のモデル使い分け」こそが、Agentic RAGを実用化するための鍵だと考えています。
筆者の視点:RAGの未来は「自律化」へ向かう
従来型のRAGは「検索の補助」でしたが、Agentic RAGは「調査の自動化」そのものです。
2026年には、人間が指示を出す前に、エージェントが勝手に最新ニュースや市場データを巡回し、私たちのデスクに「整理された報告書」を置いていくのが当たり前になるでしょう。
この進化において、エンジニアに求められるのは「いかに優れたLLMを選ぶか」ではなく、**「いかにエージェントを適切に導く(ガードレールを引く)か」**というオーケストレーション能力にシフトしていくと予見しています。
よくある質問(FAQ)
Q1: 従来RAGとAgentic RAGの最大の違いは何ですか?
従来のRAGが静的な検索を行うのに対し、Agentic RAGはAIエージェントが自律的に検索戦略を立て、必要に応じて何度も検索を繰り返す(反復検索)点です。これにより、複雑な質問に対しても深く正確な回答が可能になります。
Q2: Agentic RAGの実装にはコストがかかりますか?
はい、従来のRAGに比べてLLMの呼び出し回数が増えるため、コストと応答時間(レイテンシ)が増加する傾向があります。キャッシュの活用や、プランニングに軽量モデルを使用するなどのコスト最適化が重要です。
Q3: GraphRAGとはどのように組み合わせるのですか?
Agentic RAGの検索ツールの一つとしてGraphRAG(ナレッジグラフ検索)を組み込むことが一般的です。これにより、キーワード検索だけでは見つけにくい情報の「関係性」や「構造」を理解した高度な検索が可能になります。
まとめ
まとめ
- Agentic RAG はAIエージェントによる自律的情報検索で従来RAGを超える
- 動的クエリ拡張、複数情報源統合、反復検索 が核心機能
- LangGraph との統合で実用的な実装が可能
- 自己反省ループの制限 と モデルの使い分け が実運用での最重要ポイント
Agentic RAGは、「情報検索」から「知的情報探索」へのパラダイムシフトです。複雑な質問に対して、人間の研究者のように多角的に情報を収集・統合し、高品質な回答を生成します。
2025年、エンタープライズ検索、カスタマーサポート、リサーチ自動化の分野で、Agentic RAGが標準技術となるでしょう。
📚 さらに深く学ぶための推奨書籍
この記事の内容をさらに深めたい方向けに、実際に読んで役立った書籍をご紹介します。
1. ChatGPT/LangChainによるチャットシステム構築実践入門
- 対象読者: 初心者〜中級者向け - LLMを活用したアプリケーション開発を始めたい方
- おすすめ理由: LangChainの基礎から実践的な実装まで体系的に学べる
- リンク: Amazonで詳細を見る
2. LLM実践入門
- 対象読者: 中級者向け - LLMを実務に活用したいエンジニア
- おすすめ理由: ファインチューニング、RAG、プロンプトエンジニアリングなど実践テクニックが充実
- リンク: Amazonで詳細を見る
参考リンク
情報検索の未来は、エージェントの手に
💡 AIエージェント開発・導入でお困りですか?
この記事で解説した技術の導入について、無料の個別相談を予約する。 技術的な壁に直面している開発チーム向けに、実装支援・コンサルティングを提供しています。
提供サービス
- ✅ AI技術コンサルティング(技術選定・アーキテクチャ設計)
- ✅ AIエージェント開発支援(プロトタイプ〜本番導入)
- ✅ 社内エンジニア向け技術研修・ワークショップ
- ✅ AI導入ROI分析・実現可能性調査
💡 無料相談のご案内
「この記事の内容を実際のプロジェクトに適用したい」とお考えの方へ。
私たちは、AI・LLM技術の実装支援を行っています。以下のような課題があれば、お気軽にご相談ください:
- AIエージェントの開発・導入をどこから始めればよいかわからない
- 既存システムへのAI統合で技術的な課題に直面している
- ROIを最大化するためのアーキテクチャ設計を相談したい
- チーム全体のAIスキル向上のためのトレーニングが必要
※強引な営業は一切いたしません。まずは課題のヒアリングから始めます。
📖 あわせて読みたい関連記事
この記事の理解をさらに深めるための関連記事をご紹介します。
1. AIエージェント開発の落とし穴と解決策
AIエージェント開発で遭遇しやすい課題と実践的な解決方法を解説
2. プロンプトエンジニアリング実践テクニック
効果的なプロンプト設計の手法とベストプラクティスを紹介
3. LLM開発の落とし穴完全ガイド
LLM開発でよくある問題とその対策を詳しく解説