Quantization
Categories
Tags

LLM Inference Optimization: Practical Techniques to Dramatically Improve Latency and Cost
Comprehensive guide to solving LLM production challenges with quantization, speculative decoding, vLLM, and other cutting-edge techniques to dramatically reduce inference costs and latency.
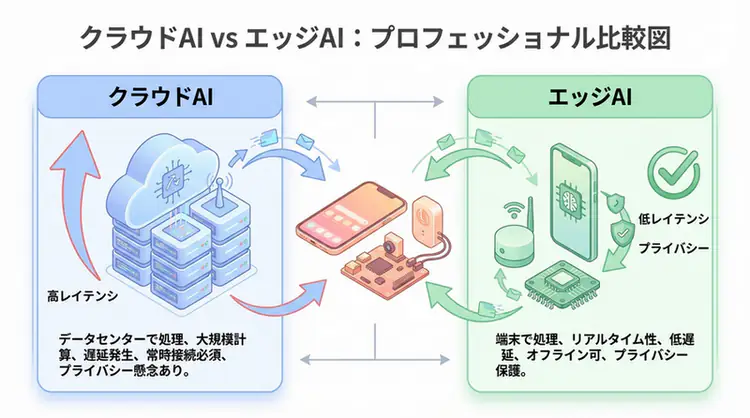
Edge AI Practical Guide - Device Deployment of Small Language Models
Achieve local AI execution on smartphones, IoT, and embedded systems with 1B-8B parameter SLMs like Phi-3, Gemma, and Qwen2. Comprehensive explanation of quantization techniques, privacy protection, and 13ms latency implementation methods.