Inference Optimization
Categories
Tags
Mixture of Experts (MoE) Implementation Guide - Next-Gen LLM Architecture Balancing Efficiency and Performance
Struggling with LLM inference costs and memory usage? This article provides a practical guide to Mixture of Experts (MoE), explaining how to combine multiple expert models with concrete code examples to achieve both performance and efficiency.
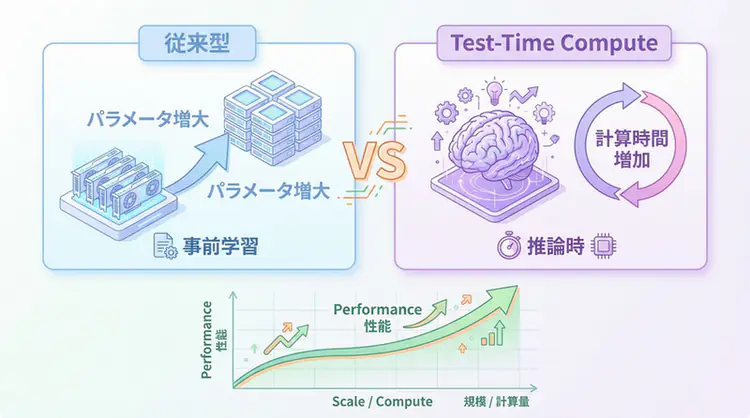
Test-Time Compute (TTC) Complete Guide - The New Era of AI Inference That 'Thinks Fast and Deep'
A comprehensive explanation of the technical mechanisms behind Test-Time Compute (TTC) represented by OpenAI o1. A complete guide for AI engineers to implement in practice, covering Best-of-N, reward models with PRM/ORM, and adaptive computation implementation patterns.