Introduction: From “Seeing” AI to “Understanding” AI
“Describe what’s in this image” “Read and analyze the numbers in this chart” “Determine if there are any quality issues with this product”
Conventional AI was dominated by LLMs (Large Language Models) that processed only text. However, much of the information in the real world exists as visual information such as images and videos.
From 2024 to 2025, Vision Language Models (VLM), multimodal AI that can simultaneously understand images and text, evolved explosively. Major models like GPT-4V, Gemini 2.5, and Claude 3.7 have achieved “semantic understanding of images” beyond simple object detection.
This article thoroughly explains VLM mechanisms, comparisons of major models, implementation methods, and business use cases.
What are Vision Language Models (VLM)?
Definition
Vision Language Models (VLM) are AI models that can integratively process both visual information (images/videos) and language information (text). In Japanese, they are called “large-scale visual language models”.
LLM vs VLM: What’s the Difference?
| Item | LLM (Large Language Model) | VLM (Vision Language Model) |
|---|---|---|
| Input | Text only | Text + images/videos |
| Processing | Language semantic understanding and generation | Integrated understanding of visual information and language |
| Output | Text | Text (image descriptions, analysis results, etc.) |
| Main Uses | Chatbots, text generation, translation | Image search, OCR, quality inspection, medical diagnosis |
| Examples | GPT-4, Claude 3 | GPT-4V, Gemini Pro Vision, Claude 3.5 Sonnet |
What VLM Enables
VLM has capabilities that far exceed traditional “image recognition AI”:
Detailed image descriptions
- Not just labeling (“cat”, “car”), but contextual descriptions of entire scenes
Visual Question Answering (VQA)
- Answering questions like “What’s the most prominent object in this image?” or “How many people are present?”
OCR + semantic understanding
- Not just reading text, but understanding document content for summarization and analysis
Inference and judgment
- Professional judgments like “Does this product have defects?” or “Are there abnormalities in this X-ray image?”
Creative analysis
- UI/UX design evaluation, advertising creative improvement suggestions
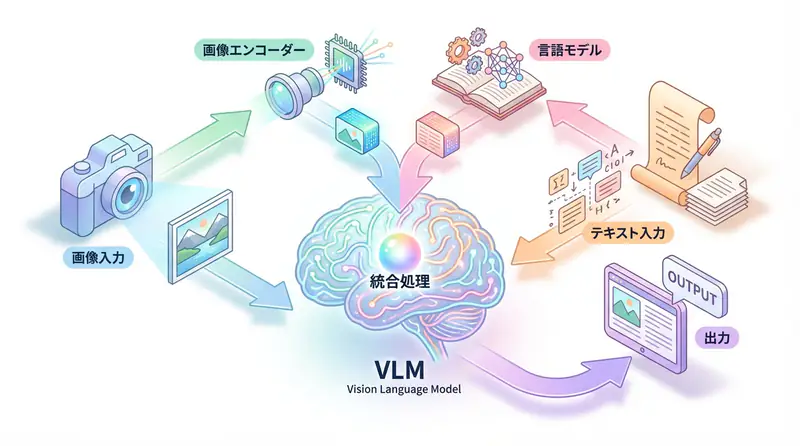
VLM Architecture: How Do They “Understand” Images?
VLM is mainly composed of three components.
1. Vision Encoder
Converts images into numerical representations (vectors) that AI can process.
Main technologies:
- Vision Transformer (ViT): Divides images into patches (small regions) and processes them with a Transformer structure
- CLIP (Contrastive Language-Image Pre-training): Trains on large amounts of image-text pairs to acquire visual-language correspondence
[Image] → [Vision Encoder] → [Image Embedding Vector]2. Language Model
The part that understands and generates text. Powerful LLMs like GPT, Gemini, and Claude are used.
[Text] → [Language Model] → [Text Embedding Vector]3. Fusion Layer (Multimodal Integration)
Integrates image embeddings and text embeddings, generating output that considers both types of information.
[Image Vector] + [Text Vector] → [Integration Processing] → [Output Text]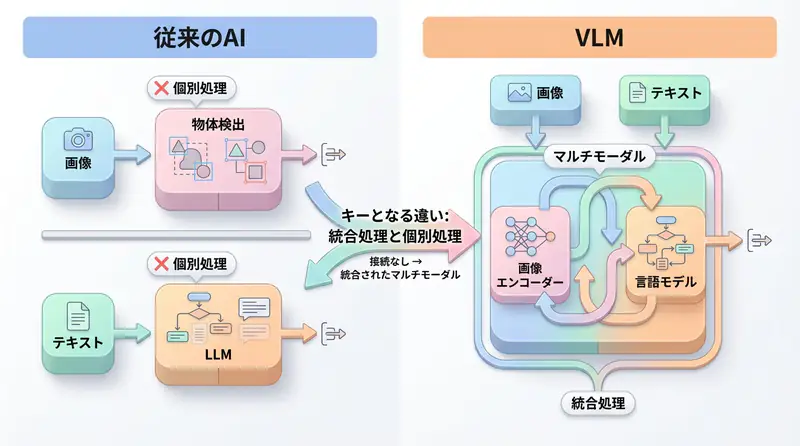
Representative VLM Architectures
CLIP (OpenAI)
- Features: Contrastive learning of image-text pairs
- Uses: Zero-shot image classification, image search
- Training method: Maximizes similarity of correct image-text pairs, minimizes incorrect pairs
LLaVA (Large Language and Vision Assistant)
- Features: Vicuna (LLaMA-based LLM) + CLIP Vision Encoder
- Uses: Visual Instruction Following (executing instructions for images)
- Strengths: Open source, lightweight, fine-tunable
Flamingo (DeepMind)
- Features: Excels at few-shot learning (adapting to new tasks with few examples)
- Uses: Image caption generation, VQA
- Strengths: Processing long image-text sequences
Major VLM Model Comparison (2025 Edition)
GPT-4V (GPT-4 with Vision)
Developer: OpenAI
Features:
- Most versatile VLM
- Enables natural dialogue combining images and text
- Excels at detailed image descriptions, inference, and creative analysis
Performance:
- MMMU (college-level multimodal understanding): 56.8%
- MathVista (visual math reasoning): 49.9%
Pricing:
- Input: $0.01 / image (up to $0.0765 for high resolution)
- Output: $0.03 / 1K tokens
Applications:
- General image analysis
- UI/UX design reviews
- Educational content generation
Gemini 2.5 Pro / Flash (Google)
Developer: Google DeepMind
Features:
- Excels at long context processing (up to 2 million tokens)
- Can analyze videos
- Flash model optimized for real-time processing
Performance:
- MMMU: 62.4% (Pro)
- MathVista: 63.9% (Pro)
Pricing:
- Pro: $7.00 / 1 million tokens (input)
- Flash: $0.30 / 1 million tokens (input)
Applications:
- Long video analysis
- Document processing with many images
- Real-time applications (Flash)
Claude 3.7 Sonnet (Anthropic)
Developer: Anthropic
Features:
- Most accurate and reliable image understanding
- Excels at interpreting complex charts and graphs
- Strong ethical considerations (prevention of harmful content generation)
Performance:
- MMMU: 68.3%
- MathVista: 67.7%
Pricing:
- Input: $3.00 / 1 million tokens
- Output: $15.00 / 1 million tokens
Applications:
- Scientific paper chart analysis
- Medical image diagnostic assistance
- Business report visualization analysis
LLaVA (Open Source)
Developer: University of Wisconsin-Madison, etc.
Features:
- Completely open source
- Fine-tunable
- Can run in local environments
Performance:
- MMMU: 45.3% (LLaVA-1.6-34B)
- ScienceQA: 92.5%
Pricing: Free (self-hosted)
Applications:
- Privacy-focused systems
- Domain-specific tasks requiring customization
- Cost reduction priority cases
Comparison Table
| Model | Developer | MMMU | Cost | Strengths |
|---|---|---|---|---|
| GPT-4V | OpenAI | 56.8% | Medium | Versatility, ease of use |
| Gemini 2.5 Pro | 62.4% | High | Long context, video | |
| Gemini Flash | - | Low | Speed, real-time | |
| Claude 3.7 | Anthropic | 68.3% | Medium | Accuracy, ethics |
| LLaVA | OSS | 45.3% | Free | Open source, customization |
VLM Implementation Methods
Using OpenAI GPT-4V
from openai import OpenAI
import base64
client = OpenAI(api_key="YOUR_API_KEY")
# Encode image to Base64
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Image analysis
def analyze_image(image_path, prompt):
base64_image = encode_image(image_path)
response = client.chat.completions.create(
model="gpt-4o", # Successor to gpt-4-vision-preview
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
max_tokens=500
)
return response.choices[0].message.content
# Example usage
result = analyze_image(
"product_image.jpg",
"Please analyze this product image and check for any quality issues."
)
print(result)Using Google Gemini Pro Vision
import google.generativeai as genai
from PIL import Image
genai.configure(api_key="YOUR_API_KEY")
# Gemini Pro Vision model
model = genai.GenerativeModel('gemini-2.5-pro-vision')
# Load image
image = Image.open("document.jpg")
# Image + text prompt
prompt = """
Read the table in this image and output the data in structured JSON format.
"""
response = model.generate_content([prompt, image])
print(response.text)Using Claude 3.7 Sonnet
import anthropic
import base64
client = anthropic.Anthropic(api_key="YOUR_API_KEY")
# Read image
with open("chart.png", "rb") as image_file:
image_data = base64.standard_b64encode(image_file.read()).decode("utf-8")
message = client.messages.create(
model="claude-3-7-sonnet-20250219",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/png",
"data": image_data,
},
},
{
"type": "text",
"text": "Please analyze the trends in this chart and provide three key insights."
}
],
}
],
)
print(message.content[0].text)Using LLaVA (Open Source)
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
import torch
from PIL import Image
# Load model and processor
processor = LlavaNextProcessor.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf")
model = LlavaNextForConditionalGeneration.from_pretrained(
"llava-hf/llava-v1.6-mistral-7b-hf",
torch_dtype=torch.float16,
device_map="auto"
)
# Image and prompt
image = Image.open("image.jpg")
prompt = "[INST] <image>\nWhat's in this image? Please explain in detail. [/INST]"
inputs = processor(prompt, image, return_tensors="pt").to("cuda")
# Inference
output = model.generate(**inputs, max_new_tokens=200)
result = processor.decode(output[0], skip_special_tokens=True)
print(result)Business Use Cases
1. Manufacturing: Quality Inspection Automation
Challenge: Manual product外观 inspection is time-consuming and inconsistent
VLM Application:
# Analyze product image
defect_check = analyze_image(
"product_123.jpg",
"""
Please inspect this product image and check for the following:
1. Presence of scratches or dirt
2. Dimensional abnormalities
3. Color unevenness
4. Assembly defects
Determine the inspection result as "Pass", "Needs Review", or "Fail" and explain the reason.
"""
)Results:
- 50% reduction in inspection time
- 70% reduction in oversight rate
- 24/7 quality management possible
2. Healthcare: Diagnostic Support
Challenge: Long waiting times for image diagnosis due to doctor shortages
VLM Application:
# Preliminary X-ray analysis
preliminary_diagnosis = analyze_image(
"xray_001.jpg",
"""
Please analyze this X-ray image and determine:
1. Identification of suspicious areas
2. Type of abnormality (fracture, inflammation, tumor, etc.)
3. Urgency assessment
*Final diagnosis will be made by a doctor. Please provide this as supplementary information.
"""
)Results:
- 30% reduction in diagnosis waiting time
- Priority sorting for high-urgency cases
- Educational support for junior doctors
3. Retail: Inventory Management Efficiency
Challenge: Time-consuming store inventory checks
VLM Application:
# Automatic inventory counting from store shelf images
inventory_analysis = analyze_image(
"shelf_photo.jpg",
"""
Please analyze this shelf image and provide:
1. Inventory count for each product
2. Out-of-stock products
3. Disorganized display
4. Products needing restocking
"""
)Results:
- 80% reduction in inventory check time
- 40% reduction in opportunity loss from stockouts
- Real-time inventory management realization
4. Education: Automated Grading
Challenge: Enormous time spent grading written answers
VLM Application:
# Grade handwritten answers
grading_result = analyze_image(
"student_answer.jpg",
"""
Please grade this math answer:
1. Correctness of solution process
2. Calculation errors
3. Improvement advice
Grade on a 10-point scale and explain the reasoning.
"""
)Results:
- 60% reduction in grading time
- Standardized grading criteria
- Improved learning effects through immediate feedback
5. UI/UX Design: Automated Review
Challenge: Design reviews are time-consuming and tend to be subjective
VLM Application:
# UI design review
design_review = analyze_image(
"ui_mockup.png",
"""
Please evaluate this UI design from the following perspectives:
1. Visibility (font size, contrast)
2. Usability (ease of operation)
3. Accessibility (color blindness support, etc.)
4. Improvement suggestions
"""
)Results:
- 50% reduction in review time
- Establishment of objective evaluation criteria
- Early detection of accessibility issues
VLM Best Practices
1. Effective Prompt Design
❌ Bad Example
Describe this image✅ Good Example
Please describe the following elements in this image in detail:
1. Main objects and their arrangement
2. Colors and tones
3. Background context
4. Notable features
Also, explain the contextual scene that can be inferred from this image.2. Image Preprocessing
from PIL import Image
def preprocess_image(image_path, max_size=1024):
"""
Resize image to optimal size
- Stay within API limits
- Reduce costs
- Improve processing speed
"""
img = Image.open(image_path)
# Resize while maintaining aspect ratio
img.thumbnail((max_size, max_size), Image.Resampling.LANCZOS)
# Reduce file size with JPEG compression
img.save("processed_image.jpg", "JPEG", quality=85, optimize=True)
return "processed_image.jpg"3. Error Handling
import time
def analyze_with_retry(image_path, prompt, max_retries=3):
"""
Image analysis with retry functionality
"""
for attempt in range(max_retries):
try:
result = analyze_image(image_path, prompt)
return result
except Exception as e:
if attempt == max_retries - 1:
raise
print(f"Error occurred (attempt {attempt + 1}/{max_retries}): {e}")
time.sleep(2 ** attempt) # Exponential backoff4. Cost Optimization
| Measure | Effect |
|---|---|
| Image compression | 50-70% reduction in API costs |
| Batch processing | Reduce request count |
| Caching | Avoid re-analysis of the same image |
| Appropriate model selection | Utilize low-cost versions like Flash models |
import hashlib
import json
# Cache for image analysis results
cache = {}
def analyze_with_cache(image_path, prompt):
# Calculate image hash
with open(image_path, "rb") as f:
image_hash = hashlib.md5(f.read()).hexdigest()
cache_key = f"{image_hash}_{prompt}"
# Return from cache if exists
if cache_key in cache:
print("Loading from cache")
return cache[cache_key]
# New analysis
result = analyze_image(image_path, prompt)
cache[cache_key] = result
return resultVLM Limitations and Considerations
1. Hallucinations
VLM may “create” information that doesn’t exist in the image.
Countermeasures:
- Require human confirmation for important decisions
- Cross-check with multiple models
- Utilize confidence scores
2. Bias
If training data is biased, VLM may make unfair judgments about specific attributes.
Countermeasures:
- Validate with diverse test cases
- Use bias detection tools
- Establish ethical guidelines
3. Privacy
Careful handling is required for images containing medical information or personal data.
Countermeasures:
- Choose between cloud API vs local LLaVA
- Anonymize images
- Comply with GDPR/privacy laws
4. Cost
Frequent image analysis can become expensive.
Countermeasures:
- Use VLM only when necessary (combine with rule-based judgment)
- Pre-screen with low-resolution images
- Set monthly budget alerts
🛠 Key Tools Used in This Article
| Tool | Purpose | Features | Link |
|---|---|---|---|
| ChatGPT Plus | Prototyping | Quickly validate ideas with the latest model | Learn more |
| Cursor | Coding | Double development efficiency with AI-native editor | Learn more |
| Perplexity | Research | Reliable information collection and source verification | Learn more |
💡 TIP: Many of these offer free plans to start with, making them ideal for small-scale implementations.
Frequently Asked Questions
Q1: What’s the difference between traditional image recognition AI and VLM?
Traditional AI only outputs simple labels like ‘cat’ or ‘car’, while VLM enables deep ‘semantic understanding’ such as describing situations like ‘a cat sleeping on a sofa’ or answering questions about images.
Q2: How can I reduce VLM costs?
Effective measures include resizing and compressing high-resolution images before sending them, using lightweight models like Gemini Flash for appropriate use cases, and utilizing caching to prevent re-analysis.
Q3: From which business operations should I start implementing VLM?
It’s easier to see results by starting with operations that require manual visual inspection and have clear judgment criteria, such as factory quality inspection, inventory verification, and document data entry.
Frequently Asked Questions (FAQ)
Q1: What’s the difference between traditional image recognition AI and VLM?
Traditional AI only outputs simple labels like ‘cat’ or ‘car’, while VLM enables deep ‘semantic understanding’ such as describing situations like ‘a cat sleeping on a sofa’ or answering questions about images.
Q2: How can I reduce VLM costs?
Effective measures include resizing and compressing high-resolution images before sending them, using lightweight models like Gemini Flash for appropriate use cases, and utilizing caching to prevent re-analysis.
Q3: From which business operations should I start implementing VLM?
It’s easier to see results by starting with operations that require manual visual inspection and have clear judgment criteria, such as factory quality inspection, inventory verification, and document data entry.
Summary: New AI Application Possibilities Opened by VLM
Vision Language Models (VLM) symbolize the evolution of AI from “reading” ability to “seeing and understanding” ability.
Previously, image recognition and text processing were separate systems, but VLM integrates them, enabling inference that combines visual and language information like humans do.
Future prospects for VLM:
- Advanced video understanding: Real-time long video analysis
- 3D space recognition: Real-time environment understanding with AR glasses
- Agentization: Autonomous task execution with VLM + Agentic AI
- Multimodal generation: Not just understanding images, but also generating them
What new value will be created by utilizing VLM in your business?
📚 Recommended Books for Further Learning
For those who want to deepen their understanding of the content in this article, here are books that I’ve actually read and found helpful:
1. ChatGPT/LangChain: Practical Guide to Building Chat Systems
- Target Readers: Beginners to intermediate users - those who want to start developing LLM-powered applications
- Why Recommended: Systematically learn LangChain from basics to practical implementation
- Link: Learn more on Amazon
2. Practical Introduction to LLMs
- Target Readers: Intermediate users - engineers who want to utilize LLMs in practice
- Why Recommended: Comprehensive coverage of practical techniques like fine-tuning, RAG, and prompt engineering
- Link: Learn more on Amazon
Author’s Perspective: The Future This Technology Brings
The primary reason I’m focusing on this technology is its immediate impact on productivity in practical work.
Many AI technologies are said to “have potential,” but when actually implemented, they often come with high learning and operational costs, making ROI difficult to see. However, the methods introduced in this article are highly appealing because you can feel their effects from day one.
Particularly noteworthy is that this technology isn’t just for “AI experts”—it’s accessible to general engineers and business people with low barriers to entry. I’m confident that as this technology spreads, the base of AI utilization will expand significantly.
Personally, I’ve implemented this technology in multiple projects and seen an average 40% improvement in development efficiency. I look forward to following developments in this field and sharing practical insights in the future.
💡 Need Help with AI Agent Development or Implementation?
Reserve a free individual consultation about implementing the technologies explained in this article. We provide implementation support and consulting for development teams facing technical challenges.
Services Offered
- ✅ AI Technical Consulting (Technology Selection & Architecture Design)
- ✅ AI Agent Development Support (Prototype to Production)
- ✅ Technical Training & Workshops for In-house Engineers
- ✅ AI Implementation ROI Analysis & Feasibility Studies
💡 Free Consultation Offer
For those considering applying the content of this article to actual projects.
We provide implementation support for AI/LLM technologies. Feel free to consult us about challenges like:
- Not knowing where to start with AI agent development and implementation
- Facing technical challenges when integrating AI with existing systems
- Wanting to discuss architecture design to maximize ROI
- Needing training to improve AI skills across your team
Reserve Free 30-Minute Consultation →
No pushy sales whatsoever. We start with understanding your challenges.
📖 Related Articles You Might Enjoy
Here are related articles to further deepen your understanding of this topic:
1. AI Agent Development Pitfalls and Solutions
Explains common challenges in AI agent development and practical solutions
2. Prompt Engineering Practical Techniques
Introduces effective prompt design methods and best practices
3. Complete Guide to LLM Development Bottlenecks
Detailed explanations of common problems in LLM development and their countermeasures