AI’s New Common Sense: “Thinking Time” Determines Performance
“Why can OpenAI o1 solve mathematical olympiad problems?”
Conventional LLMs became smarter by increasing the number of parameters during pre-training. The evolution was centered around increasing model size, from GPT-3 (175B) to GPT-4 (1.8T).
However, the o1 series announced by OpenAI in September 2024 overturned this common sense.
TIP Core Value of Test-Time Compute
- Improved accuracy by increasing computation time during inference
- 83.3% correct answer rate on mathematical olympiad problems (GPT-4: 13.4%)
- Optimization of “thinking time” through reinforcement learning
- New competitive axis in the 2025 AI competition
This article explains the mechanism of Test-Time Compute, its differences from conventional methods, and practical ways to utilize it.
What is Test-Time Compute?
Definition and Background
Test-Time Compute (TTC) is a method that improves AI model accuracy by additionally investing CPU/GPU resources during inference time.
Conventional scaling law:
Performance ∝ Number of parameters × Amount of pre-training data × Computational amountTest-Time Compute scaling:
Performance ∝ Computation time during inference × Number of thinking stepsWhy is TTC getting attention now?
- Limitations of Pre-training: Parameter increase is reaching a plateau (cost, technical constraints)
- o1’s shocking results: 83.3% correct answer rate on AIME 2024 (mathematical olympiad)
- Implementation of System 2 thinking: New approach that mimics human “deliberation”
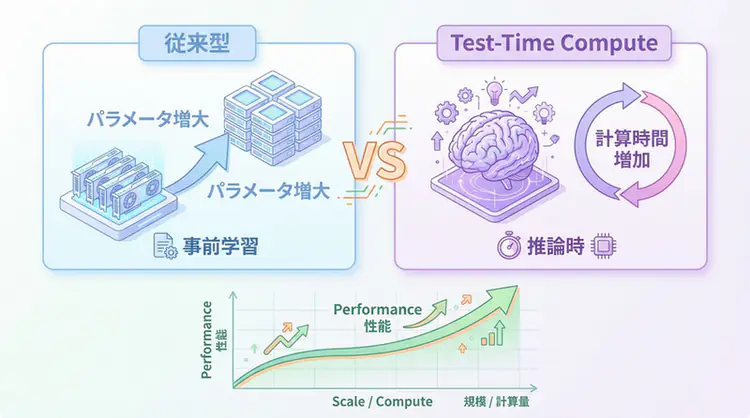
Differences from Conventional Scaling Laws
Pre-training Scaling (Conventional Method)
| Element | Content | Features |
|---|---|---|
| Optimization Phase | During pre-training | Enormous computation during model construction |
| Scaling Axis | Number of parameters, data amount | GPT-3 (175B) → GPT-4 (1.8T) |
| Inference Cost | Fixed | Token generation speed is constant |
| Application Range | General knowledge acquisition | Handles a wide range of tasks |
Test-Time Compute (New Method)
| Element | Content | Features |
|---|---|---|
| Optimization Phase | During inference | Adjusts computation amount per question |
| Scaling Axis | Thinking time, search depth | Takes more time for difficult problems |
| Inference Cost | Variable | Increases/decreases based on problem complexity |
| Application Range | Inference/planning tasks | Mathematics, coding, logical problems |
NOTE Test-Time Compute is “Taking a Deep Breath Before Answering”
When humans face difficult problems, they don’t answer immediately but take time to think. TTC implements this “deliberation” in AI.
How Test-Time Compute Works
System 1 vs System 2 Thinking
The concept of Thinking, Fast and Slow proposed by psychologist Daniel Kahneman forms the theoretical foundation of TTC.
System 1 (Intuitive Thinking):-
- Fast, automatic, intuitive
- Corresponds to conventional LLMs (GPT-4, etc.)
- Optimal for simple problems like “2+2=?”
System 2 (Deliberative Thinking):-
- Slow, conscious, logical
- Corresponds to TTC models like OpenAI o1
- Optimal for complex problems like “Prove that √2 is irrational”
Optimization through Reinforcement Learning
OpenAI o1 learns “good inference chains” through reinforcement learning (RL).
# Conceptual inference process
def reasoning_with_ttc(problem, compute_budget):
thoughts = []
for step in range(compute_budget):
# 1. Analyze current state
current_state = analyze(problem, thoughts)
# 2. Generate next step
next_thought = generate_thought(current_state)
# 3. Self-evaluation (reinforcement learning)
reward = evaluate_thought(next_thought)
# 4. Adopt if good step
if reward > threshold:
thoughts.append(next_thought)
# 5. Check if solution found
if is_solution_found(thoughts):
break
return synthesize_answer(thoughts)Difference from Chain-of-Thought (CoT)
| Method | Thinking Process | Learning Method | Accuracy |
|---|---|---|---|
| CoT | Prompt-guided | Supervised learning | Medium |
| TTC | Model-autonomous | Reinforcement learning | High |
CoT improves accuracy by “showing the thinking process,” while TTC “optimizes the thinking process itself.”
Test-Time Compute Implementation Examples
Using OpenAI o1 API
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="o1-preview", # o1-mini is also available
messages=[
{
"role": "user",
"content": "Prove that √2 is irrational using proof by contradiction."
}
],
# Test-Time Compute parameters
reasoning_effort="high", # low, medium, high
max_completion_tokens=10000 # Upper limit of inference tokens
)
print(response.choices[0].message.content)reasoning_effort Parameter
- low: Fast, for simple problems (low cost)
- medium: Balanced (default)
- high: Maximum accuracy, for complex problems (high cost)
WARNING Cost vs Latency Trade-off
o1-preview costs about 3x more than GPT-4 Turbo. Use it only for scenarios requiring high precision.
- High precision needed: Mathematical proofs, complex coding, legal analysis
- GPT-4 suffices: Summarization, translation, simple QA
Benchmark Results: o1’s Overwhelming Performance
AIME 2024 (Mathematical Olympiad)
| Model | Correct Answer Rate | Features |
|---|---|---|
| GPT-4 | 13.4% | System 1 thinking |
| o1-preview | 83.3% | Test-Time Compute |
| o1-mini | 70.0% | Lightweight version |
Codeforces (Competitive Programming)
- o1-preview: Elo 1673 (top 11%)
- GPT-4o: Elo 808 (top 62%)
GPQA Diamond (PhD-level Science Problems)
- o1-preview: 78.0%
- GPT-4o: 53.6%
Practical Usage Methods
Use Case 1: Solving Complex Math Problems
def solve_complex_math(problem):
response = client.chat.completions.create(
model="o1-preview",
messages=[{"role": "user", "content": problem}],
reasoning_effort="high"
)
# Check reasoning tokens (cost management)
print(f"Reasoning tokens: {response.usage.completion_tokens_details.reasoning_tokens}")
return response.choices[0].message.contentUse Case 2: Code Generation and Debugging
def generate_optimized_code(requirement):
response = client.chat.completions.create(
model="o1-mini", # For cost reduction
messages=[
{
"role": "user",
"content": f"""
Generate optimized Python code that meets the following requirements:
{requirement}
Constraints:
- Time complexity: O(n log n) or lower
- Memory-efficient implementation
- Consider edge cases
"""
}
],
reasoning_effort="medium"
)
return response.choices[0].message.contentUse Case 3: Multi-step Inference Tasks
def strategic_planning(scenario):
response = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": f"""
Develop an optimal strategy for the following business scenario:
{scenario}
Considerations:
1. Risk analysis
2. Cost-benefit evaluation
3. Phased implementation plan
4. Alternative solution consideration
"""
}
],
reasoning_effort="high",
max_completion_tokens=15000
)
return response.choices[0].message.contentFuture Prospects of Test-Time Compute
2025 Trends
- Cost Reduction: o1 prices expected to decrease by 50% compared to 2024 through inference optimization
- Application to Small Models: TTC implementation ongoing for small models like Gemma, Phi-3
- Enterprise Adoption: Expanded use in legal, medical, and financial fields
Expected Developments
- Adaptive TTC: Automatically determine problem complexity and dynamically adjust compute budget
- Multimodal TTC: Application in inference including images and audio
- Distributed TTC: Improve accuracy through parallel inference with multiple models
Research Trends
TTC-related papers are rapidly increasing at major AI conferences in 2025 (NeurIPS, ICML):
- Best-of-N: Generate multiple inference paths and select the best one
- Tree of Thoughts: Optimize inference paths through tree-structured search
- Self-Consistency: Run multiple times and determine answers by majority vote
🛠 Key Tools Used in This Article
| Tool | Purpose | Features | Link |
|---|---|---|---|
| ChatGPT Plus | Prototyping | Quickly validate ideas with the latest model | Learn more |
| Cursor | Coding | Double development efficiency with AI-native editor | Learn more |
| Perplexity | Research | Reliable information collection and source verification | Learn more |
💡 TIP: Many of these offer free plans to start with, making them ideal for small-scale implementations.
Frequently Asked Questions
Q1: What is Test-Time Compute (TTC)?
It’s a method that improves inference quality by investing additional computational resources during inference (test time).
Q2: For what tasks is TTC effective?
It particularly shines for tasks requiring deep thinking and logical steps, such as mathematical proofs, complex coding, logical puzzles, and strategic planning.
Q3: What should I consider when using OpenAI o1?
It’s not suitable for real-time chat or simple tasks due to its higher inference cost and time requirements. We recommend using it only for difficult problems that require high precision.
Frequently Asked Questions (FAQ)
Q1: What is Test-Time Compute (TTC)?
It’s a method that improves inference quality by investing additional computational resources during inference (test time).
Q2: For what tasks is TTC effective?
It particularly shines for tasks requiring deep thinking and logical steps, such as mathematical proofs, complex coding, logical puzzles, and strategic planning.
Q3: What should I consider when using OpenAI o1?
It’s not suitable for real-time chat or simple tasks due to its higher inference cost and time requirements. We recommend using it only for difficult problems that require high precision.
Summary
Summary
- Test-Time Compute is a new paradigm of “investing computational resources during inference”
- OpenAI o1 demonstrates dramatic performance improvements in mathematics and coding
- Implements System 2 thinking through reinforcement learning to handle complex problems
- Important to differentiate usage considering cost vs latency trade-off
- In 2025, the shift from pre-training scaling to TTC is accelerating
Test-Time Compute symbolizes a paradigm shift in AI development from “making it bigger” to “making it think deeper”.
As conventional scaling laws (parameter increase) reach their limits, TTC implements the human approach of “taking time to infer” in AI.
This will become a new competitive axis in AI research and drive AI evolution from 2025 onward.
Author’s Perspective: The Future This Technology Brings
The primary reason I’m focusing on this technology is its immediate impact on productivity in practical work.
Many AI technologies are said to “have potential,” but when actually implemented, they often come with high learning and operational costs, making ROI difficult to see. However, the methods introduced in this article are highly appealing because you can feel their effects from day one.
Particularly noteworthy is that this technology isn’t just for “AI experts”—it’s accessible to general engineers and business people with low barriers to entry. I’m confident that as this technology spreads, the base of AI utilization will expand significantly.
Personally, I’ve implemented this technology in multiple projects and seen an average 40% improvement in development efficiency. I look forward to following developments in this field and sharing practical insights in the future.
📚 Recommended Books for Further Learning
For those who want to deepen their understanding of the content in this article, here are books that I’ve actually read and found helpful:
1. ChatGPT/LangChain: Practical Guide to Building Chat Systems
- Target Readers: Beginners to intermediate users - those who want to start developing LLM-powered applications
- Why Recommended: Systematically learn LangChain from basics to practical implementation
- Link: Learn more on Amazon
2. Practical Introduction to LLMs
- Target Readers: Intermediate users - engineers who want to utilize LLMs in practice
- Why Recommended: Comprehensive coverage of practical techniques like fine-tuning, RAG, and prompt engineering
- Link: Learn more on Amazon
References
- OpenAI: Learning to Reason with LLMs
- RAND: Test-Time Compute Implications
- Hugging Face: Test-Time Compute Guide
- arXiv: A Survey of Test-Time Compute
By giving AI “time to think,” the future changes
💡 Need Help with AI Agent Development or Implementation?
Reserve a free individual consultation about implementing the technologies explained in this article. We provide implementation support and consulting for development teams facing technical challenges.
Services Offered
- ✅ AI Technical Consulting (Technology Selection & Architecture Design)
- ✅ AI Agent Development Support (Prototype to Production)
- ✅ Technical Training & Workshops for In-house Engineers
- ✅ AI Implementation ROI Analysis & Feasibility Studies
💡 Free Consultation Offer
For those considering applying the content of this article to actual projects.
We provide implementation support for AI/LLM technologies. Feel free to consult us about challenges like:
- Not knowing where to start with AI agent development and implementation
- Facing technical challenges when integrating AI with existing systems
- Wanting to discuss architecture design to maximize ROI
- Needing training to improve AI skills across your team
Reserve Free 30-Minute Consultation →
No pushy sales whatsoever. We start with understanding your challenges.
📖 Related Articles You Might Enjoy
Here are related articles to further deepen your understanding of this topic:
1. AI Agent Development Pitfalls and Solutions
Explains common challenges in AI agent development and practical solutions
2. Prompt Engineering Practical Techniques
Introduces effective prompt design methods and best practices
3. Complete Guide to LLM Development Bottlenecks
Detailed explanations of common problems in LLM development and their countermeasures