What is RAG?
RAG (Retrieval-Augmented Generation) enhances LLM capabilities by retrieving relevant information from external knowledge bases. It solves LLM limitations like hallucinations and knowledge cutoff.
Basic RAG Architecture
User Query → Embedding → Vector Search → Retrieve Documents → LLM + Context → AnswerImplementation Steps
Document Processing
- Load documents (PDF, HTML, etc.)
- Chunk with appropriate size (500-1000 tokens)
- Generate embeddings
Vector Storage
- Store embeddings in vector database
- Add metadata for filtering
Retrieval
- Embed user query
- Similarity search (k-NN)
- Return top-k documents
Generation
- Combine query + retrieved context
- Generate answer with LLM
Advanced RAG Patterns
1. Hybrid Search
Combines BM25 (keyword) and vector (semantic) search:
# LangChain example
from langchain.retrievers import BM25Retriever, EnsembleRetriever
bm25_retriever = BM25Retriever.from_documents(docs)
vector_retriever = vectorstore.as_retriever()
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.5, 0.5]
)2. Re-ranking
Use cross-encoder to re-rank retrieved documents:
from sentence_transformers import CrossEncoder
reranker = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
scores = reranker.predict([(query, doc) for doc in retrieved_docs])3. Query Expansion
Expand queries to improve retrieval:
# Generate multiple query variations
expanded_queries = [
query,
llm.invoke(f"Rephrase: {query}"),
llm.invoke(f"Simplify: {query}")
]Best Practices
| Aspect | Recommendation |
|---|---|
| Chunk Size | 500-1000 tokens with 10-20% overlap |
| Embedding Model | text-embedding-3-large or E5 |
| Top-k | 5-10 documents |
| Temperature | 0.1-0.3 for factual tasks |
🛠 Key Tools
| Tool | Purpose | Link |
|---|---|---|
| LangChain | RAG Framework | Details |
| LlamaIndex | Data Framework | Details |
| Pinecone | Vector DB | Details |
FAQ
Q1: What is the basic RAG architecture?
Document ingestion → Embedding → Vector storage → Similarity search → Context-augmented generation
Q2: How to improve RAG accuracy?
Use hybrid search, re-ranking, query expansion, and metadata filtering
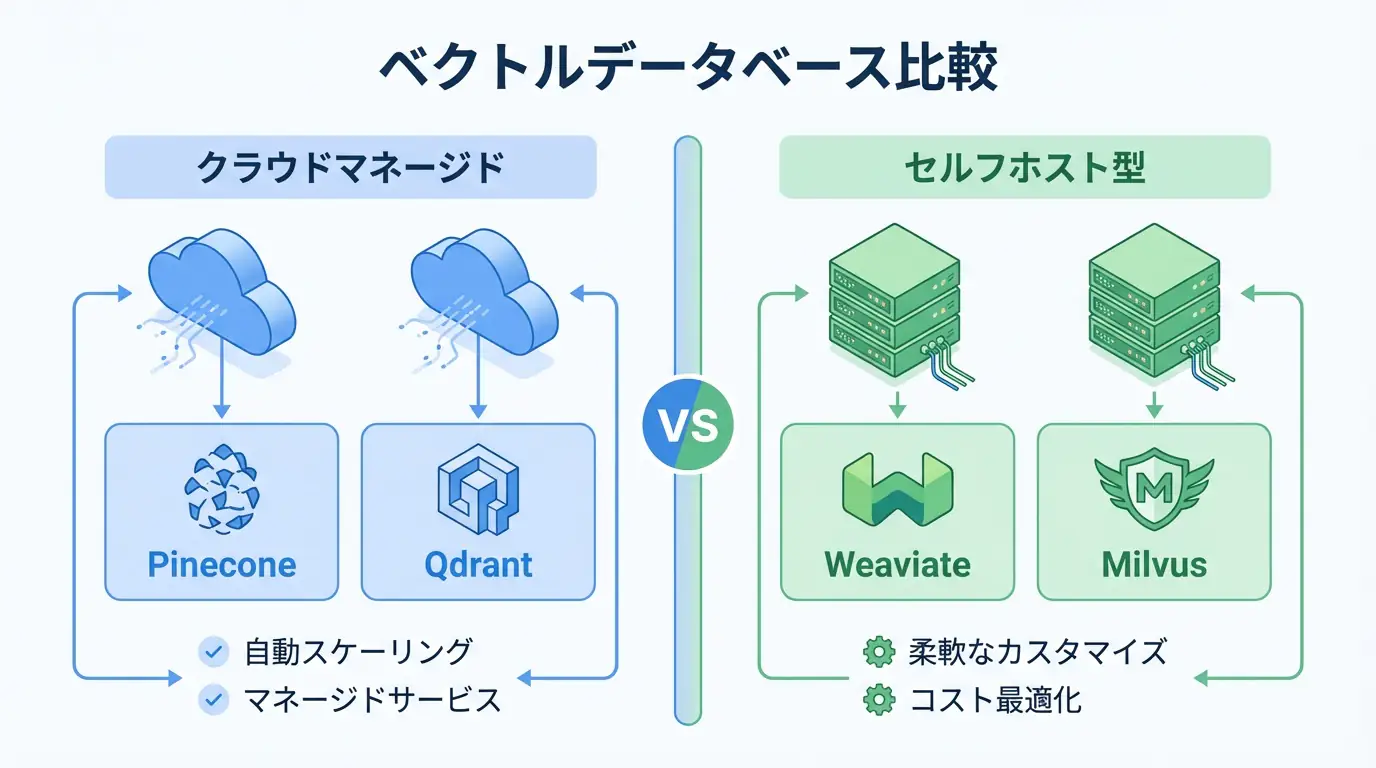
Q3: Which vector database should I use?
Pinecone for managed, Qdrant for cost-effective, Milvus for large scale
Summary
RAG is essential for production LLM applications. Start with basic implementation, then add advanced techniques like hybrid search and re-ranking for better performance.