Articles
Explore the latest AI technology and tools
Categories
Tags
The Reality of AI Agent Implementation - 5 Factors That Separate Success from Failure in 2025
In 2025, AI agents are at the center of business. While 88% implement them, only 6% are truly successful. This article thoroughly explains the 5 factors that separate successful from failed companies based on the latest reports from Microsoft, OpenAI, and McKinsey.
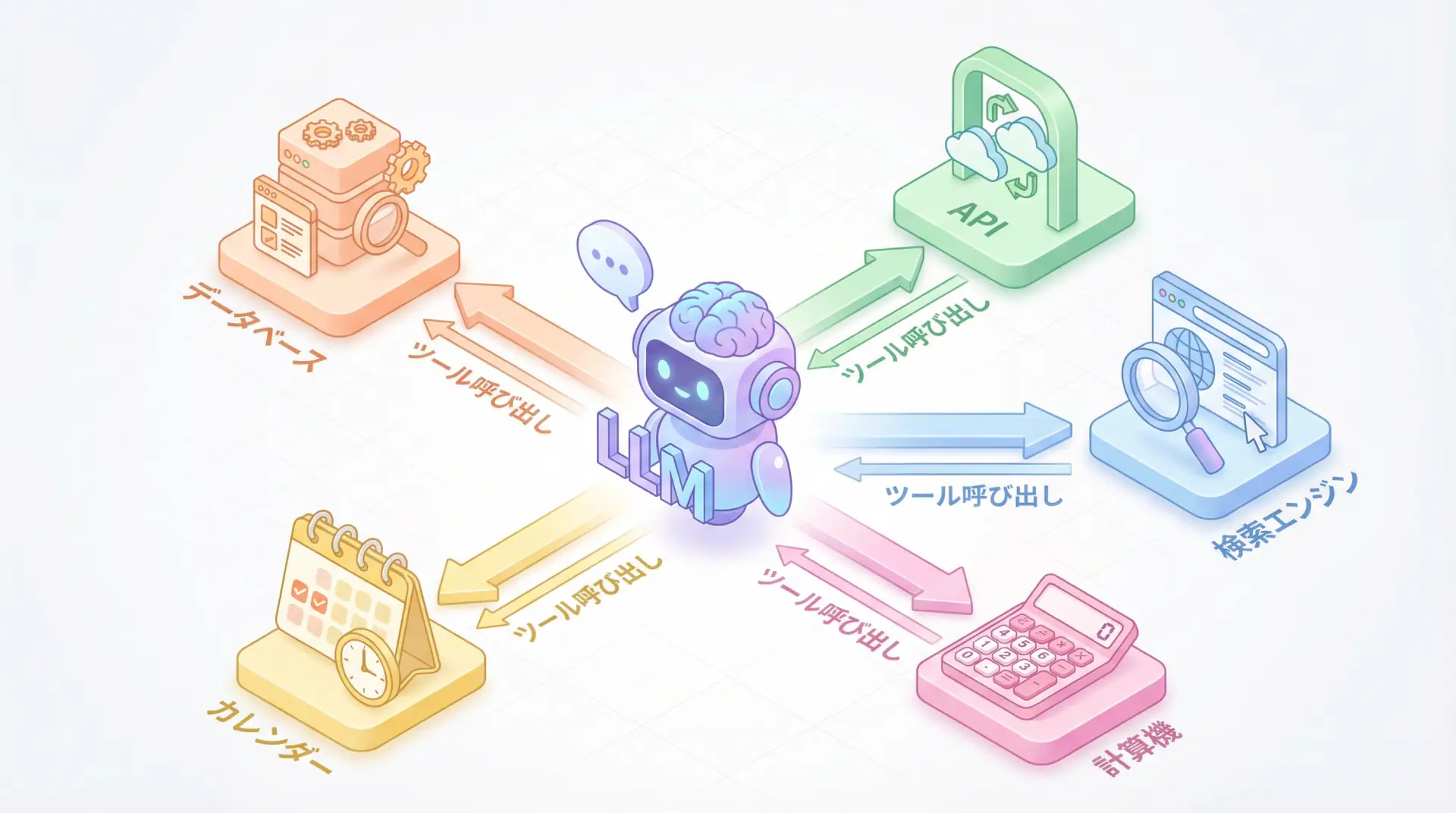
Function Calling & Tool Use Implementation Guide - Complete Explanation of Core AI Agent Technology
Function Calling and Tool Use are essential for AI agent development in 2025. This article provides practical explanations of everything engineers should know, from implementation comparisons across OpenAI, Anthropic, and Google, to building autonomous agents with ReAct patterns, and production operation considerations.
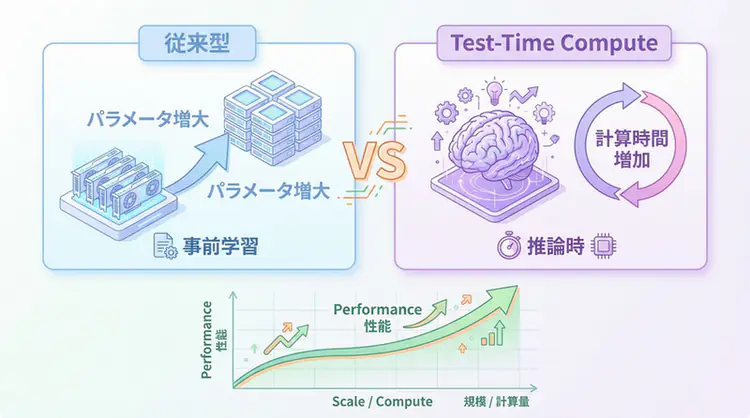
Test-Time Compute (TTC) Complete Guide - The New Era of AI Inference That 'Thinks Fast and Deep'
A comprehensive explanation of the technical mechanisms behind Test-Time Compute (TTC) represented by OpenAI o1. A complete guide for AI engineers to implement in practice, covering Best-of-N, reward models with PRM/ORM, and adaptive computation implementation patterns.

AI Agent Computer Use Complete Guide - Next Generation of GUI Operation Automation
With Anthropic's 'Computer Use' feature, LLMs can operate browsers and desktop apps like humans. Explains the mechanism, implementation methods, security, and differentiation from traditional API integration for engineers.
Is AI Ethics a Cost or an Investment? The Business Value of 'Responsible AI' Every Executive Should Know
As AI adoption accelerates, addressing ethical risks is urgent. This article explains the basic principles of 'responsible AI' that executives should know and its specific business value, based on research from PwC and BCG, in an easy-to-understand manner.

LLM Inference Optimization: Practical Techniques to Dramatically Improve Latency and Cost
Comprehensive guide to solving LLM production challenges with quantization, speculative decoding, vLLM, and other cutting-edge techniques to dramatically reduce inference costs and latency.