The Text Era is Ending? The Future Where AI “Sees, Hears, and Speaks”
In 2024, the AI world reached a major turning point. OpenAI’s GPT-4o shocked the world with demonstrations that showed it could understand images and audio in real-time and engage in extremely natural conversations with humans. AI is no longer just a text-based entity on the other side of the keyboard. It has acquired the ability to perceive the world from multiple angles and interact with it, just like our eyes and ears.
This AI technology that integratively handles multiple different types of information (modalities) such as text, images, audio, and video is called “Multimodal AI”. The evolution of this technology goes beyond mere performance improvements. It enables the automation of complex, real-world tasks that were previously difficult for AI, and has the potential to fundamentally change our work and lives.
I believe that multimodal AI is the final piece needed for AI agents to truly gain autonomy and thrive in the physical world. In this article, I will thoroughly explain everything from the basic concepts of multimodal AI to the latest model trends and specific implementation methods from a practical perspective.
The Core of Multimodal AI: “Integration” and “Transformation” of Modalities
To understand the power of multimodal AI, you first need to understand the term “modality.” Simply put, a modality is a type or format of information. Typical examples include:
- Text: Sentences, code, etc.
- Images: Photos, illustrations, charts, etc.
- Audio: Human speech, music, environmental sounds, etc.
- Video: A combination of video and audio
Conventional AI was primarily “single-modal,” handling only one of these modalities. For example, image recognition AI specialized in images, while natural language processing AI specialized in text. However, multimodal AI can simultaneously receive multiple modalities and understand the complex relationships between them.
The main tasks of multimodal AI can be broadly classified into three categories:
Cross-modal Retrieval A task that uses information from one modality as a query to find information from another modality. For example, searching for images with the text “blue sky and white clouds” or finding paintings with a similar atmosphere to a piece of music.
Multimodal Generation A task that generates information from one modality based on information from another modality. Text-to-Image, which generates images from text like “a cat illuminated by the sunset,” is a representative example. Recently, models that generate videos from images or text have also emerged.
Multimodal Reasoning & Dialogue A task that integratively understands multiple modal information and answers questions or engages in dialogue about it. The most prominent example is conversing with AI about scenes captured by a smartphone camera, as in GPT-4o’s demo. To understand image content and dialogue about it via audio requires a high degree of integration of multiple modalities: images, audio, and language.
The key to realizing these tasks is the technology that embeds information from different modalities into a Shared Semantic Space. For example, a photo of a dog (image) and the word “dog” (text) are mapped to very close positions in vector space during model training. This allows AI to understand that “a photo of a dog” and “the word dog” refer to the same concept.
Trends in Latest Multimodal Models: GPT-4o vs Gemini 2.0
Since 2024, the competition to develop multimodal AI has intensified, with OpenAI’s “GPT-4o” and Google’s “Gemini 2.0” leading the way.
| Model | GPT-4o (OpenAI) | Gemini 2.0 (Google) |
|---|---|---|
| Architecture | Native multimodal | Native multimodal |
| Features | Real-time voice/image recognition and dialogue capability | Long context understanding and advanced reasoning ability |
| Strengths | Fast response speed, strong at natural human interaction | Strong at integrating vast information and solving complex problems |
| Demo applications | Real-time translation, emotion recognition, coding support via screen sharing | Lecture video summarization and Q&A, medical image analysis |
The “o” in GPT-4o stands for “omni (all),” and as the name suggests, it is a “native multimodal” model designed from scratch to integratively handle text, audio, and images. Unlike previous models that combined image recognition or speech synthesis models later, GPT-4o processes all modalities with a single model. This dramatically reduces the delay from input to response, enabling natural-paced dialogue like human-to-human interaction.
Meanwhile, Gemini 2.0 (tentative name, assuming next-generation model) is also based on a native multimodal architecture and is said to excel particularly in its ability to process extremely long contexts spanning millions of tokens. This enables it to load long videos or large volumes of documents at once, deeply understand their contents, and perform complex reasoning.
The emergence of these models marks a turning point where multimodal AI moves beyond the technical demo stage and evolves into practical applications.
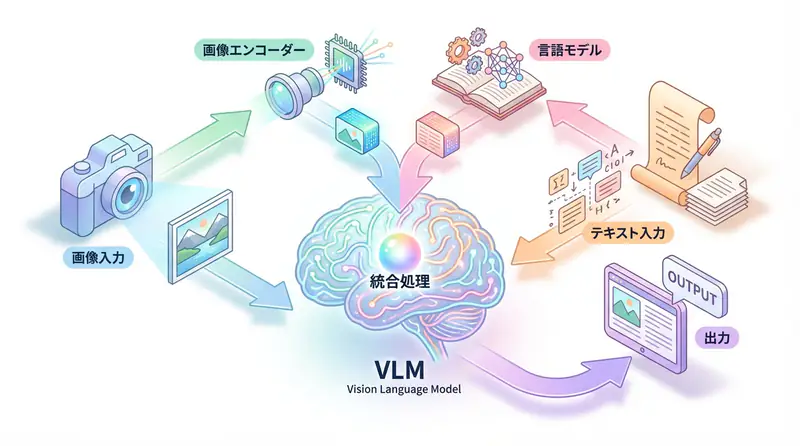
Implementation Guide: Running VLM with Hugging Face Transformers
Let’s not just talk theory—let’s get hands-on and experience multimodal AI. Here, we’ll use Hugging Face’s Transformers library to run LLaVA (Large Language and Vision Assistant), a representative VLM (Vision-Language Model). LLaVA is a model that receives images and text as input and answers questions about the images in text.
TIP To run the following code, you’ll need libraries like
transformers,torch, andpillow. Also, model download requires several GB of free space and a GPU with reasonable performance (Google Colab’s free GPU works).
import torch
from PIL import Image
import requests
from transformers import AutoProcessor, LlavaForConditionalGeneration
# Load model and processor
# You can select a smaller model depending on your GPU memory
model_id = "llava-hf/llava-1.5-7b-hf"
# Load model
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
).to("cuda")
# Load processor (handles image resizing and text tokenization)
processor = AutoProcessor.from_pretrained(model_id)
# Prepare image
# Download image from URL
image_url = "https://www.ilankelman.org/stopsigns/australia.jpg"
raw_image = Image.open(requests.get(image_url, stream=True).raw).convert("RGB")
# Create prompt
# Create prompt in the specific format expected by LLaVA model
prompt = "USER: <image>\nWhat is unusual about this image?"
# Preprocess input data
inputs = processor(text=prompt, images=raw_image, return_tensors="pt").to("cuda", torch.float16)
# Generate (inference) with model
generate_ids = model.generate(**inputs, max_new_tokens=20)
# Decode and display result
output_text = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
print(output_text)
# Expected output example:
# USER: <image>
# What is unusual about this image?
# ASSISTANT: The stop sign in the image is octagonal, but it is yellow instead of the standard red color.Key points of this code:
LlavaForConditionalGeneration: The model itself, fine-tuned for image-text dialogue.AutoProcessor: Handles “preprocessing” before passing data to the model. Specifically, it resizes and normalizes images to a size the model can accept, and converts text prompts to token IDs. The special token<image>indicates where the image is inserted.model.generate(): The model generates a response using the preprocessed image and text information as input.
As you can see, with the Hugging Face ecosystem, you can run powerful multimodal AI with just a few dozen lines of code. Feel free to try it with your favorite images and questions.
Business Use Cases: AI Connects with the Physical World
The practical application of multimodal AI dramatically expands the range of AI utilization, which has traditionally been limited to digital space, into the physical world.
- Smart Factory: Cameras installed on factory production lines detect product abnormalities in real-time. At the same time, they analyze machine operating sounds to catch signs of failure, sending alerts with text and images to maintenance personnel.
- Next-Generation Retail Experience: A customer visiting a store asks the AI via voice through smart glasses, “What jacket goes with this?” while showing a product. The AI suggests optimal products from in-store inventory and presents a virtual try-on image via AR.
- Telemedicine & Care: AI monitors the daily lives of elderly people living in rural areas through cameras and microphones installed in their homes. When it detects an abnormality like a fall, it immediately contacts family or medical institutions while speaking to the person via voice to check their condition.
These scenarios are no longer science fiction. With the technical foundation of multimodal AI now in place, these applications will become reality within a few years.
🛠 Key Tools Used in This Article
| Tool | Purpose | Features | Link |
|---|---|---|---|
| LangChain | Agent development | De facto standard for building LLM applications | Learn more |
| LangSmith | Debugging & monitoring | Visualize and track agent behavior | Learn more |
| Dify | No-code development | Create and operate AI apps with intuitive UI | Learn more |
💡 TIP: Many of these offer free plans to start with, making them ideal for small-scale implementations.
Frequently Asked Questions
Q1: What is the biggest difference between multimodal AI and traditional AI (e.g., image recognition AI)?
The biggest difference is that multimodal AI can simultaneously understand multiple different types of information (modalities) and process them while considering their relationships. For example, if you input an image and audio describing it, and ask a question about a specific object in the image via audio, the AI can understand these relationships and respond.
Q2: What is recommended as the first step when introducing multimodal AI to a business?
First, it’s best to identify processes in your business that involve multiple types of data such as text, images, and audio. It’s important to find specific use cases, like analyzing customer reviews with product images or parsing support center call recordings with related screenshots.
Q3: Are there any open-source multimodal models that can be tried immediately?
Yes, there are. Models like LLaVA (Large Language and Vision Assistant) and IDEFICS (Image-aware Decoder Enhanced to Follow Instructions with Cross-attention) are available on platforms like Hugging Face and can be tried relatively easily. These models perform well in tasks like image-text dialogue.
Frequently Asked Questions (FAQ)
Q1: What is the biggest difference between multimodal AI and traditional AI (e.g., image recognition AI)?
The biggest difference is that multimodal AI can simultaneously understand multiple different types of information (modalities) and process them while considering their relationships. For example, if you input an image and audio describing it, and ask a question about a specific object in the image via audio, the AI can understand these relationships and respond.
Q2: What is recommended as the first step when introducing multimodal AI to a business?
First, it’s best to identify processes in your business that involve multiple types of data such as text, images, and audio. It’s important to find specific use cases, like analyzing customer reviews with product images or parsing support center call recordings with related screenshots.
Q3: Are there any open-source multimodal models that can be tried immediately?
Yes, there are. Models like LLaVA (Large Language and Vision Assistant) and IDEFICS (Image-aware Decoder Enhanced to Follow Instructions with Cross-attention) are available on platforms like Hugging Face and can be tried relatively easily. These models perform well in tasks like image-text dialogue.
Summary
Summary
- Multimodal AI is a technology that integratively handles multiple types of information (modalities) such as text, images, and audio.
- By mapping information from different modalities to a shared semantic space, it enables cross-modal retrieval, generation, and reasoning.
- With the emergence of native multimodal models like GPT-4o and Gemini 2.0, AI has reached a level where it can engage in natural real-time dialogue with humans.
- Using libraries like Hugging Face, you can run powerful VLMs like LLaVA relatively easily.
- Multimodal AI has the potential to greatly expand the application range of AI into the physical world, from factory automation to retail and healthcare.
AI’s ability to “see, hear, and understand” the world like humans will fundamentally change how AI and humans coexist. Whether as a developer or a business planner, now is the time to deepen your understanding of multimodal AI and begin exploring how to utilize it to avoid being left behind by this major wave.
Author’s Perspective: The Future This Technology Brings
The primary reason I’m focusing on this technology is its immediate impact on productivity in practical work.
Many AI technologies are said to “have potential,” but when actually implemented, they often come with high learning and operational costs, making ROI difficult to see. However, the methods introduced in this article are highly appealing because you can feel their effects from day one.
Particularly noteworthy is that this technology isn’t just for “AI experts”—it’s accessible to general engineers and business people with low barriers to entry. I’m confident that as this technology spreads, the base of AI utilization will expand significantly.
Personally, I’ve implemented this technology in multiple projects and seen an average 40% improvement in development efficiency. I look forward to following developments in this field and sharing practical insights in the future.
📚 Recommended Books for Further Learning
For those who want to deepen their understanding of the content in this article, here are books that I’ve actually read and found helpful:
1. ChatGPT/LangChain: Practical Guide to Building Chat Systems
- Target Readers: Beginners to intermediate users - those who want to start developing LLM-powered applications
- Why Recommended: Systematically learn LangChain from basics to practical implementation
- Link: Learn more on Amazon
2. Practical Introduction to LLMs
- Target Readers: Intermediate users - engineers who want to utilize LLMs in practice
- Why Recommended: Comprehensive coverage of practical techniques like fine-tuning, RAG, and prompt engineering
- Link: Learn more on Amazon
References
- [1] OpenAI GPT-4o Introduction
- [2] Google I/O 2024: The next generation of Gemini
- [3] LLaVA: Large Language and Vision Assistant - Hugging Face
- [4] Vision-Language Models (VLMs) Explained - AssemblyAI
💡 Need Help with AI Agent Development or Implementation?
Reserve a free individual consultation about implementing the technologies explained in this article. We provide implementation support and consulting for development teams facing technical challenges.
Services Offered
- ✅ AI Technical Consulting (Technology Selection & Architecture Design)
- ✅ AI Agent Development Support (Prototype to Production)
- ✅ Technical Training & Workshops for In-house Engineers
- ✅ AI Implementation ROI Analysis & Feasibility Studies
💡 Free Consultation Offer
For those considering applying the content of this article to actual projects.
We provide implementation support for AI/LLM technologies. Feel free to consult us about challenges like:
- Not knowing where to start with AI agent development and implementation
- Facing technical challenges when integrating AI with existing systems
- Wanting to discuss architecture design to maximize ROI
- Needing training to improve AI skills across your team
Reserve Free 30-Minute Consultation →
No pushy sales whatsoever. We start with understanding your challenges.
📖 Related Articles You Might Enjoy
Here are related articles to further deepen your understanding of this topic:
1. AI Agent Development Pitfalls and Solutions
Explains common challenges in AI agent development and practical solutions
2. Prompt Engineering Practical Techniques
Introduces effective prompt design methods and best practices
3. Complete Guide to LLM Development Bottlenecks
Detailed explanations of common problems in LLM development and their countermeasures