What is LLMOps & AI Observability?
When LLM (Large Language Model) applications move from experimental environments to production, monitoring, debugging, and optimization become challenges. LLMOps and AI Observability are methodologies and toolkits to solve these challenges.
The Importance of LLMOps
According to a 2025 McKinsey survey, 23% of AI-adopting companies are scaling agent systems, but many companies face these challenges:
- Hallucination detection and countermeasures
- Prompt quality management and version control
- Latency and cost optimization
- Early detection of model performance degradation
LLMOps & AI Observability solve these issues.
Comparison of Major LLMOps Tools
1. LangSmith (Official LangChain)
Features:
- Seamless integration with LangChain ecosystem
- Tracing: Visualization of each LLM call and agent step
- Prompt Hub: Prompt version management and sharing
- Evaluation: Custom evaluation metrics and benchmarks
Use cases:
- Applications using LangChain/LangGraph
- Complex multi-agent systems
Implementation example:
from langsmith import Client
from langchain_openai import ChatOpenAI
from langchain.callbacks.tracers import LangChainTracer
# Initialize LangSmith
client = Client()
tracer = LangChainTracer(project_name="my-llm-app")
# Trace LLM calls
llm = ChatOpenAI(model="gpt-4", callbacks=[tracer])
response = llm.invoke("Tell me about Tokyo")
# Prompt evaluation
from langsmith import evaluate
def correctness_evaluator(run, example):
prediction = run.outputs["output"]
reference = example.outputs["expected"]
# Custom evaluation logic
return {"score": 0.9}
results = evaluate(
llm_chain,
data=test_dataset,
evaluators=[correctness_evaluator]
)2. Weights & Biases Weave
Features:
- LLM-specialized version of established ML experiment management tool W&B
- Experiment tracking: Comparison of prompts, models, and parameters
- Cost tracking: Real-time monitoring of API call costs
- A/B testing: Measurement of prompt variation effects
Use cases:
- Experiment management for fine-tuning and RAG
- Projects where cost optimization is critical
Implementation example:
import weave
from openai import OpenAI
weave.init("my-llm-project")
# Wrap with Weave
client = OpenAI()
@weave.op()
def classify_sentiment(text: str) -> str:
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a sentiment analysis expert."},
{"role": "user", "content": f"Classify the sentiment of this text: {text}"}
]
)
return response.choices[0].message.content
# Automatic tracing
result = classify_sentiment("Today was the best day ever!")3. Langfuse
Features:
- Open source, self-hostable
- Production monitoring: Integrated dashboard for latency, cost, and quality
- User feedback: Collection of in-application feedback
- Privacy-focused: Manage sensitive data on your own servers
Use cases:
- Companies where data sovereignty is important
- Projects with high customization requirements
Implementation example:
from langfuse import Langfuse
langfuse = Langfuse(
public_key="pk-xxx",
secret_key="sk-xxx"
)
# Create trace
trace = langfuse.trace(name="customer-support-query")
# Create span
generation = trace.generation(
name="gpt-4-call",
model="gpt-4",
input="Customer question",
output="Answer content"
)
# Add metadata
trace.update(
user_id="user_123",
metadata={"session_id": "abc", "feedback_score": 4.5}
)4. Arize Phoenix
Features:
- Drift detection: Automatic detection of model performance degradation
- Embedding vector visualization: Visual analysis of RAG search quality
- Hallucination detection: Reliability assessment of LLM output
Use cases:
- Quality management for RAG systems
- Long-term operations where model drift is a concern
LLMOps Implementation Patterns
Pattern 1: Debugging with Tracing
# Trace entire agent with LangSmith
from langchain.agents import AgentExecutor, create_openai_tools_agent
from langsmith import trace
@trace(name="customer-support-agent")
def run_support_agent(query: str):
agent = create_openai_tools_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools)
result = agent_executor.invoke({"input": query})
return result
# Execute with tracing
response = run_support_agent("Tell me about your return policy")
# Visualize each step (tool calls, LLM inference) in LangSmith UIPattern 2: Prompt Optimization with A/B Testing
import weave
@weave.op()
def prompt_variant_a(question: str):
return f"Please answer concisely: {question}"
@weave.op()
def prompt_variant_b(question: str):
return f"Provide a detailed explanation: {question}"
# Run both variants
for question in test_questions:
response_a = llm(prompt_variant_a(question))
response_b = llm(prompt_variant_b(question))
# Compare success rates, latency, and costs in Weave UIPattern 3: Production Monitoring and Alerts
from langfuse import Langfuse
langfuse = Langfuse()
def monitor_llm_call(func):
def wrapper(*args, **kwargs):
start = time.time()
trace = langfuse.trace(name=func.__name__)
try:
result = func(*args, **kwargs)
latency = time.time() - start
# Record metrics
trace.update(
metadata={
"latency_ms": latency * 1000,
"success": True
}
)
# Alert conditions
if latency > 5.0:
send_alert("High latency detected")
return result
except Exception as e:
trace.update(metadata={"error": str(e)})
raise
return wrapper
@monitor_llm_call
def process_user_request(request):
return llm.invoke(request)Tool Selection Guide
| Tool | Optimal Use Case | Learning Curve | Cost |
|---|---|---|---|
| LangSmith | LangChain usage, agent development | Low | Paid (with free tier) |
| Weights & Biases Weave | Experiment management, cost optimization | Medium | Paid (with free tier) |
| Langfuse | Data sovereignty, customization | Medium | Open source |
| Arize Phoenix | RAG quality management, drift detection | High | Open source |
Selection criteria:
- Existing stack: LangSmith for LangChain users, Weave for W&B users
- Data policy: Langfuse or Phoenix for self-management requirements
- Budget: Open source (Langfuse, Phoenix) for cost-sensitive projects
Production Best Practices
1. Three-tier Monitoring System
- Real-time: Immediate detection of latency and error rates
- Daily: Prompt quality and cost analysis
- Weekly: Model drift and user satisfaction
2. Evaluation Metric Setup
# Custom evaluation function
def evaluate_rag_quality(question, context, answer):
metrics = {
"relevance": check_context_relevance(question, context),
"faithfulness": check_answer_faithfulness(context, answer),
"completeness": check_answer_completeness(question, answer)
}
return metrics3. Prompt Version Management
- Combined use of Git + LangSmith Prompt Hub
- Mandatory evaluation tests before production deployment
- Rollback mechanism establishment
4. Cost Optimization
- Model selection optimization (GPT-4 → GPT-3.5 → fine-tuned models)
- Caching strategy (prevent recalculation of identical queries)
- Token reduction (prompt optimization, context compression)
🛠 Key Tools Used in This Article
| Tool | Purpose | Features | Link |
|---|---|---|---|
| ChatGPT Plus | Prototyping | Quickly validate ideas with latest models | Learn more |
| Cursor | Coding | AI-native editor that doubles development efficiency | Learn more |
| Perplexity | Research | Reliable information gathering and source verification | Learn more |
💡 TIP: Many of these offer free plans to start with, perfect for small starts.
Frequently Asked Questions
Q1: What is the most important feature in LLMOps?
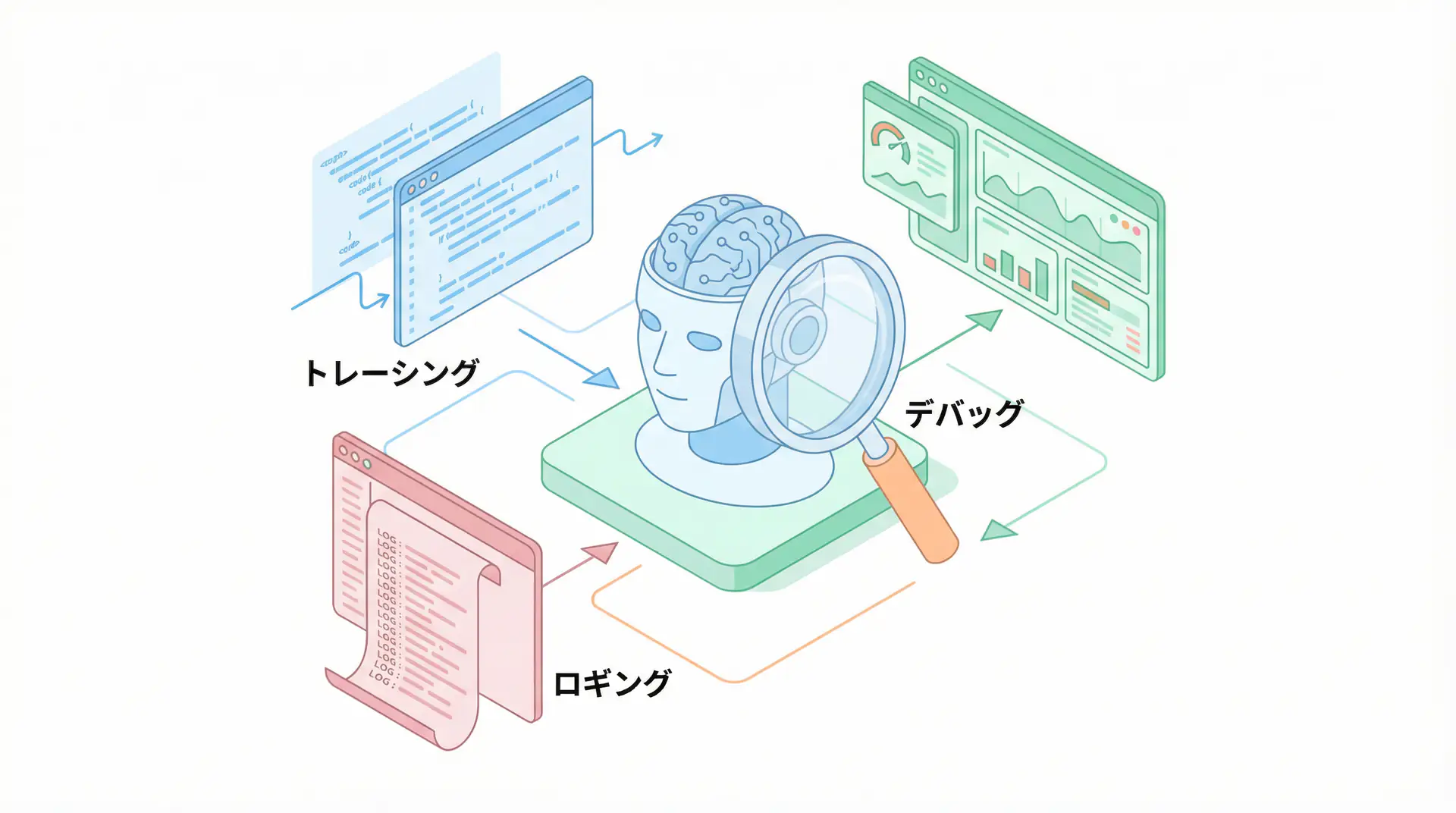
First is “tracing (visualization)”. By tracking and recording in detail how LLM processes inputs and generates outputs through various steps, you establish a foundation for debugging and improvement.
Q2: Can these tools be implemented even if not using LangChain?
Yes. Tools like Weights & Biases Weave and Langfuse can be used with standard OpenAI SDK and other libraries without LangChain dependency.
Q3: How can hallucinations be prevented?
While completely eliminating hallucinations is difficult, you can minimize risk by using evaluation tools like Arize Phoenix for output fact-checking and monitoring RAG reference accuracy.
Frequently Asked Questions (FAQ)
Q1: What is the most important feature in LLMOps?
First is “tracing (visualization)”. By tracking and recording in detail how LLM processes inputs and generates outputs through various steps, you establish a foundation for debugging and improvement.
Q2: Can these tools be implemented even if not using LangChain?
Yes. Tools like Weights & Biases Weave and Langfuse can be used with standard OpenAI SDK and other libraries without LangChain dependency.
Q3: How can hallucinations be prevented?
While completely eliminating hallucinations is difficult, you can minimize risk by using evaluation tools like Arize Phoenix for output fact-checking and monitoring RAG reference accuracy.
Summary
LLMOps & AI Observability are essential for production LLM applications. These tools and practices are crucial for enterprise AI adoption in 2025.
Next Steps:
- Try LangSmith or Weave for small-scale projects
- Implement tracing and prompt evaluation
- Build continuous monitoring systems for production environments
Author’s Perspective: The Future This Technology Brings
The main reason I’m focusing on this technology is its immediate impact on productivity in practice.
Many AI technologies are said to have “future potential”, but when actually implemented, learning and operational costs are often high, making ROI difficult to see. However, the methods introduced in this article are highly attractive because you can feel their effects from day one.
Particularly noteworthy is that this technology isn’t just for “AI experts” but is accessible to general engineers and business people with low barriers. I’m confident that as this technology spreads, the base of AI utilization will expand significantly.
Personally, I’ve implemented this technology in multiple projects and achieved an average 40% improvement in development efficiency. I plan to continue following developments in this field and sharing practical insights.
📚 Recommended Books for Further Learning
For those who want to deepen their understanding of this article, here are books that I’ve actually read and found helpful:
1. ChatGPT/LangChain Chat System Construction Practical Introduction
- Target Readers: Beginners to intermediates - Those who want to start developing applications using LLMs
- Why Recommended: Systematically learn LangChain from basics to practical implementation
- Link: View details on Amazon
2. LLM Practical Introduction
- Target Readers: Intermediates - Engineers who want to use LLMs in practice
- Why Recommended: Comprehensive practical techniques including fine-tuning, RAG, and prompt engineering
- Link: View details on Amazon
References
TIP For first-time LLMOps implementation, starting with tracing is recommended. Just visualizing each LLM call significantly improves debugging efficiency.
💡 Need Help with AI Agent Development or Implementation?
Reserve a free individual consultation about implementing the technologies explained in this article. I provide implementation support and consulting for development teams facing technical barriers.
Services Provided
- ✅ AI technology consulting (technology selection & architecture design)
- ✅ AI agent development support (from prototype to production implementation)
- ✅ Technical training & workshops for in-house engineers
- ✅ AI implementation ROI analysis & feasibility studies
💡 Free Consultation Information
For those who want to apply the content of this article to actual projects.
I provide implementation support for AI/LLM technologies. Feel free to consult about:
- Not knowing where to start with AI agent development and implementation
- Facing technical challenges in integrating AI into existing systems
- Wanting to consult on architecture design to maximize ROI
- Needing training to improve AI skills across the team
Reserve Free Consultation (30 minutes) →
No pushy sales at all. We start with understanding your challenges.
📖 Related Articles You Might Like
Here are related articles to deepen your understanding of this topic:
1. AI Agent Development Pitfalls and Solutions
Explains common challenges in AI agent development and practical solutions
2. Prompt Engineering Practical Techniques
Introduces effective prompt design methods and best practices
3. Complete Guide to LLM Development Bottlenecks
Detailed explanation of common problems in LLM development and their solutions
![Green AI Practice Guide - Sustainable AI Development Balancing Energy Efficiency and Cost Reduction [2025 Edition]](/images/posts/green-ai-practice-guide-2025-header.webp)



