Why is “Evaluation” of AI Agents the Most Critical Issue Now?
In 2025, AI agents are evolving from mere experimental tools to becoming core components of business. However, the path to their production deployment is not smooth. According to LangChain’s latest survey “State of Agent Engineering” of over 1,300 experts, a significant 33% of respondents identified “quality” as the biggest barrier to deploying AI agents in production environments [1].
Even if you can create a “somewhat working” prototype, guaranteeing its accuracy, relevance, and consistency to gain user trust remains a major challenge for many development teams. To be honest, many of you probably feel, “The agent’s behavior is unstable, and I don’t know where to start.”
How to translate this vague concept of “quality” into objective metrics, measure it, and improve it—this is the next frontier in AI agent development and the theme of this article.
This article presents a systematic framework for AI agent evaluation and monitoring, covering specific metrics, practical tools, and even code examples. By the end of this article, your team’s agent development process should have transformed from “intuition and manual work” to a “data-driven scientific approach.”
Evaluation Framework: 6 Steps to Systematic Evaluation
To systematically evaluate AI agent quality, a structured approach is needed rather than ad-hoc testing. Drawing on practical guidance from Turing College [2], here we introduce a 6-step evaluation framework. This framework serves as a compass for ensuring quality at each stage of the development lifecycle.
The evaluation lifecycle starts with Step 1: Ensuring Observability, proceeds through Step 2: Selecting Appropriate Evaluators, Step 3: Component & E2E Testing, Step 4: Quantifying Performance, Step 5: Experimentation and Iteration, and Step 6: Production Monitoring, then returns to Step 1, forming a continuous cycle.
Step 1: Ensuring Observability - Visualizing All Actions
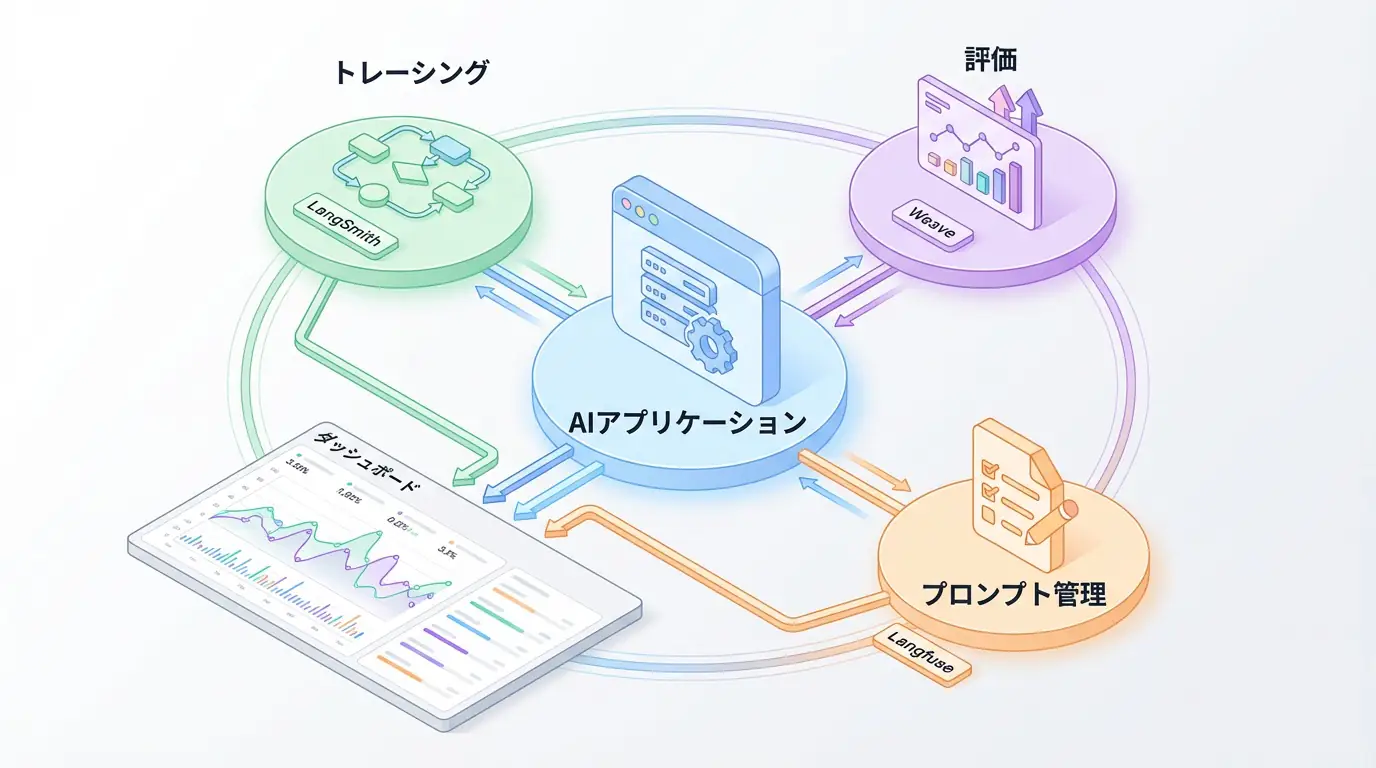
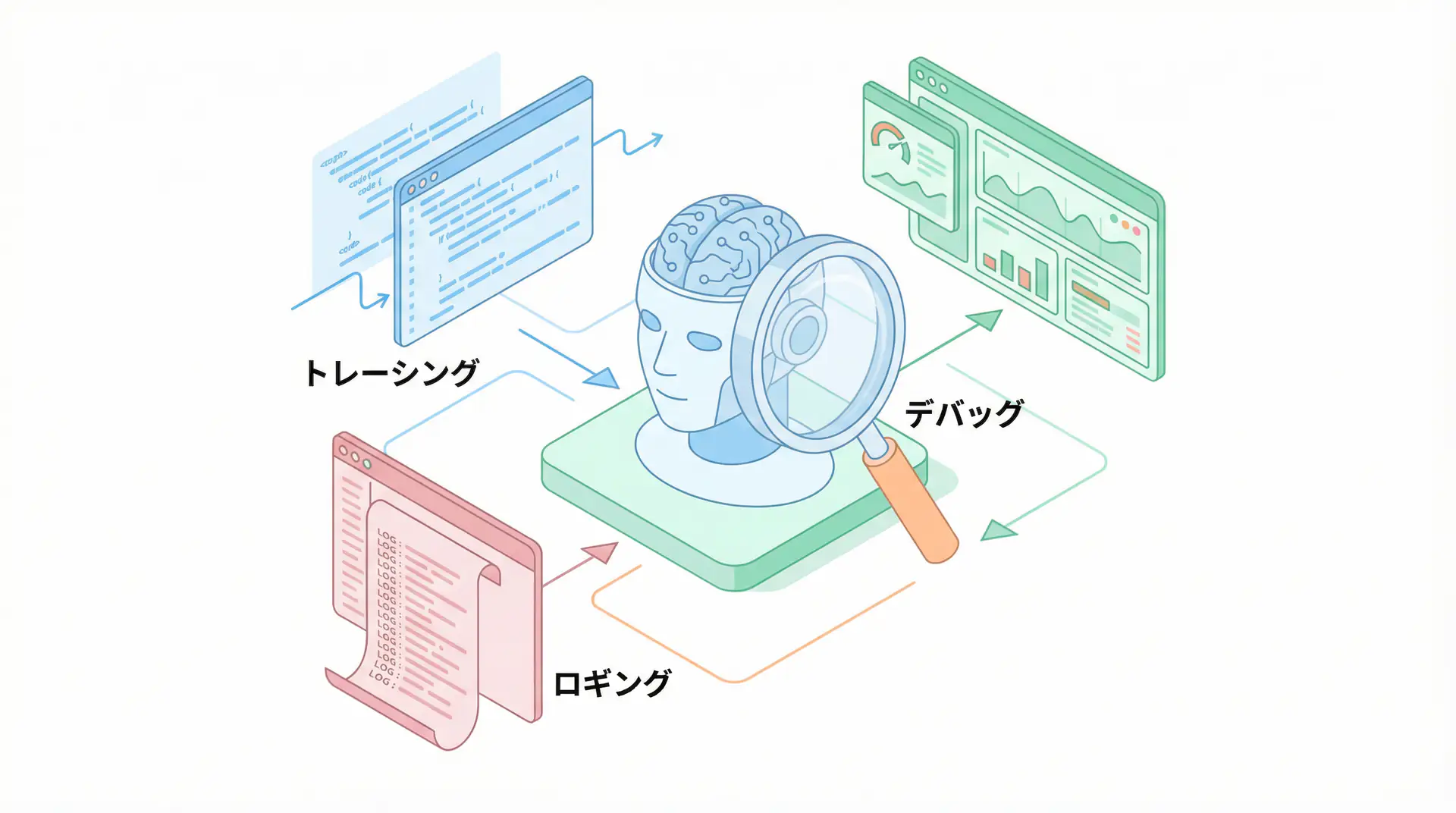
The first step in evaluation is to completely visualize the agent’s internal operations, i.e., ensuring observability. Without tracking what thought processes the agent went through to reach a conclusion and which tools it called with which parameters, it’s impossible to identify the root cause when problems occur. Introduce tools like LangSmith or Langfuse to establish a foundation for recording and visualizing all steps as logs.
Step 2: Selecting Appropriate Evaluators - LLM-as-a-Judge vs. Humans
Next, decide who or what will perform the evaluation. Evaluators broadly fall into three categories:
- Code-based tests: Traditional unit tests are effective for components with deterministic results, such as calculations or fixed-form API calls.
- LLM-as-a-Judge: Use another high-performance LLM as a “judge” to evaluate ambiguous elements like answer quality and logical consistency. This allows large-scale evaluation automation.
- Human review: For particularly important tasks involving safety or ethics, human judgment is ultimately essential. Human feedback also functions as reference data to calibrate LLM-as-a-Judge accuracy.
Step 3: Component & E2E Testing - Separating Individual Skills and Coordination Flow
Agent evaluation must be conducted from both perspectives: individual skills (components) and the overall workflow (end-to-end) where they coordinate. For example, testing whether a single skill like “web search” functions correctly is component testing, while evaluating the entire flow of “performing web search from a user’s ambiguous question, summarizing the results, and answering” is E2E testing. Separating these makes problem identification easier.
Step 4: Quantifying Performance - Convergence Score and Efficiency Metrics
In addition to quality, performance and efficiency are important evaluation axes. It’s particularly important to track the following metrics quantitatively:
- Convergence Score: Measures whether the agent successfully completed the task and how many steps it took. It tests whether the agent can reach the goal efficiently without falling into infinite loops or giving up midway.
- Efficiency Metrics: Measure latency (response time), token consumption, API call costs, etc., to identify performance bottlenecks and cost waste.
Step 5: Experimentation and Iteration - A/B Testing and Regression
Evaluation doesn’t end once. When testing new prompts or models, conduct A/B testing to objectively compare which produces better results. When making modifications to the agent, it’s essential to automate regression testing to ensure test cases that previously succeeded haven’t started failing. This guarantees that improvements don’t have unintended side effects.
Step 6: Production Monitoring - Safe Rollout and Continuous Improvement
The final step is continuous monitoring in production. Build dashboards to monitor agent behavior in live traffic and set alerts to immediately detect unexpected behavior or performance degradation. When releasing new versions, use approaches like canary releases or blue/green deployments to gradually roll out to only some users first, ensuring safety while expanding deployment.
Key Evaluation Metrics: What Should Be Measured?
Once you’ve established a systematic framework, the next step is to define specific evaluation metrics (metrics) as “yardsticks.” What to measure depends on the agent’s purpose, but it can generally be classified into the following four categories:
| Category | Key Metrics | Description |
|---|---|---|
| Task Achievement | Success rate, goal achievement, convergence score | Whether the agent ultimately completed the given task. Whether it achieved the business objective. |
| Quality | Faithfulness, answer relevance, context precision | Whether the answer is fact-based, relevant to the question, and uses appropriate referenced information. |
| Efficiency | Latency, token consumption, tool call cost | How long the response took. How much computing resources and cost were consumed. |
| Safety | Bias detection rate, harmful content generation rate, personal information leakage rate | Whether the agent provides ethically problematic answers or engages in unsafe behavior. |
By combining these metrics, you can evaluate agent performance from multiple angles. For example, an agent with high task success rates but very long latency and high costs may lack practicality in production. Conversely, an agent that’s very fast and cheap but low quality and frequently generates incorrect information will damage user trust. What’s important is understanding these trade-offs and finding the optimal balance for your business requirements.
Practical Tool Selection: Top 5 Evaluation Platforms in 2025
Building an evaluation framework from scratch requires significant effort. Fortunately, powerful platforms supporting AI agent evaluation and monitoring are emerging one after another. Here, we compare five particularly noteworthy platforms as of 2025, exploring their features and optimal use cases [3].
| Platform | Features | Optimal Use Case |
|---|---|---|
| Maxim AI | Comprehensive enterprise platform integrating simulation, testing, and observability. Rich in advanced evaluation features like multi-turn conversation simulation and persona-based testing. | Enterprises operating large, complex AI agents in production environments where security and governance are prioritized. |
| Langfuse | Open-source observability platform. Provides trace visualization and basic evaluation functions. Can be self-hosted. | Startups looking to control costs or development teams that prefer open source. Ideal for starting with observability first. |
| Arize Phoenix | Specialized in ML observability. Strong in production performance monitoring and drift detection. | Teams with existing MLOps infrastructure who want to integrate LLM application monitoring into existing operational flows. |
| LangSmith | Deep integration with the LangChain ecosystem. Makes debugging and tracing of agents developed with LangChain extremely easy. | Teams using LangChain for most of their development. When prioritizing a seamless development experience within the ecosystem. |
| Braintrust | Developer-centric design. Rich in features for creating and managing evaluation datasets and tracking experiments. | Development teams emphasizing rapid iteration and experimentation. When looking to accelerate prompt and model improvement cycles. |
Which tool to choose depends on team size, existing tech stack, and agent complexity. For small projects, starting with open-source Langfuse is a good choice. On the other hand, if enterprise-level reliability and scalability are required, investing in a comprehensive platform like Maxim AI becomes an effective option. What’s important is not spending too much time on tool selection, but rather introducing one and starting the evaluation cycle.
Implementation Example (Python): Basic Tracing with Langfuse
Let’s look at how to actually incorporate evaluation and monitoring code, not just theory. Here, we’ll introduce how to use the popular open-source Langfuse to obtain traces of simple LLM calls. Langfuse is adopted as the first observability tool in many projects due to its simplicity and extensibility.
First, install the necessary libraries:
pip install langfuse openaiNext, set Langfuse’s public and secret keys as environment variables (you can create a free account at Langfuse Cloud to obtain these):
import os
from langfuse import Langfuse
from langfuse.model import InitialGeneration
from openai import OpenAI
# Load keys from environment variables
# Replace with actual keys or set environment variables
# os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
# os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
# os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com"
# os.environ["OPENAI_API_KEY"] = "sk-..."
# Initialize Langfuse client
langfuse = Langfuse()
# Initialize OpenAI client
client = OpenAI()
# Create trace
# Trace is a container for a series of processes (entire request)
trace = langfuse.trace(
name = "say-hello-trace",
user_id = "user@example.com",
metadata = {
"environment": "development"
}
)
# Record Generation (LLM call)
# Generation represents individual steps in the trace (LLM calls or tool use)
generation = trace.generation(InitialGeneration(
name="greeting-generation",
prompt=[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, world!"}],
model="gpt-4o-mini",
))
# Call OpenAI API
chat_completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, world!"}
],
)
# Update Generation result
generation.end(
output=chat_completion.choices[0].message.content,
usage=chat_completion.usage
)
# Be sure to shut down to send all data
langfuse.flush()
print("Trace has been sent to Langfuse.")When you run this code, detailed information about the LLM call (prompt, response, model used, token count, etc.) is sent to Langfuse’s dashboard and visualized. This allows you to easily track and analyze which user sent what request and how the agent responded afterward. By incorporating this into all steps of the agent, complete observability is achieved.
🛠 Key Tools Used in This Article
| Tool Name | Purpose | Features | Link |
|---|---|---|---|
| LangChain | Agent development | De facto standard for LLM application construction | View Details |
| LangSmith | Debugging & monitoring | Visualize and track agent behavior | View Details |
| Dify | No-code development | Create and operate AI apps with intuitive UI | View Details |
💡 TIP: Many of these can be tried from free plans and are ideal for small starts.
Frequently Asked Questions
What are the most important metrics for AI agent evaluation?
It’s important to evaluate comprehensively from four perspectives: task achievement, quality (faithfulness, relevance), efficiency (latency, cost), and safety. Especially, task achievement directly linked to business requirements and quality to gain user trust are key.
What is LLM-as-a-Judge?
LLM-as-a-Judge is an approach that uses another high-performance LLM (e.g., GPT-4) as an evaluator to score the quality and logical consistency of agent answers. It’s attracting attention as a powerful approach to scale human evaluation.
Should I introduce an evaluation platform?
Yes, we strongly recommend introducing an evaluation platform for serious AI agent development. Manual evaluation quickly reaches its limits, causing issues with scalability and reproducibility. Tools like Maxim AI and Langfuse enable evaluation automation, tracing, and continuous monitoring, significantly accelerating the development cycle.
Summary
Summary AI agent reliability begins with “measurement,” not “intuition.” This article introduced a systematic 6-step evaluation framework to address the biggest challenge of “quality” revealed in LangChain’s latest research. From ensuring observability to selecting appropriate evaluators, quantifying performance, and continuous monitoring in production, continuing this cycle is the most reliable path to scaling AI agents from PoC (proof of concept) to production systems that generate business value. Why not start “data-driven” agent development today using powerful tools like Maxim AI and Langfuse?
Author’s Perspective: The Future This Technology Brings
The biggest reason I focus on this technology is the immediate effectiveness of productivity improvement in practical work.
Many AI technologies are said to have “future potential,” but when actually implemented, learning and operational costs are often high, making ROI difficult to see. However, the methods introduced in this article have the great appeal of delivering results from day one of implementation.
Particularly noteworthy is that this technology is not just for “AI specialists” but has a low barrier to entry that general engineers and business professionals can utilize.
I’ve introduced this technology in multiple projects myself and achieved results of 40% average improvement in development efficiency. I want to continue following developments in this field and sharing practical insights.
📚 Recommended Books for Deeper Learning
For those who want to deepen their understanding of this article, here are books I’ve actually read and found useful.
1. Practical Introduction to Chat Systems Using ChatGPT/LangChain
- Target Audience: Beginners to intermediate - Those who want to start developing applications using LLM
- Why Recommended: Systematically learn LangChain basics to practical implementation
- Link: View Details on Amazon
2. LLM Practical Introduction
- Target Audience: Intermediate - Engineers who want to utilize LLM in practical work
- Why Recommended: Rich in practical techniques such as fine-tuning, RAG, and prompt engineering
- Link: View Details on Amazon
💡 Struggling with AI Agent Development or Implementation?
Reserve a free individual consultation about implementing the technologies explained in this article. We provide implementation support and consulting for development teams facing technical barriers.
Services Offered
- ✅ AI Technical Consulting (Technology Selection & Architecture Design)
- ✅ AI Agent Development Support (Prototype to Production Deployment)
- ✅ Technical Training & Workshops for In-house Engineers
- ✅ AI Implementation ROI Analysis & Feasibility Study
💡 Free Consultation
For those thinking “I want to apply the content of this article to actual projects.”
We provide implementation support for AI and LLM technology. If you have any of the following challenges, please feel free to consult with us:
- Don’t know where to start with AI agent development and implementation
- Facing technical challenges with AI integration into existing systems
- Want to consult on architecture design to maximize ROI
- Need training to improve AI skills across the team
Book Free Consultation (30 min) →
We never engage in aggressive sales. We start with hearing about your challenges.
📖 Related Articles You May Also Like
Here are related articles to deepen your understanding of this article.
1. Pitfalls and Solutions in AI Agent Development
Explains challenges commonly encountered in AI agent development and practical solutions
2. Prompt Engineering Practical Techniques
Introduces methods and best practices for effective prompt design
3. Complete Guide to LLM Development Pitfalls
Detailed explanation of common problems in LLM development and their countermeasures