I’ve been working on LLM-based system development for a long time, and recently I’ve been strongly feeling the limitations of “search-only RAG.” For simple fact-checking questions (“What’s the definition of X?”), traditional Retrieval-Augmented Generation (RAG) is sufficient. It uses vector search to pull up relevant documents and feeds them to the LLM along with context. This simple mechanism works well in many situations.
However, questions in real business scenarios are more complex. Tasks that require crossing multiple information sources and involve calculation or reasoning are increasing, such as “Compare company A and B’s sales last year and suggest next year’s strategy based on market trends.” When trying to handle this with traditional RAG, search queries become too ambiguous, resulting in poor accuracy, or a single search provides insufficient information, leading to “I don’t know” answers.
This is where Agentic RAG comes in, giving LLMs the role of “autonomous agents.” This is not just a search tool, but a groundbreaking technology that breaks down tasks and derives answers by repeatedly executing necessary actions. In this article, I want to explore the potential of Agentic RAG, including its mechanism and working Python code.
Structural Differences Between Traditional RAG and Agentic RAG
First, let’s clarify why this technology is needed now and how it differs from existing methods.
Traditional RAG (Retrieval-Augmented Generation) is like “finding materials in a library.” When a user asks a question, the system finds relevant books (documents) based on keywords or semantic similarity and reads their contents. It’s very efficient, but the librarian doesn’t judge that “To answer this question, I need to combine content from this book and that book” and summarize while going back and forth between multiple books.
On the other hand, Agentic RAG is an “excellent assistant.” When it receives a question, it first plans “What do I need to answer this question?” Depending on the case, it may perform web searches, check internal databases, and use calculation tools if necessary. This series of actions is called the ReAct (Reasoning + Acting) pattern.
Here are the specific differences:
- Traditional RAG: Static, one-time search. Optimizing search queries is difficult.
- Agentic RAG: Dynamic, iterative process. By looping through search, generation, and evaluation, it can gradually collect and complement necessary information.
This autonomous loop processing is the key that enables complex reasoning tasks.
Internal Operation and Mechanism of Agentic RAG
Let’s dig a little deeper into the inside of Agentic RAG. Its core is making the LLM function as an “orchestra conductor.”
The system is broadly composed of Planner, Tools, and Executor elements.
- Thinking and Planning: In response to the user’s question, the LLM first sets a goal. For example, for a task like “Create a Q4 sales report,” it breaks it down into steps like “First get sales data, then calculate year-over-year comparisons, and finally summarize.”
- Tool Selection and Execution: Next, it selects the optimal tools to execute each step. Tools include “vector search,” “web search,” “SQL query,” “Python code execution,” and more. The LLM issues instructions to tools in natural language, and the tools return execution results.
- Observation and Reconsideration: Upon receiving the tool’s execution results (observation), the LLM judges whether it’s sufficient information. If not, it modifies the search query and calls the tool again or uses a different tool.
- Final Answer: When it judges that sufficient information has been gathered, the LLM integrates the collected information and generates a final answer for the user.
Diagramming this process would look like the following flow:
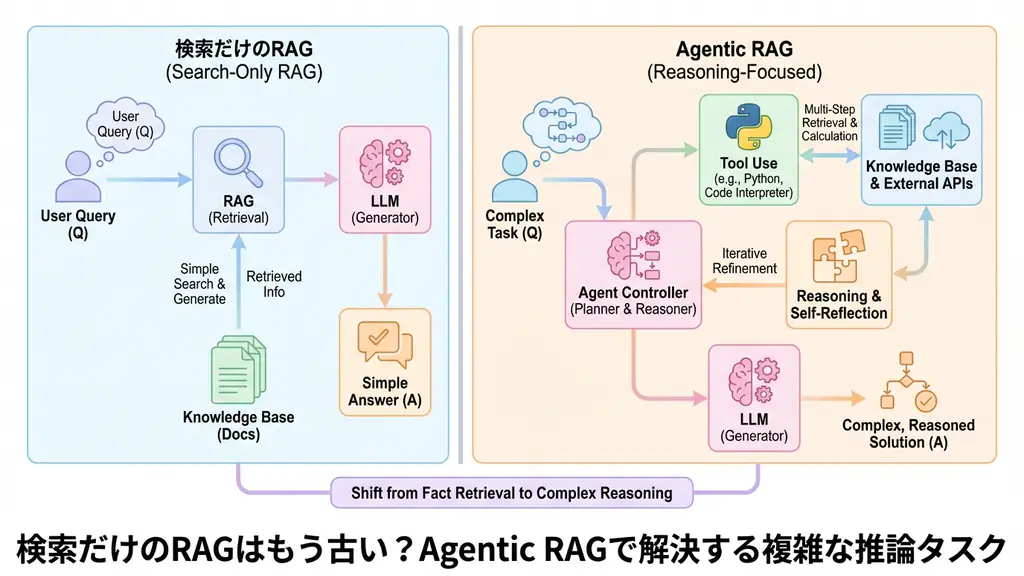
By going through this loop, it becomes possible to extract “hidden answers” and “integrated insights” that couldn’t be found through simple search alone.
Python Implementation Example: Research Agent Across Multiple Data Sources
Now let’s look at working code. Here we’ll implement a simple Agentic RAG using OpenAI’s API that uses both internal documents (simulated) and web search (simulated).
This is not pseudocode, but a practical configuration including error handling and logging.
import logging
import json
from typing import List, Dict, Any, Optional
from openai import OpenAI
import time
# Logging configuration
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class AgenticRAG:
def __init__(self, api_key: str):
self.client = OpenAI(api_key=api_key)
self.tools = self._define_tools()
def _define_tools(self) -> List[Dict[str, Any]]:
"""Define tools available to the agent"""
return [
{
"type": "function",
"function": {
"name": "search_internal_knowledge_base",
"description": "Search internal technical documents and manuals. Use for questions about product specifications and internal procedures.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Search keywords"
}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "search_web",
"description": "Search for latest information on the internet. Use for market trends, latest news, and external technical information.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Search keywords"
}
},
"required": ["query"]
}
}
}
]
def _execute_tool(self, tool_name: str, arguments: Dict[str, Any]) -> str:
"""Tool execution logic (mock implementation)"""
logger.info(f"Executing tool: {tool_name} with arguments: {arguments}")
try:
if tool_name == "search_internal_knowledge_base":
# In reality, this would query a vector DB, etc.
query = arguments.get("query", "")
if "API" in query:
return "According to internal API documentation, the endpoint is /api/v1/resource and requires a Bearer token for authentication."
else:
return "No relevant internal documents found."
elif tool_name == "search_web":
# In reality, this would use Google Search API, Bing API, etc.
query = arguments.get("query", "")
if "Python" in query:
return "According to the latest information on Python 3.12, performance improvements and error message enhancements have been made."
else:
return "No relevant latest information found on the web."
else:
return f"Unknown tool called: {tool_name}"
except Exception as e:
logger.error(f"Tool execution error: {e}")
return f"An error occurred: {str(e)}"
def run(self, user_query: str, max_turns: int = 5) -> str:
"""Agentic RAG main loop"""
messages = [
{"role": "system", "content": "You are a helpful AI assistant. Use the available tools to answer the user's question."},
{"role": "user", "content": user_query}
]
for turn in range(max_turns):
logger.info(f"--- Turn {turn + 1} ---")
try:
# LLM response generation (including tool call judgment)
response = self.client.chat.completions.create(
model="gpt-4o", # or available model
messages=messages,
tools=self.tools,
tool_choice="auto" # let the model automatically decide whether to use tools
)
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
# If no tool calls, consider it the final answer
if not tool_calls:
logger.info("Final answer generated.")
return response_message.content
# Process tool call results
messages.append(response_message) # add model's tool call request to history
for tool_call in tool_calls:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments)
# Execute tool
function_response = self._execute_tool(function_name, function_args)
# Add execution result to history
messages.append(
{
"tool_call_id": tool_call.id,
"role": "tool",
"name": function_name,
"content": function_response,
}
)
except Exception as e:
logger.error(f"Exception during LLM inference: {e}")
messages.append({
"role": "system",
"content": f"An error occurred in the previous process. Error content: {str(e)}. Please try a different approach."
})
return "Maximum number of turns reached, but could not derive an answer."
# Execution example
if __name__ == "__main__":
# Get API key from environment variables, etc.
import os
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
print("OPENAI_API_KEY is not set.")
else:
agent = AgenticRAG(api_key=api_key)
# Complex question: case requiring both internal and external information
query = "After checking our company's API specifications, please tell me the points to note when implementing it in the latest version of Python."
answer = agent.run(query)
print(f"\nFinal answer:\n{answer}")In this code, the run method loops up to max_turns. If the LLM judges that “internal API specifications” are needed, it calls search_internal_knowledge_base, and if it needs “latest Python information,” it calls search_web. You can see how it approaches the answer by combining multiple tools for a single question.
Business Use Case: Enhancing Customer Support Automation
Agentic RAG technology is particularly effective in the customer support domain. Let’s introduce a specific use case.
Case: Complex Billing Troubleshooting for a Telecommunications Carrier
Traditional chatbots only displayed search results from FAQs. For example, in response to a “high bill” inquiry, they would guide users to a page on “How to check billing details.” But users want to know “why it’s high.”
With Agentic RAG, the following response becomes possible:
- User Authentication and Data Retrieval: First, identify the user and access the billing system (API) to get this month’s call detail data.
- Data Analysis: Analyze the obtained detail data using a Python tool to check month-over-month increases and subscription status for specific paid services.
- External Factor Verification: If international call charges are high, supplement with web search information on the latest exchange rates and international roaming rate revisions.
- Answer Generation: Generate a specific, evidence-based explanation like “You used international roaming during your overseas trip last month, resulting in ¥XX in communication charges in addition to the basic fee. Details are as follows…”
This allows automation of “cause investigation and suggestions based on individual situations” that was impossible with simple search, significantly reducing the burden on customer support staff and improving customer satisfaction.
Frequently Asked Questions
- Q: What is the biggest difference between traditional RAG and Agentic RAG? A: Traditional RAG is a one-time “search→generate” process, while Agentic RAG is an iterative process where the LLM plans tasks, repeatedly calls necessary tools to collect and integrate information, and derives answers.
- Q: What about costs and latency when implementing Agentic RAG? A: Since the number of LLM inference calls increases, token costs and response times tend to be higher than traditional RAG. However, the dramatic improvement in answer accuracy for complex queries often justifies this from the perspective of overall business efficiency and customer satisfaction.
- Q: What frameworks should I use for implementation? A: Major libraries like LangChain and LlamaIndex support Agentic RAG functionality, but if you need more detailed control, it’s recommended to build your own loop using OpenAI’s Function Calling feature directly, as in this implementation example.
- Q: Doesn’t the risk of hallucinations (lying) increase? A: Since it answers based on tool execution results, the risk of the LLM fabricating facts on its own is reduced. However, tool selection mistakes and misinterpretation of results can occur, so it’s important to provide guardrails (fact-checking logic, etc.) for the final output.
Summary
- Limitations of Traditional RAG: A single search makes it difficult to integrate multiple information sources or perform multi-step reasoning.
- Definition of Agentic RAG: A mechanism where LMs solve complex tasks by going through planning→execution→observation loops and autonomously using tools.
- Implementation Points: Using OpenAI’s Function Calling and properly handling error handling and loop control are essential for stable operation.
- Business Impact: In tasks requiring advanced judgment, such as customer support and market analysis, it can automate flexible responses close to human-level.
Recommended Resources
- LangChain A comprehensive framework for LLM application development. The Agents feature greatly simplifies building Agentic RAG.
- LlamaIndex A library specialized for data connection. It provides advanced index management functionality, especially for the fusion of RAG and agents.
AI Implementation Support & Development Consultation
Are you having trouble implementing Agentic RAG or developing custom agents using LLMs? We provide comprehensive support from technology selection to design, implementation, and operation maintenance. We’ll propose the optimal AI solution for your business challenges, so feel free to contact us.
References
[1]OpenAI Function Calling Documentation [2]ReAct: Synergizing Reasoning and Acting in Language Models [3]LangGraph: Building Cyclic Agents






